Java基础部分3
数组
数组概述
①什么是数组?
1.在Java中,数组是一种用于存储多个相同数据类型元素的容器。
2.例如一个存储整数的数组:int[] nums = {100, 200, 300};
3.例如一个存储字符串的数组:String[] names = {“jack”,“lucy”,“lisi”};
4.数组是一种引用数据类型,隐式继承Object。因此数组也可以调用Object类中的方法。
5.数组对象存储在堆内存中。
②数组的分类?
1.根据维数进行分类:一维数组,二维数组,三维数组,多维数组。
2.根据数组中存储的元素类型分类:基本类型数组,引用类型数组。
3.根据数组初始化方式不同分类:静态数组,动态数组。
③Java数组存储元素的特点?
1.数组长度一旦确定不可变。
2.数组中元素数据类型一致,每个元素占用空间大小相同。
3.数组中每个元素在空间存储上,内存地址是连续的。
4.每个元素有索引,首元素索引0,以1递增。
5.以首元素的内存地址作为数组对象在堆内存中的地址。
6.所有数组对象都有length属性用来获取数组元素个数。末尾元素下标:length-1
①数组优点?
1.根据下标查询某个元素的效率极高。数组中有100个元素和有100万个元素,查询效率相同。时间复杂度O(1)。也就是说在数组中根据下标查询某个元素时,不管数组的长短,耗费时间是固定不变的。
原因:知道首元素内存地址,元素在空间存储上内存地址又是连续的,每个元素占用空间大小相同,只要知道下标,就可以通过数学表达式计算出来要查找元素的内存地址。直接通过内存地址定位元素。
②数组缺点?
1.随机增删元素的效率较低。因为随机增删元素时,为了保证数组中元素的内存地址连续,就需要涉及到后续元素的位移问题。时间复杂度O(n)。O(n)表示的是线性阶,随着问题规模n的不断增大,时间复杂度不断增大,算法的执行效率越低。(不过需要注意的是:对数组末尾元素的增删效率是不受影响的。)
2.无法存储大量数据,因为很难在内存上找到非常大的一块连续的内存。
一维数组
①一维数组是线性结构。二维数组,三维数组,多维数组是非线性结构。
②如何静态初始化一维数组?
1.第一种:int[] arr = {55,67,22}; 或者 int arr[] = {55,67,22};
2.第二种:int[] arr = new int[]{55,67,22};
1 | Animal[] animals = {a1,a2,new Animal()}; |
③如何访问数组中的元素?
1.通过下标来访问。
2.注意ArrayIndexOutOfBoundsException异常的发生。
④如何遍历数组?
1.普通for循环遍历
2.for-each遍历(优点是代码简洁。缺点是没有下标。)
1 | for(int i = 0 ; i < citys.length;i++){ |
⑤如何动态初始化一维数组?
在创建数组的时候,不确定具体存储那些数据,但是确定长度(就是开辟空间)
数据类型[] 变量名 = new 数据类型[长度]
1.int[] arr = new int[4];
2.Object[] objs = new Object[5];
3.数组动态初始化的时候,确定长度,并且数组中每个元素采用默认值。
⑥方法在调用时如何给方法传一个数组对象?
1 | public static void display(int[] arr){ |
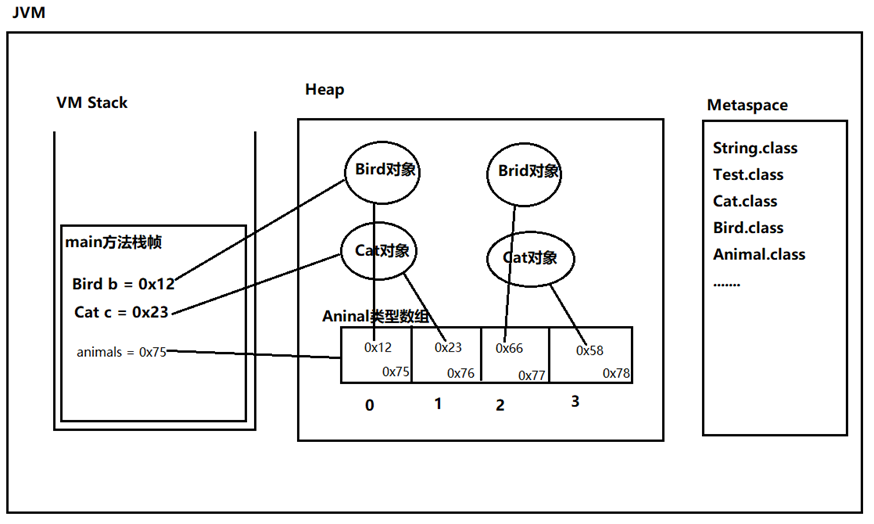
⑦当一维数组中存储引用时的内存图?
1 | Animals[] animals = new Animals[5]; |
数组中存储的每个元素的空间大小都是一样的,所以空间是不可能一样的,所以是不可能存储引用对象的,所以是存储的是引用(对象在堆内存中的地址)
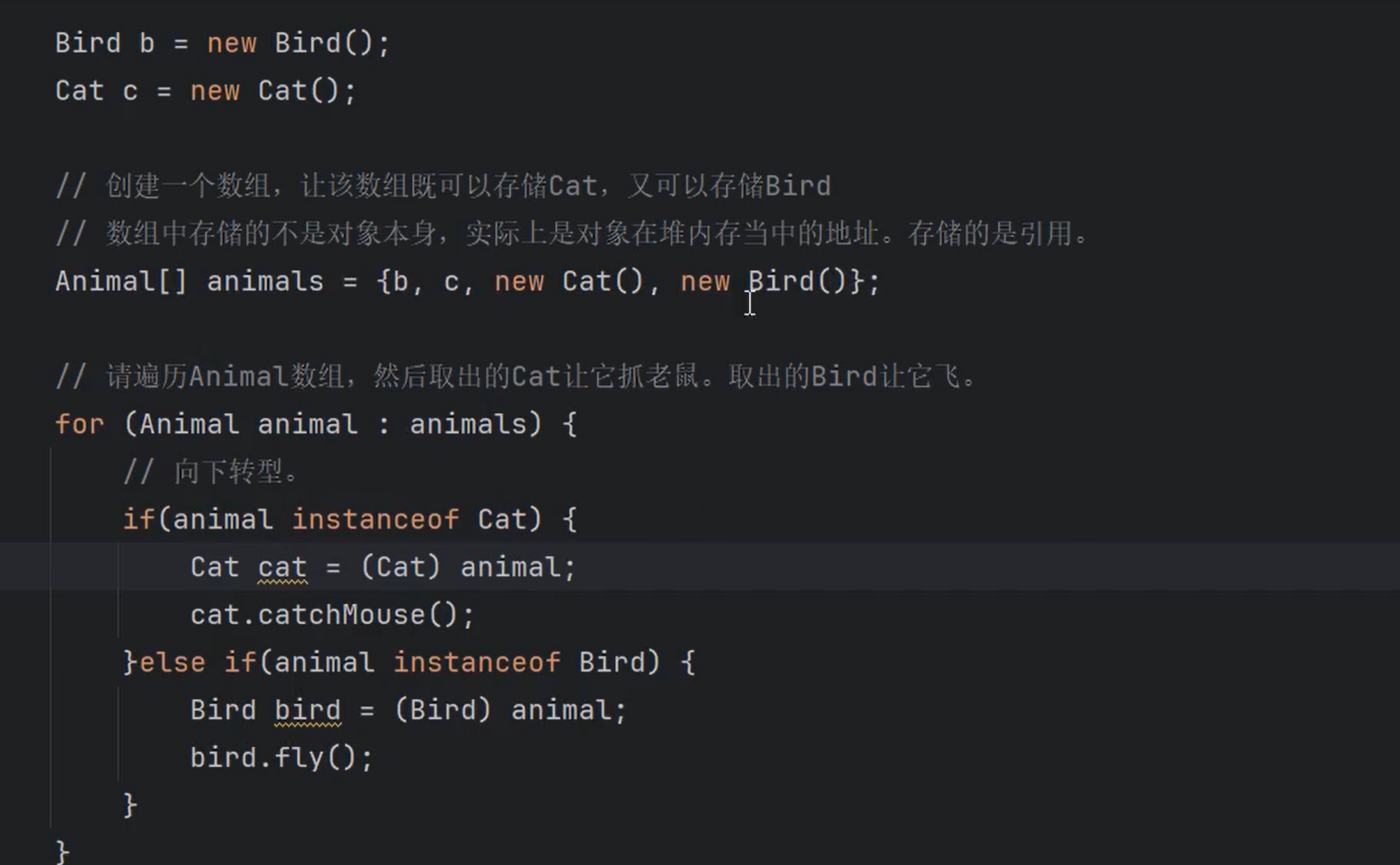
⑧如何获取数组中的最大值?
假设首元素是最大的,然后遍历数组中所有元素,只要有更大的,就将其作为最大值。
思考:找出最大值的下标怎么做?
⑨如果知道值,如何通过值找它的下标?
⑩如何将数组中的所有元素反转?
第一种方式:创建一个新的数组。
就是倒着遍历第一个,然后赋值过去
第二种方式:首尾交换。
就是第一个和倒数第一个交换,以此类推
⑾关于main方法的形参args?
接收命令行参数,
JVM 负责调用这个类名.main()方法的

JVM会把以上字符串以“空格”进行拆分,生成一个新的数组对象
最后这个数组对象是String[] args = {“abc”,”def”,”xyz”}
在DOS命令窗口中怎么传?在IDEA中怎么传?

⑿关于方法的可变长度参数?
可变长参数只能出现在形参列表中的最后一个位置。
可变长参数可以当做数组来处理。
1 | public static void mi(int... nums) |
⒀一维数组的扩容
①数组长度一旦确定不可变。
②那数组应该如何扩容?
