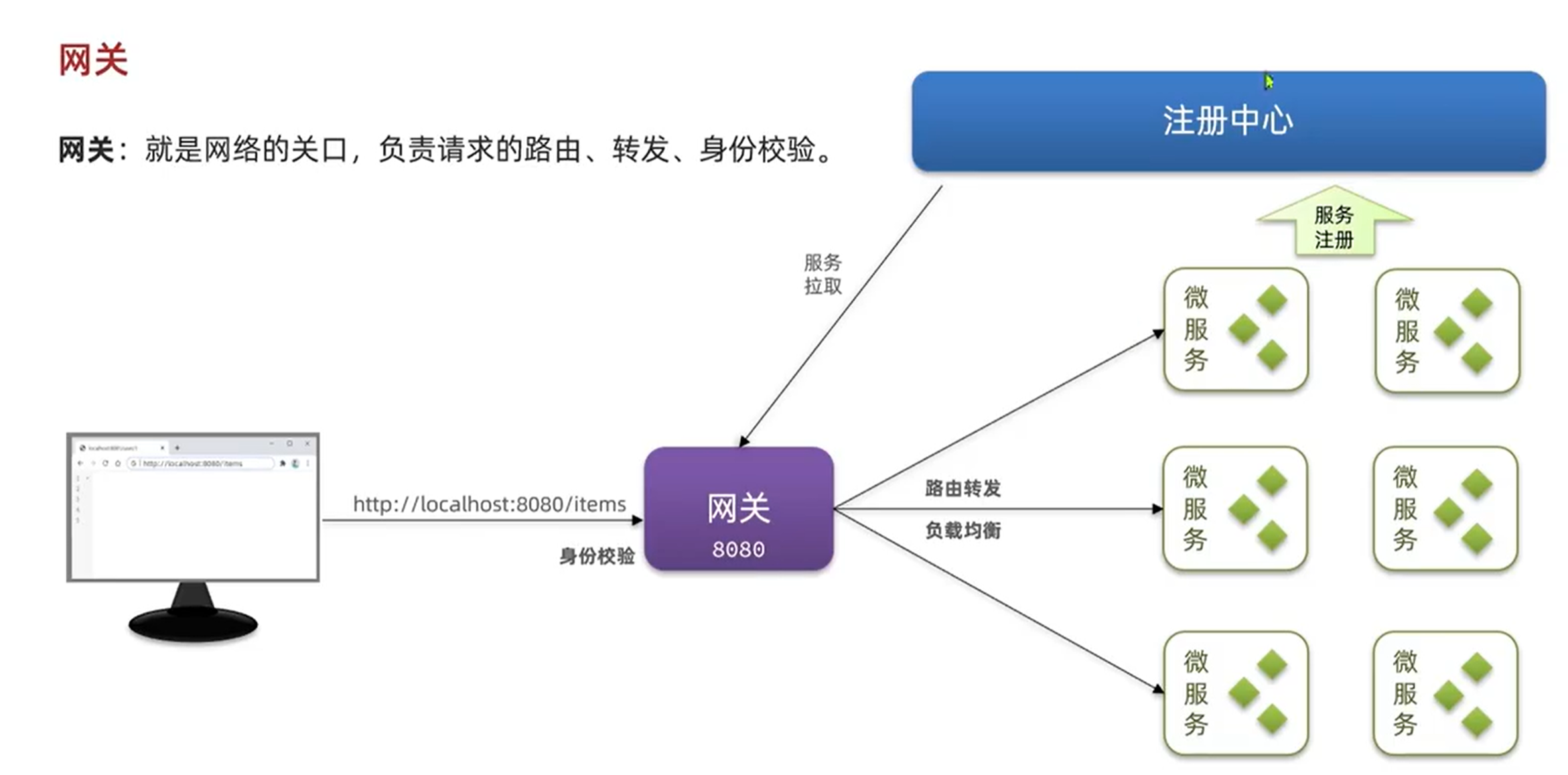
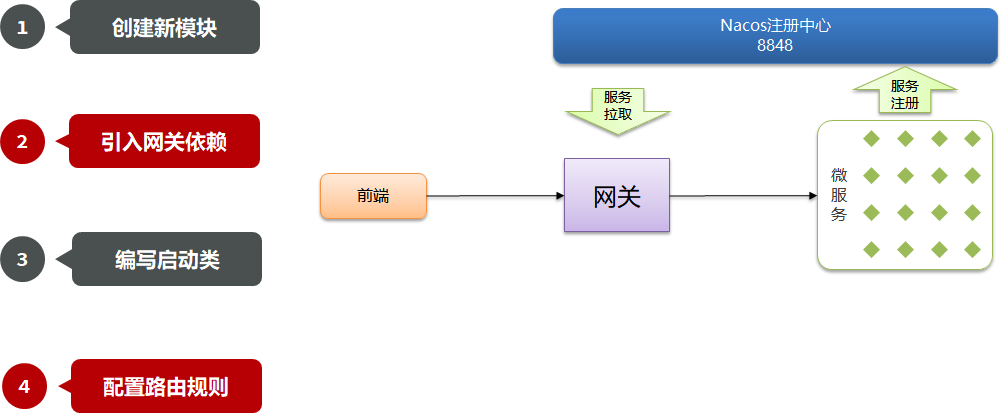