==只能创建一个更大的数组将原数组中的数据全部拷贝到新数组中==
==可以使用System.arraycopy()方法完成数组的拷贝。==
1 | System.arraycopy(src,srcpos:0,dest,destpos:0,src.length)//注意越界问题 |
③数组扩容会影响程序的执行效率,因此尽可能预测数据量,创建一个接近数量的数组,减少扩容次数。
二维数组
①二维数组是一个特殊的一维数组,特殊在:这个一维数组中每个元素是一个一维数组(相当于存的还是一个地址,是一维数组的首位地址)。
②二维数组的静态初始化
1 | int[][] arr = new int[][]{{},{},{}}; |
③二维数组的动态初始化(等长)
1 | int[][] arr = new int[2][3]; |
④二维数组的动态初始化(不等长)
1 | int[][] arr = new int[3][]; |
⑤二维数组中元素的访问
1 | 第一个元素:arr[0][0] |
⑥二维数组中元素的遍历
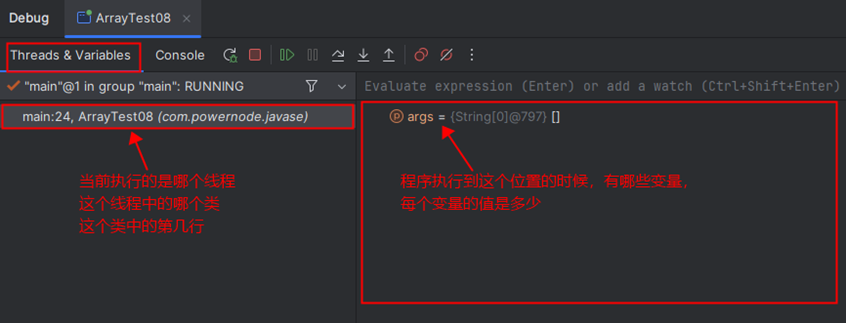
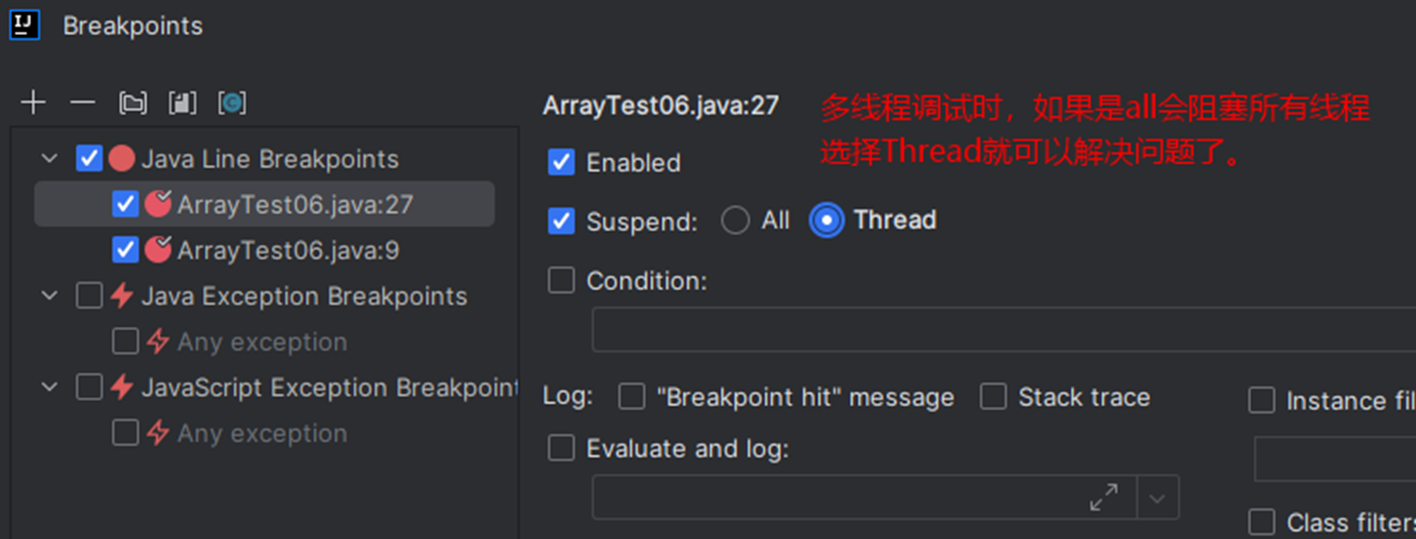
IDEA的Debug
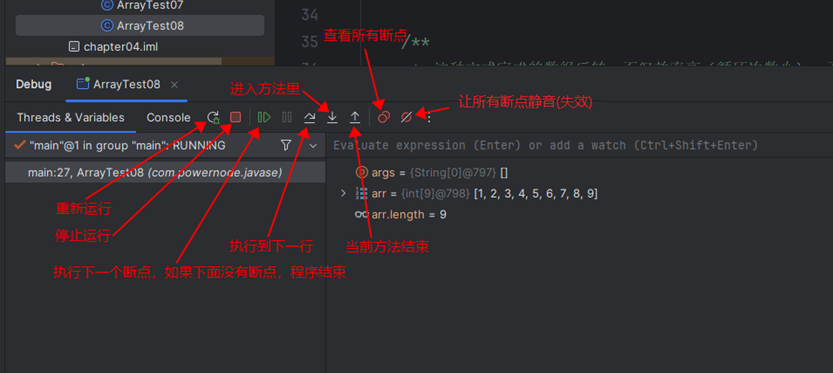
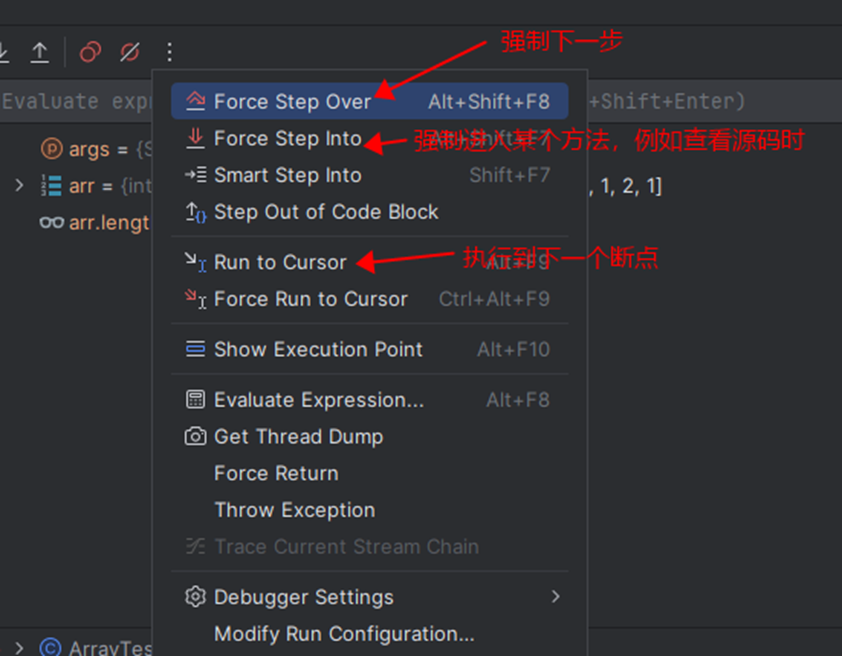
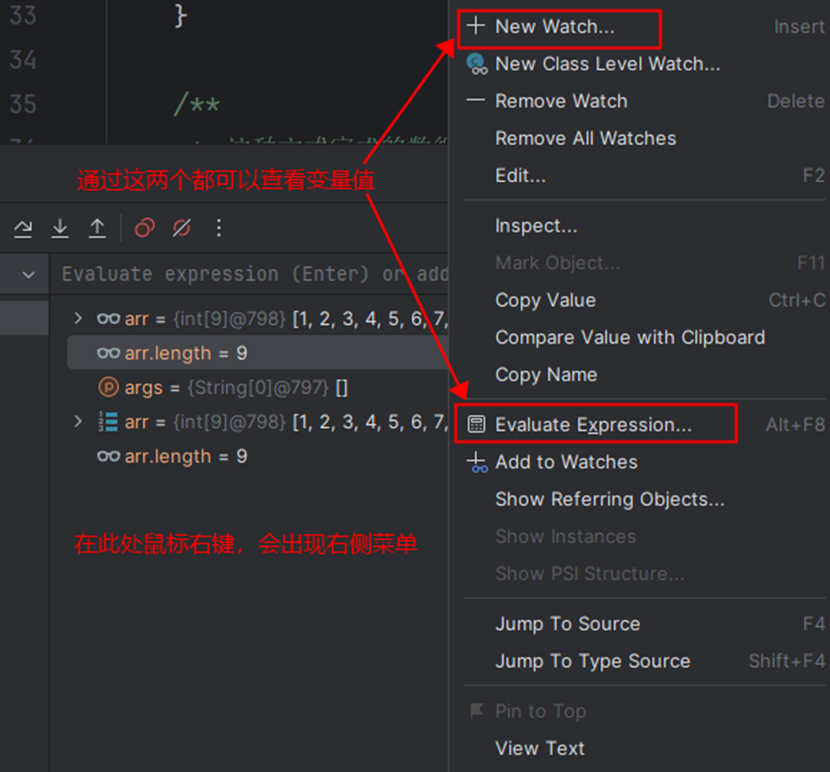
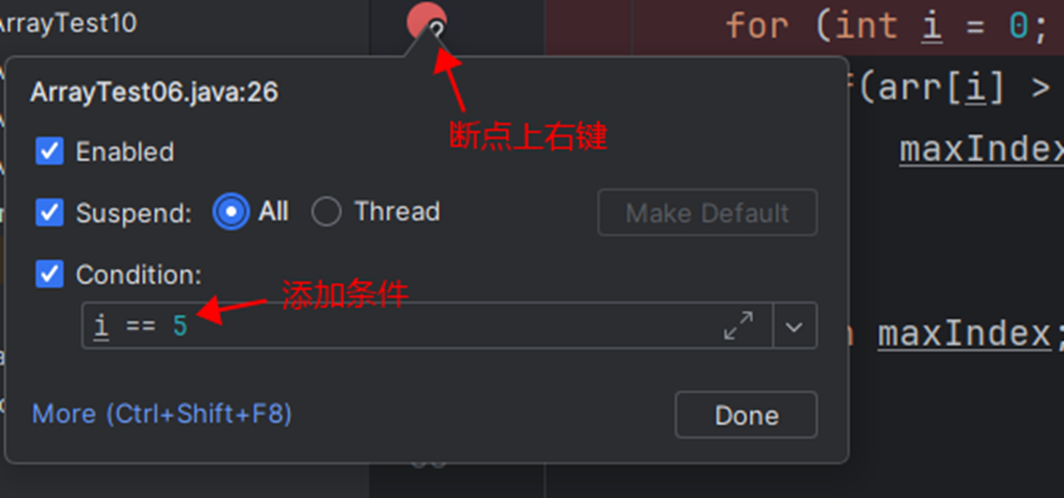
单元测试
①什么是单元测试,为什么要进行单元测试?
1.一个项目是巨大的,只有保证你写的每一块都是正确的,最后整个项目才能正常运行。这里所谓的每一块就是一个单元。
②做单元测试需要引入JUnit框架,JUnit框架在JDK中没有,需要额外引入,也就是引入JUnit框架的class文件(jar包)
step1:文件目录下新建lib文件夹;
step2:将三个jar包复制进去,
step3:全选右键,Add as library
③单元测试类(测试用例)怎么写?
1.单元测试类名:XxxTest
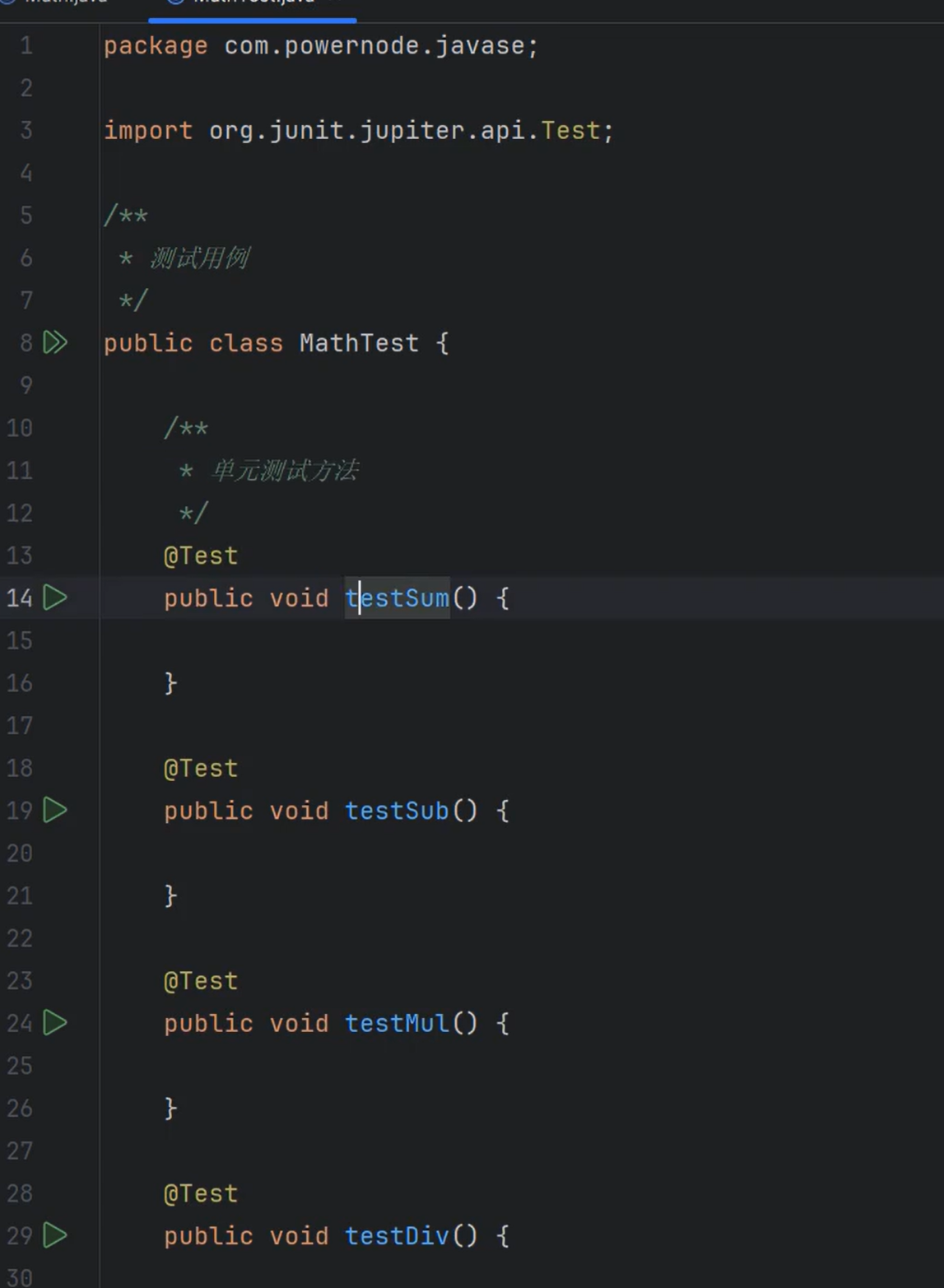
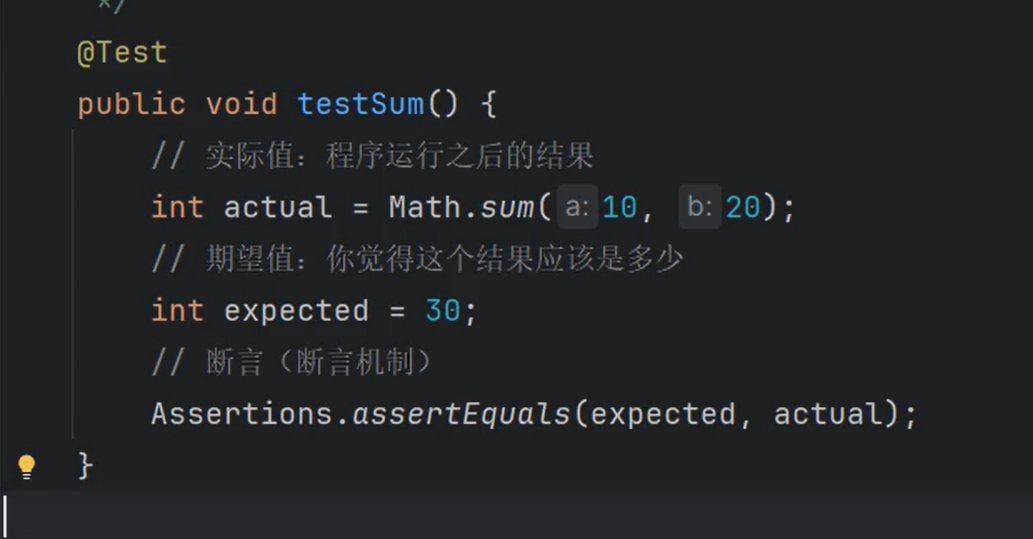
④单元测试方法怎么写?
1.单元测试方法需要使用@Test注解标注。
2.单元测试方法返回值类型必须是void
3.单元测试方法形参个数为0
4.建议单元测试方法名:testXxx
⑤什么是期望值,什么是实际值?
1.期望值就是在程序执行之前,你觉得正确的输出结果应该是多少
2.实际值就是程序在实际运行之后得到的结果
⑥常见注解:
1.@BeforeAll @AfterAll 主要用于在测试开始之前/之后执行必要的代码。被标注的方法需要是静态的。
2.@BeforeEach @AfterEach 主要用于在每个测试方法执行前/后执行必要的代码。
⑦单元测试中使用Scanner失效怎么办?
1.选中导航栏的“Help”,然后选中“Edit Custom VM Options…”,接着在“IDEA64.exe.vmoptions”文件中添加内容“-Deditable.java.test.console=true”,最后在重启IDEA即可解决
数据结构
跳过
Arrays工具类
java.util
1 | Arrays.toString()方法:将数组转换成字符串 |
异常Exception
异常概述
①什么是异常?有什么用?
1.Java中的异常是指程序运行时出现了错误或异常情况,导致程序无法继续正常执行的现象。例如,数组下标越界、空指针异常、类型转换异常等都属于异常情况。
2.Java提供了异常处理机制,即在程序中对可能出现的异常情况进行捕捉和处理。异常机制可以帮助程序员更好地管理程序的错误和异常情况,避免程序崩溃或出现不可预测的行为。
3.没有异常机制的话,程序中就可能会出现一些难以调试和预测的异常行为,可能导致程序崩溃,甚至可能造成数据损失或损害用户利益。因此,异常机制是一项非常重要的功能,是编写可靠程序的基础。
②异常在Java中以类和对象的形式存在。
1.现实生活中也有异常,比如地震,火灾就是异常。也可以提取出类和对象,例如:
1.地震是类:512大地震、唐山大地震就是对象。
2.空指针异常是类:发生在第52行的空指针异常、发生在第100行的空指针异常就是对象。
2.也就是说:在第52行和第100行发生空指针异常的时候,底层一定分别new了一个NullPointerException对象。在程序中异常是如何发生的?
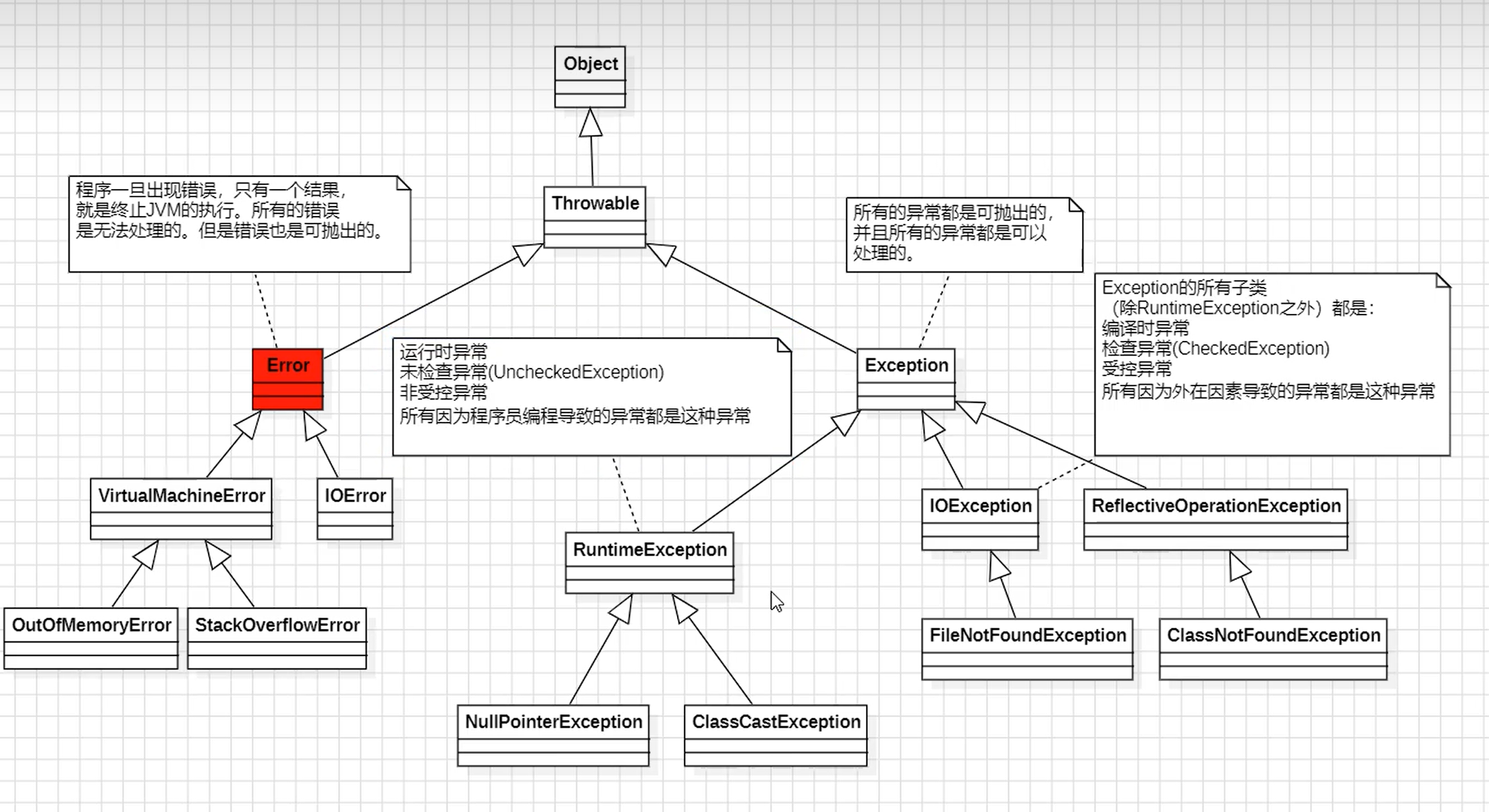
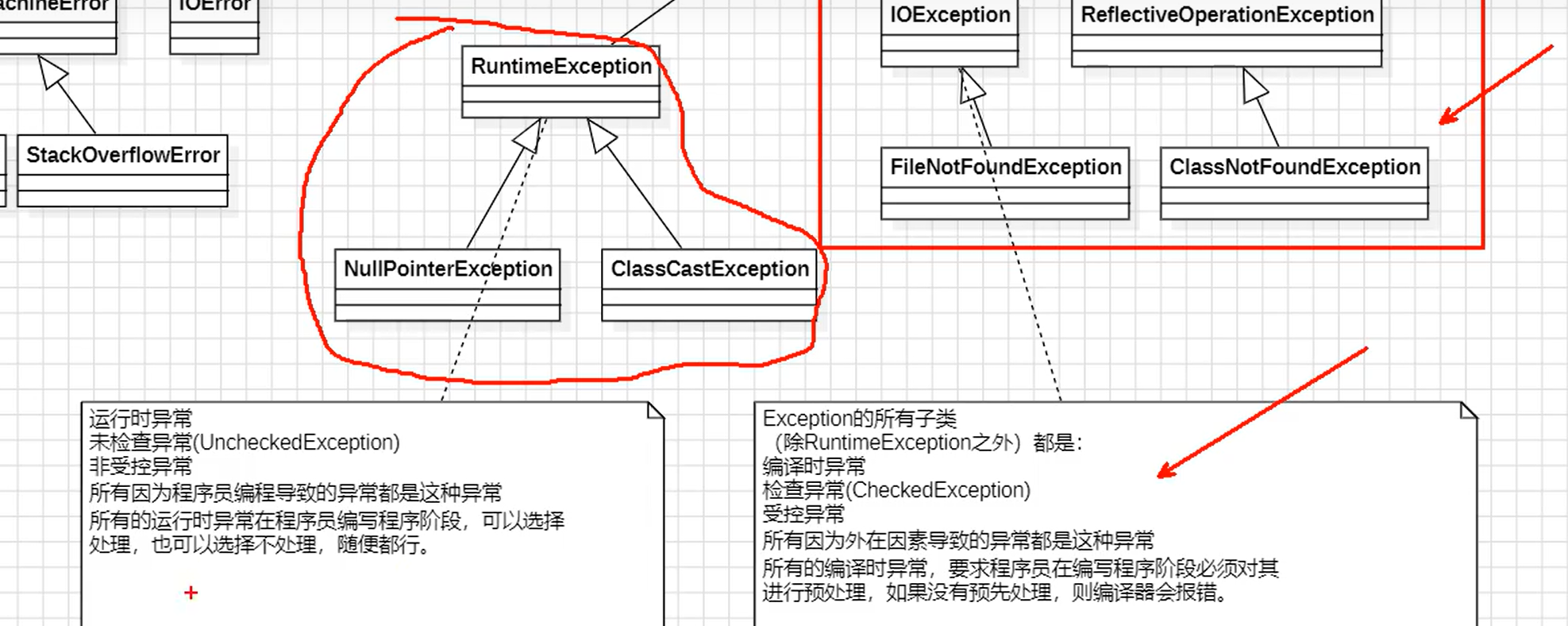
异常继承结构
①所有的异常和错误都是可抛出的。都继承了Throwable类。
②Error是无法处理的,出现后只有一个结果:JVM终止。
③Exception是可以处理的。
④Exception的分类:
1.所有的RuntimeException的子类:运行时异常/未检查异常(UncheckedException)/非受控异常
2.Exception的子类(除RuntimeException之外):编译时异常/检查异常(CheckedException)/受控异常
⑤编译时异常和运行时异常区别:
- 1.编译时异常特点:在编译阶段必须提前处理,如果不处理编译器报错。
- 2.运行时异常特点:在编译阶段可以选择处理,也可以不处理,没有硬性要求。
- 3.编译时异常一般是由外部环境或外在条件引起的,如网络故障、磁盘空间不足、文件找不到等
- 4.运行时异常一般是由程序员的错误引起的,并且不需要强制进行异常处理
注意:编译时异常并不是在编译阶段发生的异常,所有的异常发生都是在运行阶段的,因为每个异常发生都是会new异常对象的,new异常对象只能在运行阶段完成。那为什么叫做编译时异常呢?这是因为这种异常必须在编译阶段提前预处理,如果不处理编译器报错,因此而得名编译时异常。
1 | NullPointerException e = new NullPointerException(); |
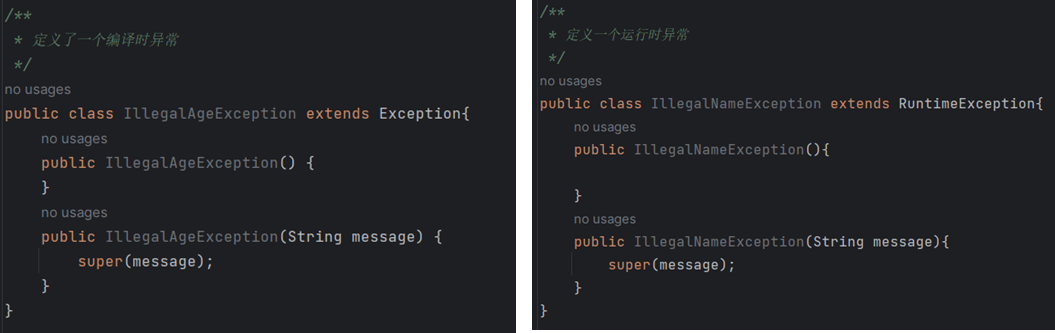
自定义异常
step1:继承Exception(编译时异常)/RuntimeException
step2: 提供一个无参数构造方法,再提供一个带String msg参数的构造方法,在构造方法中调用父类的构造方法。
异常的处理包括两种方式:
1.声明异常:类似于推卸责任的处理方式
在方法定义时使用throws关键字声明异常,**==告知调用者,调用这个方法可能会出现异常==**。这种处理方式的态度是:如果出现了异常则会抛给调用者来处理。
如果一个异常发生后希望调用者来处理的,使用声明异常(俗话说:交给上级处理)
==注意这里是throws,然后在后面需要throw e的时候是没有s的==
1 | public void m() throws AException, BException... {} |
如果Exception和Exception都继承了Exception,那么也可以这样写:
1 | public void m() throws XException{} |
==调用者在调用m()方法时,编译器会检测到该方法上用throws声明了异常,表示可能会抛出异常,编译器会继续检测该异常是否为编译时异常,如果为编译时异常则必须在编译阶段进行处理,如果不处理编译器就会报错。==
如果所有位置都采用throws,包括main方法的处理态度也是throws,如果运行时出现了异常,最终异常是抛给了main方法的调用者(JVM),JVM则会终止程序的执行。==因此为了保证程序在出现异常后不被中断,至少main方法不要再使用throws进行声明了。==
发生异常后,在发生异常的位置上,往下的代码是不会执行的,除非进行了异常的捕捉。
2.捕捉异常:真正的处理捕捉异常(真正的处理异常 (try…catch…关键字))
在可能出现异常的代码上使用try..catch进行捕捉处理。这种处理方式的态度是:把异常抓住。其它方法如果调用这个方法,对于调用者来说是不知道这个异常发生的。因为这个异常被抓住并处理掉了。
如果一个异常发生后,不需要调用者知道,也不需要调用者来处理,选择使用捕捉方式处理。
1 | try{ |
catch可以写多个。并且遵循自上而下,从小到大。
因为,如果最大的在上面,后面的小的异常都不会抛出了,就会导致异常抛出的不够精确
异常在处理的整个过程中应该是:声明和捕捉联合使用。
什么时候捕捉?什么时候声明?
如果**==异常发生后需要调用者来处理的,需要调用者知道的,则采用声明方式。==**否则采用捕捉。
异常的常用方法
获取异常的简单描述信息:
1 | exception.getMessage(); |
获取的message是通过构造方法创建异常对象时传递过去的message。
打印异常堆栈信息:
1 | exception.printStackTrace(); |
要会看异常的堆栈信息:
异常信息的打印是符合栈数据结构的。
看异常信息主要看最开始的描述信息。看栈顶信息。

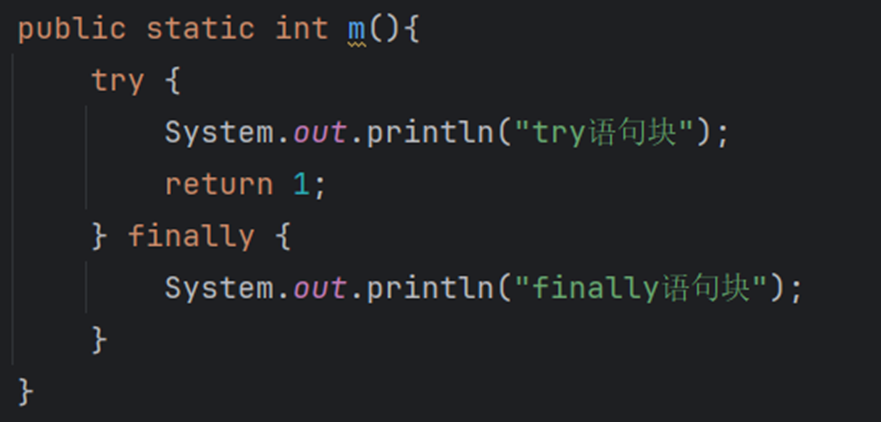
finally语句块
finally语句块中的代码是一定会执行的。
finally语句块不能单独使用,至少需要配合try语句块一起使用:
1 | try...finally |
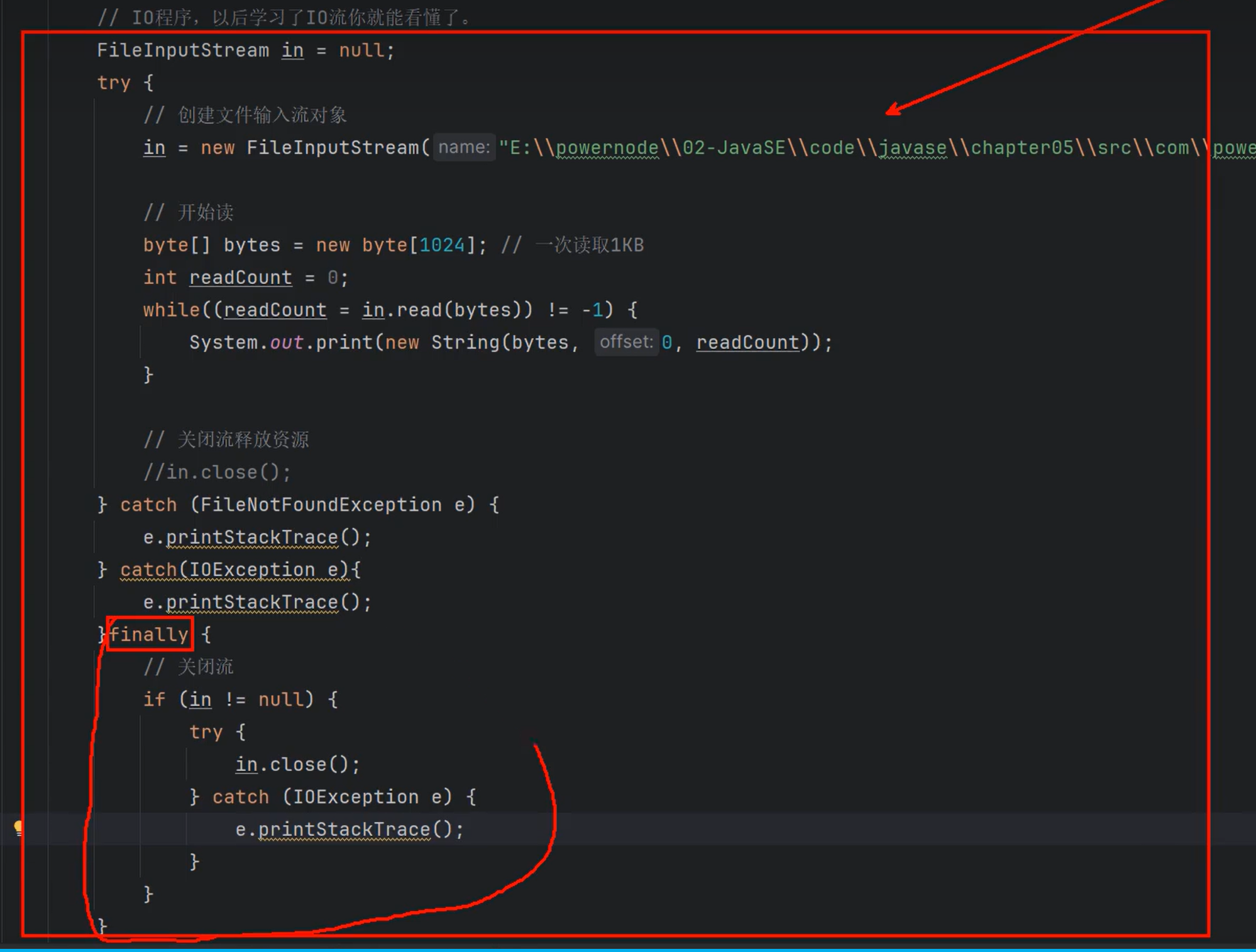
通常在finally语句块中完成资源的释放
资源释放的工作比较重要,如果资源没有释放会一直占用内存。
为了保证资源的关闭,也就是说:不管程序是否出现异常,关闭资源的代码一定要保证执行。
因此在finally语句块中通常进行资源的释放。
final、finally、finalize分别是什么?
final是一个关键字,修饰的类无法继承,修饰的方法无法覆盖,修饰的变量不能修改。
finally是一个关键字,和try一起使用,finally语句块中的代码一定会执行。\
finalize是一个标识符,它是Object类中的一个方法名。
innotnull
面试经典题
1.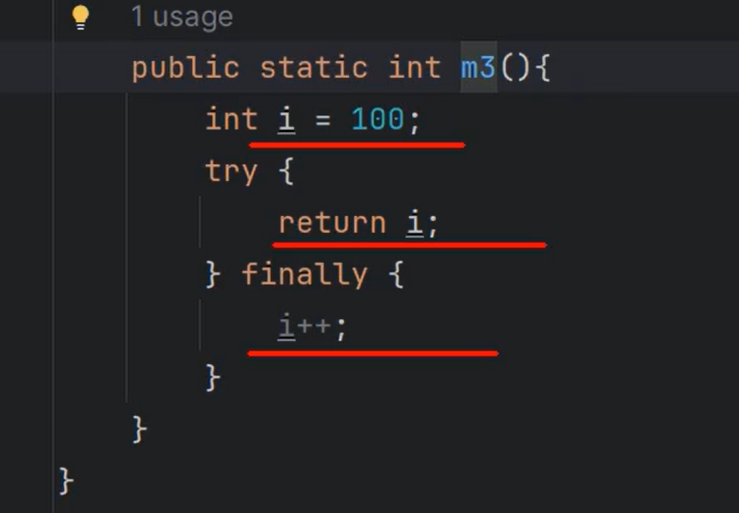
i为多少? 答:100
原因:
两个原则,(1)程序是自上而下执行的,(2)finally肯定是要执行的
所以,i返回的是100,但是会新建一个临时变量去执行i++
执行流程是先用一个临时变量做i++;然后做return,所以如果是return true;返回的就是true
2.
false:从上往下,finally一定会在最后执行
3.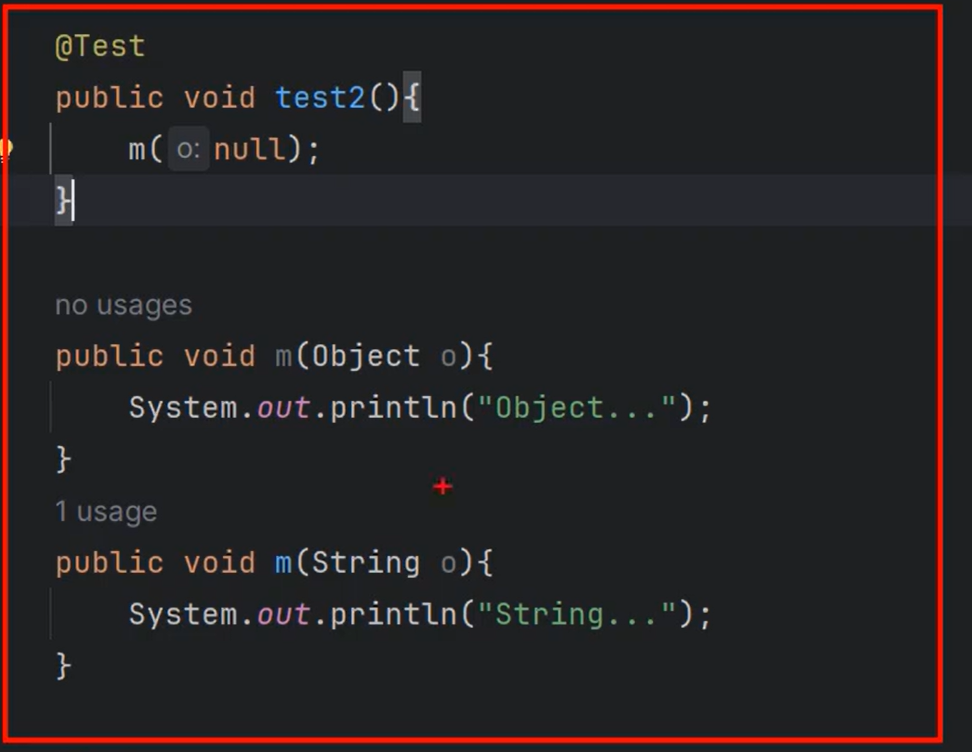
执行下一个
原则:就近原则(从继承关系的角度上讲)
null引用类型,距离String更近,String是Object的子类
4.
5.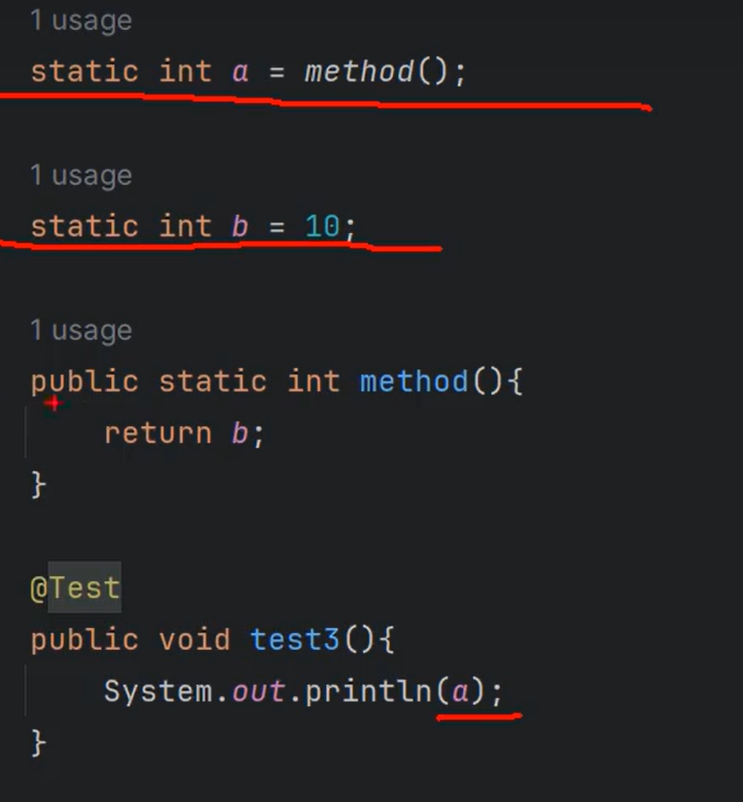
常理来说:a==10;
因为static块是在类加载的时候运行的,最先运行的,按照顺序运行的.
在创建static int a的时候,(method这个方法还没有运行到???运行到了吗),b还没有赋值,默认值0.所以a没有被这个方法成功赋值,此外,由于静态变量即使不赋值也会赋值默认值,所以赋值了0
6.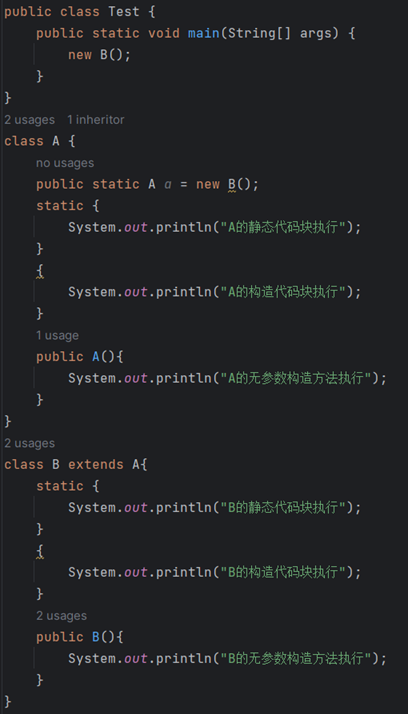
代码的执行顺序
我答:答不出来一点
答案:
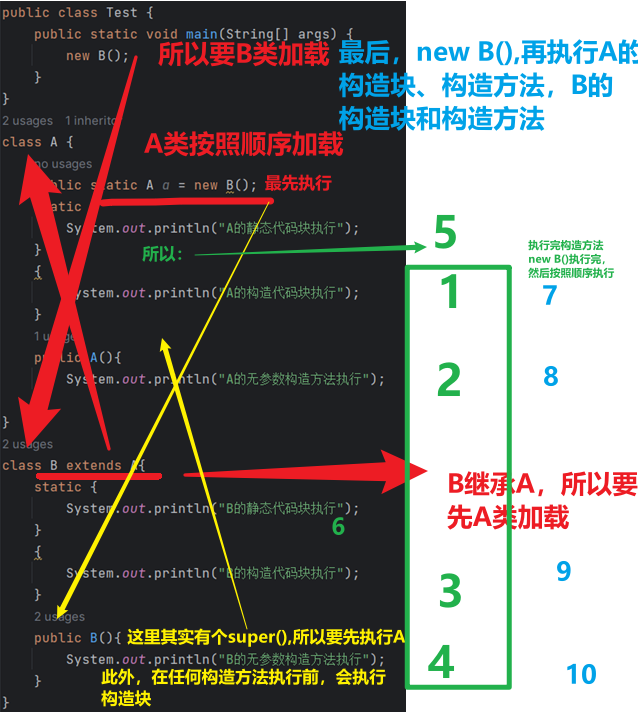
所以static不是一定要在这个B使用之前就跑了,就想B的静态代码就是最后跑的,但是此刻已经实现了new B()
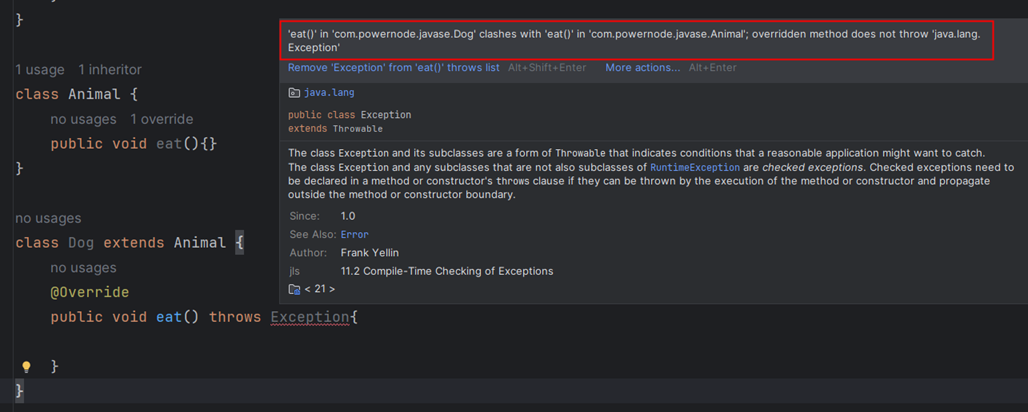
方法覆盖与异常
方法重写之后,不能比父类方法抛出更多的异常,可以更少。
就比如父类抛的是一个RuntimeExceptipn ,子类不能抛Exception
常用类
String类(注意:引用数据类型)
String初识
String类是无法继承的;
jdk9 之后引入了一种字符串压缩机制
Java中的String属于引用数据类型,代表字符串。
Java专门在==堆==中为字符串准备了一个==字符串常量池==。(JDK8)
因为字符串使用比较频繁,放在字符串常量池中省去了对象的创建过程,从而提高程序的执行效率。(常量池属于一种缓存技术,缓存技术是提高程序执行效率的重要手段。)
在编译阶段,就会把” “起来的字符串全部创建到字符串常量池里面(必须要有一份),然后用的时候直接拿
JVM在启动的时候,会进行一系列的初始化,其中就包括字符串常量池的初始化会在类加载的过程中就初始化出来了,程序在真正运行中,是不用创建字符串对象的// 一种缓存技术
1 | String s1 = “hello”; |
Java8之后字符串常量池在堆中。Java8之前字符串常量池在永久代。
字符串字面量一旦创建是不可变的。(底层String源码中有一个属性:private final byte[] value;)
1 | String s = “hello”; 其中“hello”存储在字符串常量池中。 |
“hello”不可变。不能变成“hello123”。如果进行字符串拼接,必然创建新的字符串对象。
是 “hello”不可变,不是s不可变,s可以指向其它的字符串对象:s = “xyz”;
从底层源码看,底层String源码中有一个属性:private final byte[] value;底层是个byte[]数组,数组长度不可变,所以长度不可变,
此外,这个数组是用private final修饰的,所以这个变量不可以被访问和继承修改
所以String的字面量一旦创建不可变
StringBuilder是可变的字符串数组,它的底层是byte[] value,所以可以改变,可以创建一个更大的数组,然后这个value就可以指向新的数组
String的拼接
①动态拼接之后的新字符串不会自动放到字符串常量池中:
1 | 1.String s1 = “abc”; |
==5.System.out.println(s3 == s4); // false 说明拼接后的字符串并没有放到字符串常量池==
==6.以上程序中字符串常量中有三个: “abc” “def” “abcdef”==
==7.以上程序中除了字符串常量池的字符串之外,在堆中还有一个字符串对象 “abcdef”==
②两个字符串字面量拼接会做编译阶段的优化,在编译阶段就会进行字符串的拼接。
1 | 1.String s1 = “aaa” + “bbb”; |
以上程序会在编译阶段进行拼接,因此以上程序在字符串常量池中只有一个: “aaabbb”
常量池可以改变吗?
可以,语句:s3.intern()
但是我们不能去删除常量池中的内容,系统自己有一些调整的操作
此时,s4和s5都在字符串常量池中

String类常用的构造方法有以下几种:
1 | String(char[] value)://根据字符数组创建一个新的字符串对象。 |
1 | char[] chars = new char[]('a','b','c','d','e','f','g'); |

这样会乱码
String的常用方法
1 | char charAt(int index); //返回索引处的char值 |

前>后;负
前<后;正
相等;0
右键 show Diagram
正则表达式
①正则表达式(regular expression),简称为regex或regexp,是一种用于描述特定模式的表达式。它可以匹配、查找、替换文本中与该模式匹配的内容,被广泛应用于各种文本处理和匹配相关的应用中。
②正则表达式的应用:
1.验证输入内容的格式是否正确。例如,邮箱,手机号,密码等
2.在文本编辑器中进行搜索和替换。例如,在代码编辑器中查找指定字符串或替换错误的代码成为正确的代码块
3.数据挖掘和信息提取。正则表达式可以从HTML、XML、JSON等格式的数据中提取所需的信息
4.用于编写脚本语言,如awk,grep和sed
5.服务器端编程。正则表达式在处理数据和字符串时具有高效的性能,可以在开发Web应用程序时被广泛应用
③正则表达式和Java语言的关系?
Java语言中可以使用正则表达式。C语言以及其它大部分编程语言都是支持正则表达式的。
==String的正则表达式相关的方法:==
1 | String replace(CharSequence target, CharSequence replacement); |
String的面试题
1.

false;
true
2.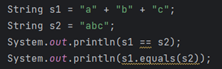
true;因为这种拼接会在编译阶段完成,编译器优化策略
true
3.
false:yin_yang:这个和上面那个不一样,上面那个是字面量相加,是可以在编译阶段实现,这个是变量,不在编译阶段实现,是存放在堆里的字符串变量;
如果s3.intern(),那就是一样了
true
4.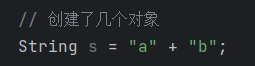
3个对象,a一个b一个,s一个,放在字符串常量区里
5.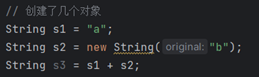
1 | //字符串常量池中一个"a" |
6.
字符串常量区:“a”,”b”
堆:new的a一个,new的b一个,拼接生成的StringBuilder一个,调用toString生成的一个String一个
一共6个对象
7.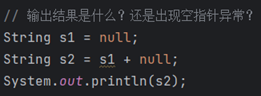
答案:不会出现异常,底层会默认调用valueOf,将非字符串类型的数据转换为字符串形式。结果null
8.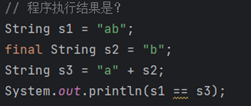
没有final的话,false,s3不在字符串常量池里
///*********************
true
final修饰后,s2不可变,就是个常量,所以这个拼接是在编译时候完成的,没有创建StringBuilder对象
所以是true
9.
false;
因为getB()是一个方法,只能在运行阶段,不能在编译阶段,所以虽然s2是个常量,但是他不在字符串常量区,在堆里面。
所以s3这个拼接操作也是在运行时候执行的,地址不一样,所以是false
10.
false
equals 的前提,两种类型要一样,这俩类型不一样
StringBuffer与StringBuilder
StringBuffer和StringBuilder:可变长度字符串

使用情况:这两个类是专门为频繁进行字符串拼接而准备。
二者差别:StringBuffer先出现的,Java5的时候新增了StringBuilder。StringBuffer是线程安全的。在不需要考虑线程安全问题的情况下优先选择StringBuilder,效率较高一些。
底层: 是 byte[] 数组,并且这个 byte[] 数组没有被final修饰,这说明如果byte[]数组满了,可以创建一个更大的新数组来达到扩容,然后它可以重新指向这个新的数组对象。
优化策略:==创建StringBuilder对象时,预估计字符串的长度,给定一个合适的初始化容量,减少底层数组的扩容。==
StringBuilder默认初始化容量:16
StringBuilder一次扩容多少?可以通过Debug跟踪一下append方法。扩容策略是:从当前容量开始,**==每次扩容为原来的2倍再加上2==**
原来是i,扩容后就是2i+2,如果是默认的,就开始2*16+2 ,然后2*(2+16)+2
如果拼接的字符串很大,大于了预期增长值,就会增大到拼接的字符串长度
假如是初始化len:50的字符串:
l16+minCapacity(34)==50
34>16+2,所以扩容大小为34
count 目前真实的存储数量
StringBuffer和StringBuilder构造方法
1 | StringBuilder() //构造一个字符串生成器,其中不包含任何字符,初始容量为16个字符。 |
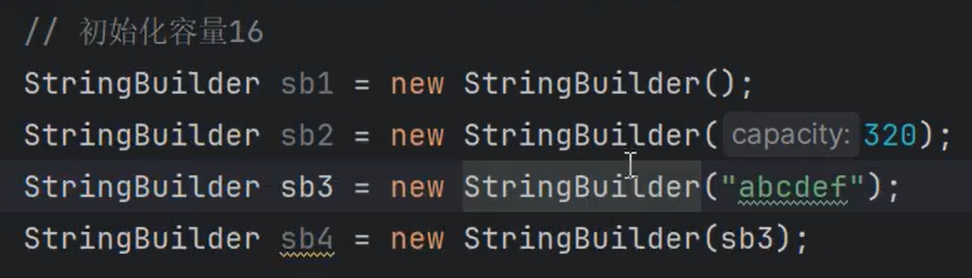
StringBuffer和StringBuilder常用方法
1 | StringBuilder append(Type data); |
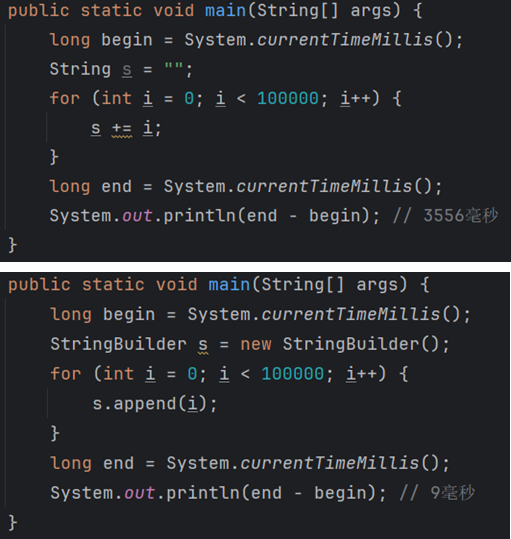
long begin = System.current.TimeMills();
从1970年1月1日 0时0分0秒开始 的总毫秒数
1 | //以下这种写法尽量避免,效率太低: |
包装类
什么是包装类?有什么用?
我的理解,将基础类型进行包装,形成一个引用类型,方便编程

比如在一个函数中,其接受的参数是引用类型(Object),实际应用起来是对于数字操作的,直接传进去数字是不行的,是会报错的,所以我们把这个int的10,包装成引用类型的10.

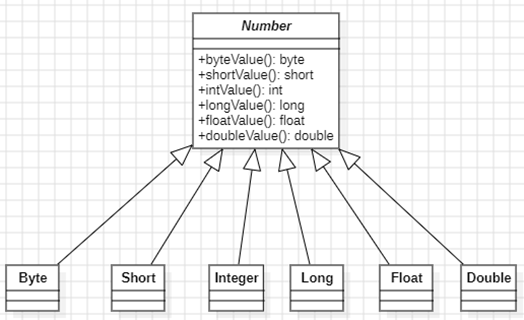
包装类中的6个数字类型都继承了Number类
boolean 和character没有继承
①Byte、Short、Integer、Long、Float、Double都继承了Number类,因此这些类中都有以下这些方法:
1 | byteValue() |
==这些方法的作用就是将包装类型的数据转换为基本数据类型。==
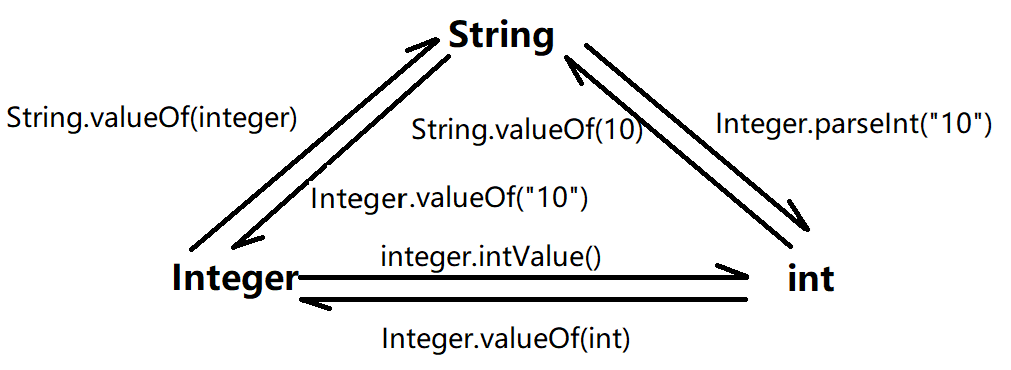
包装类转换成基本数据类型的过程我们称为:==拆箱 unboxing==
Boolean的拆箱方法:booleanValue();
Character的拆箱方法:charValue();
Integer的常量(为例子)
①通过Integer提供的常量可以获取int的最大值和最小值:
1 | ①最大值:Integer.MAX_VALUE |
②当然,其它5个数字包装类也有对应的常量:
1 | ①byte最大值:Byte.MAX_VALUE |
Integer的构造方法
①Integer(int value)
1.Java9之后标记已过时,不建议使用。
2.该构造方法可以将基本数据类型转换成包装类。这个过程我们称为装箱boxing
1 | int i = 100; |
②Integer(String s)
1.Java9之后标记已过时,不建议使用。
2.该构造方法可以将字符串数字转换成包装类。但字符串必须是整数数字,如果不是会出现异常:NumberFormatException
Integer的常用方法
1 | static int compare(int x, int y); //比较大小 |
Java5新特性:自动装箱和自动拆箱
编译阶段的功能
①Java5之后为了开发方便,引入了新特性:自动拆箱和自动装箱。
②自动装箱:auto boxing
1 | Integer a = 10000; |
③自动拆箱:auto unboxing
1 | int b = a; |
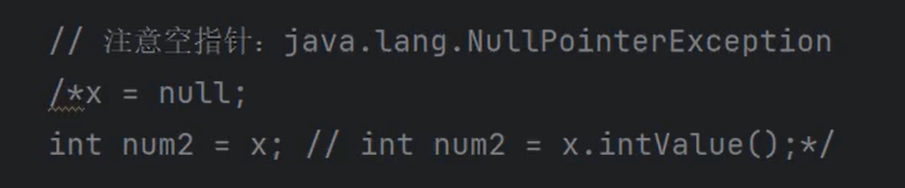
⑤注意空指针异常:
1 | Integer a = null; |
以上代码出现空指针异常的原因是a在进行自动拆箱时,会调用 a.intValue()方法。
因为a是null,访问实例方法会出现空指针异常,因此使用时应注意。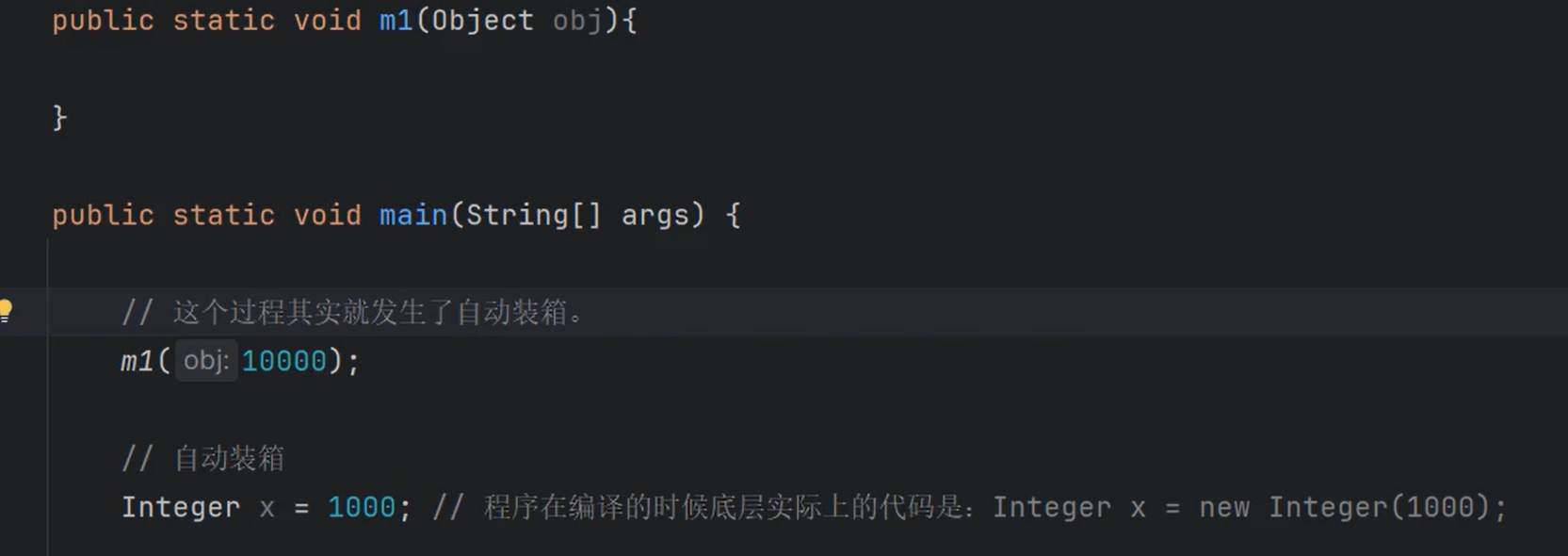
整数型常量池
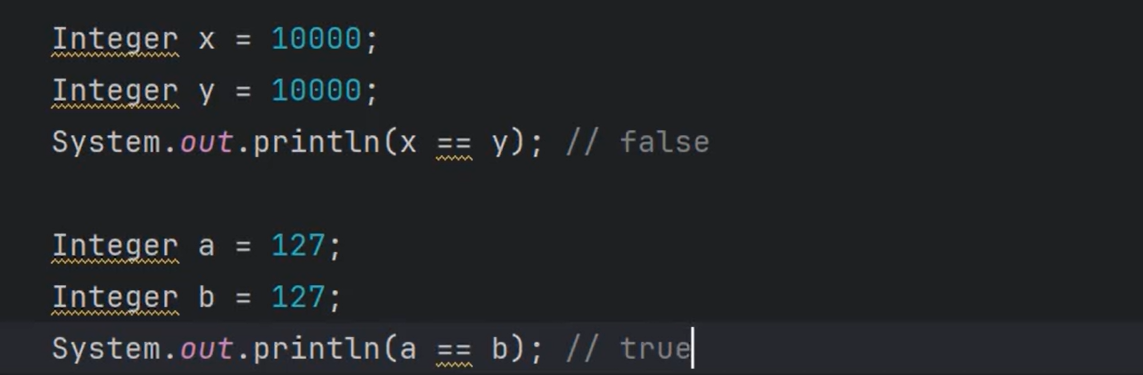
①**==[-128 ~ 127] Java为这个区间的Integer对象创建了整数型常量池。==**
②也就是说如果整数没有超出范围的话,直接从整数型常量池获取Integer对象。
③以下是一个面试题:请说出它的输出结果:
1 | Integer x = 128; |
大数字
如果整数超过long的最大值怎么办?
这个是引用数据类型
①java中提供了一种引用数据类型来解决这个问题:**==java.math.BigInteger==。它的父类是==Number。==**
②常用构造方法:BigInteger(String val)
③常用方法:
1 | BigInteger add(BigInteger val); 求和 |
如果浮点型数据超过double的最大值怎么办?
①java中提供了一种引用数据类型来解决这个问题**==:java.math.BigDecimal==(经常用在财务软件中)。它的父类是==Number。==**
②构造方法:**==BigDecimal(String val)==**
③常用方法:
1 | BigDecimal add(BigDecimal augend); 求和 |
数字格式化

日期处理
日期相关API
①**==long l = System.currentTimeMillis();==** // 获取自1970年1月1日0时0分0秒到系统当前时间的总毫秒数。
②java.util.Date 日期类
①构造方法:Date()
②构造方法:Date(long 毫秒)
③java.util.SimpleDateFormat 日期格式化类
①日期转换成字符串(java.util.Date -> java.lang.String)
②字符串转换成日期(java.lang.String -> java.util.Date)
1 | //Date ---》string format |
④java.util.Calendar 日历类
①获取当前时间的日历对象:Calendar c = Calendar.getInstance();
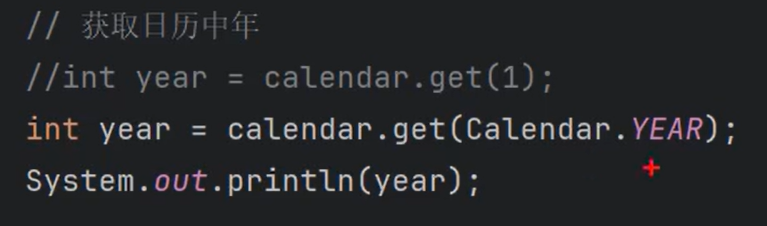
②获取日历中的某部分:int year = c.get(Calendar.YEAR);
1 | Calendar.YEAR //获取年份 Calendar.MONTH 获取月份,0表示1月,1表示2月,...,11表示12月 |
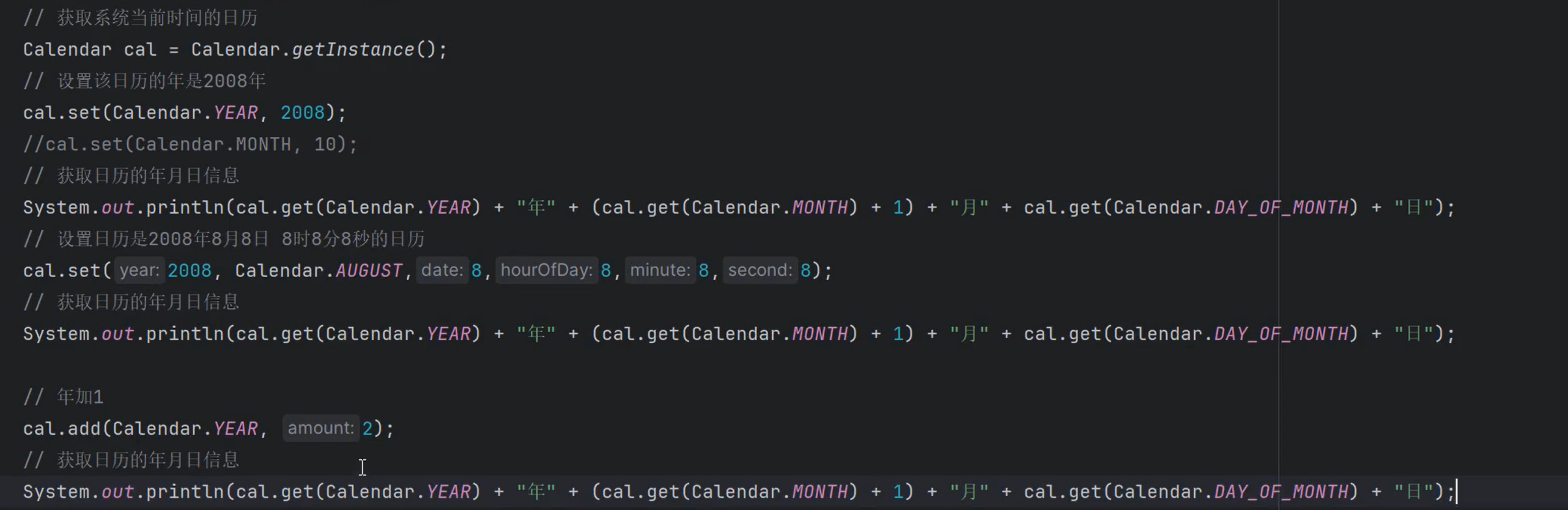
①java.util.Calendar 日历类
1.日历的set方法:设置日历
静态变量
1.calendar.set(Calendar.YEAR, 2023);
2.calendar.set(2008, Calendar.SEPTEMBER,8);
2.日历的add方法(日历中各个部分的加减):
1.calendar.add(Calendar.YEAR, 1);
3.日历对象的setTime()让日历关联具体的时间
1.calendar.setTime(new Date());
4.日历对象的getTime()方法获取日历的具体时间:
1.Date time = calendar.getTime();
1 | Calendar cal = new Calendar(); |
Java8的新日期API
传统的日期API存在线程问题
新的API在java.time包
传统的日期API存在线程安全问题,Java8又提供了一套全新的日期API
- ①java.time.LocalDate、java.time.LocalTime、java.time.LocalDateTime 日期、时间、日期时间
- ②java.time.Instant 时间戳信息197001010000到现在的时间毫秒
- ③java.time.Duration 计算两个时间对象之间的时间间隔,精度为纳秒
- ④java.time.Period 计算两个日期之间的时间间隔,以年、月、日为单位。
- ⑤java.time.temporal.TemporalAdjusters 提供了一些方法用于方便的进行日期时间调整
- ⑥java.time.format.DateTimeFormatter 用于进行日期时间格式化和解析
LocalDate日期、LocalTime时间、LocalDateTime日期时间
①获取当前时间(精确到纳秒,1秒=1000毫秒,1毫秒=1000微秒,1微秒=1000纳秒)
1 | LocalDateTime now = LocalDateTime.now(); |
②获取指定日期时间
1 | LocalDateTime ldt = LocalDateTime.of(2008,8,8,8,8,8,8); // 获取指定的日期时间 |
③加日期和加时间
1 | LocalDateTime localDateTime = ldt.plusYears(1).plusMonths(1).plusDays(1).plusHours(1).plusMinutes(1).plusSeconds(1).plusNanos(1); |
④减日期和减时间
1 | LocalDateTime localDateTime = ldt.minusYears(1).minusMonths(1).minusDays(1).minusHours(1).minusMinutes(1).minusSeconds(1).minusNanos(1); |
⑤获取年月日时分秒
1 | int year = now.getYear(); // 年 int month = now.getMonth().getValue(); // 月 |
==Instant 时间戳(获取1970年1月1日 0时0分0秒到某个时间的时间戳)==
①获取系统当前时间(UTC:全球标准时间)
1 | Instant instant = Instant.now(); |
②获取时间戳
1 | long epochMilli = instant.toEpochMilli(); |
Duration 计算时间间隔
①计算两个时间相差时间间隔Duration.between(now1, now2);
1 | LocalDateTime now1 = LocalDateTime.of(2008,8,8,8,8,8); |
Period 计算日期间隔
①计算两个日期间隔Period.between(now1, now2);
1 | LocalDate now1 = LocalDate.of(2007,7,7); |
TemporalAdjusters 时间矫正器
1 | ①LocalDateTime now = LocalDateTime.now(); // 获取系统当前时间 |
DateTimeFormatter 日期格式化
①日期格式化 (LocalDateTime –> String)
1 | LocalDateTime now = LocalDateTime.now(); |
②将字符串转换成日期(String –> LocalDateTime)
1 | DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"); |
Math
java.lang.Math 数学工具类,都是**==静态方法==**
①常用属性:static final double PI(圆周率)
②常用方法:
1 | static int abs(int a); //绝对值 |
枚举
枚举(Java5新特性)
①枚举类型在Java中是一种==引用数据类型。==
②合理使用枚举类型可以让代码更加清晰、可读性更高,可以有效地避免一些常见的错误。
③什么情况下考虑使用枚举类型?
1.这个数据是有限的,并且可以一枚一枚列举出来的。
2.枚举类型是类型安全的,它可以有效地防止使用错误的类型进行赋值。
④枚举如何定义?以下是最基本的格式:
1 | enum 枚举类型名 { |
⑤通过反编译(javap)可以看到:
1.所有枚举类型默认继承java.lang.Enum,因此枚举类型无法继承其他类。
2.所有的枚举类型都被final修饰,所以枚举类型是无法继承的
3.所有的枚举值都是常量
4.所有的枚举类型中都有一个values数组(可以通过values()获取所有枚举值并遍历)
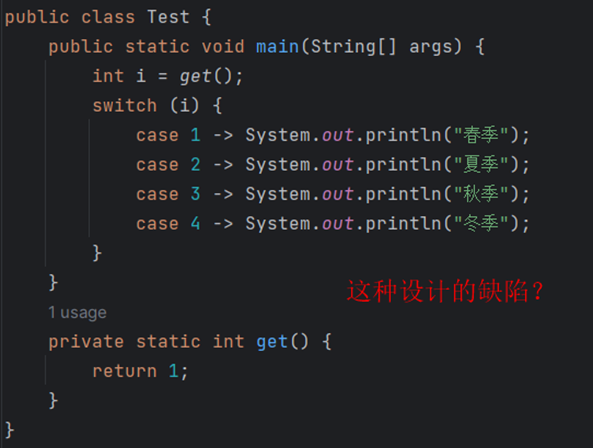
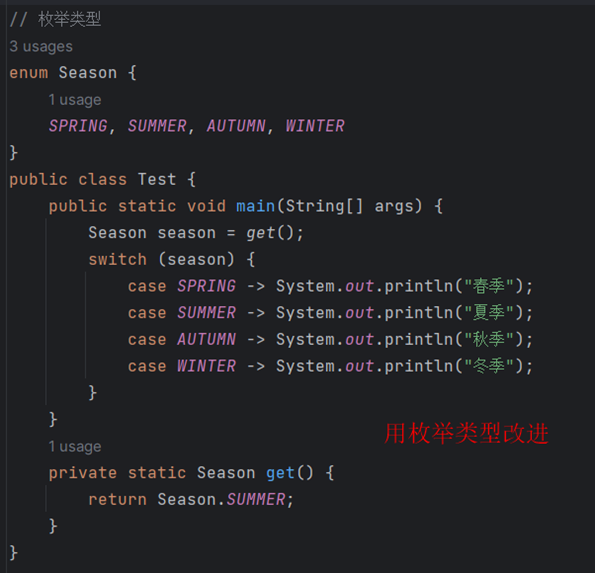
枚举的高级用法
①普通类中可以编写的元素,枚举类型中也可以编写。
静态代码块,构造代码块
实例方法,静态方法
实例变量,静态变量
②枚举类中的==构造方法是私有化==的(默认就是私有化的,只能在本类中调用)
构造方法调用时不能用new。直接使用“枚举值(实参);”调用。
每一个枚举值相当于枚举类型的实例。
枚举类最开始的时候 定义的枚举值就是枚举类对象,会调用构造函数,默认会调用无参构造函数
如果定义了有参构造函数,没有修改在上面定义的枚举值的话,就会报错
所以需要对于枚举值修改一下构造函数
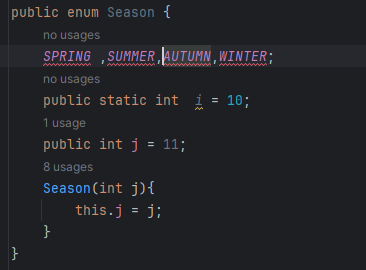
1 | public enum Season { |
③枚举类型中如果编写了其他代码,==必须要有枚举值,枚举值的定义要放到最上面,==
==最后一个枚举值的分号不能省略。==
④枚举类因为默认继承了==java.lang.Enum==,因此不能再继承其他类,但可以实现接口。
第一种实现方式:在枚举类中实现。
第二种实现方式:让每一个枚举值实现接口。

1 | public enum Season implements Eatable{ |
Random
java.util.Random 随机数生成器(生成随机数的工具类)
①常用构造方法:
1 | Random() |
②常用方法:
1 | int nextInt(); 获取一个int类型取值范围内的随机int数 |
xxxxxxxxxx package com.powernode.javase.oop45;/** * 匿名内部类:没有名字的类。只能使用一次。 */public class Test { public static void main(String[] args) { // 创建电脑对象 Computer computer = new Computer(); //computer.conn(new Printer()); // 以下conn方法参数上的代码做了两件事: // 第一:完成了匿名内部类的定义。 // 第二:同时实例化了一个匿名内部类的对象。 computer.conn(new Usb(){ // 接口的实现 @Override public void read() { System.out.println(“read…..”); } @Override public void write() { System.out.println(“write…..”); } }); }}class Computer { public void conn(Usb usb){ usb.read(); usb.write(); }}interface Usb { void read(); void write();}// 编写一个接口的实现类/*class Printer implements Usb { @Override public void read() { System.out.println(“打印机开始读取数据”); } @Override public void write() { System.out.println(“打印机开始打印”); }} */java
java.lang.System类的常用方法:
①常用属性:
1 | static final PrintStream err 标准错误输出流(System.err.println(“错误信息”);输出红色字体) |
②常用方法:
1 | static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length); 数组拷贝 |
UUID
具有全球唯一性的标识
UUID(通用唯一标识符)是一种软件构建的标准,用来生成具有唯一性的ID。
UUID具有以下特点:
①UUID可以在分布式系统中生成唯一的标识符,避免因为主键冲突等问题带来的麻烦。
==②UUID具有足够的唯一性,重复的概率相当低。UUID使用的是128位数字,除了传统的16进制表示之外(32位的16进制表示),还有基于62进制的表示,可以更加简洁紧凑。==
③UUID生成时不需要依赖任何中央控制器或数据库服务器,可以在本地方便、快速地生成唯一标识符。
④UUID生成后可以被许多编程语言支持并方便地转化为字符串表示形式,适用于多种应用场景。
在Java开发中,UUID的使用是非常普遍的。它可以用于生成数据表主键、场景标识、链路追踪、缓存Key等。使用UUID可以方便地避免主键、缓存Key等因冲突而产生的问题,同时能够实现多种功能,例如追踪、缓存、日志记录等。
Java中的java.util.UUID类提供对UUID的支持
①生成UUID:static UUID randomUUID();
②将UUID转换为字符串:String toString();