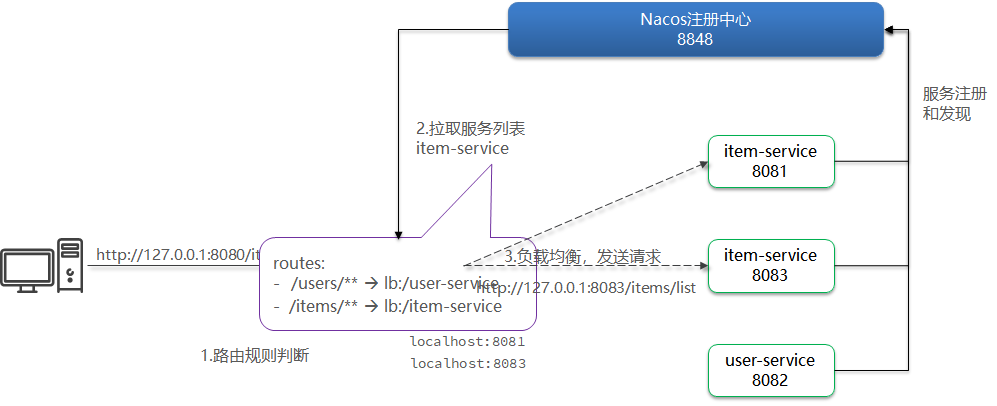
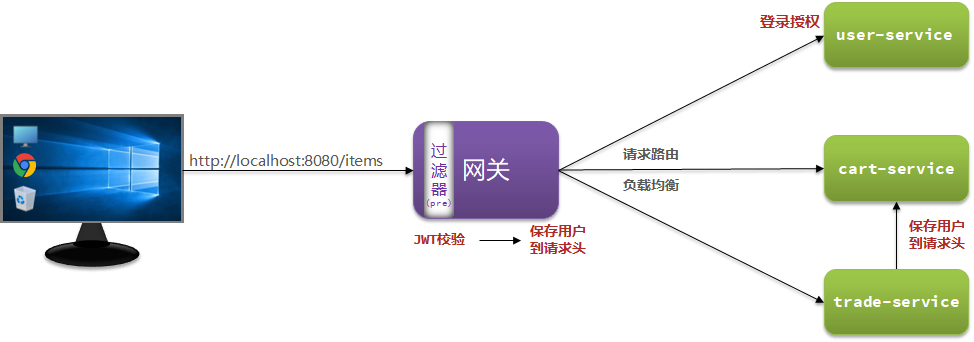
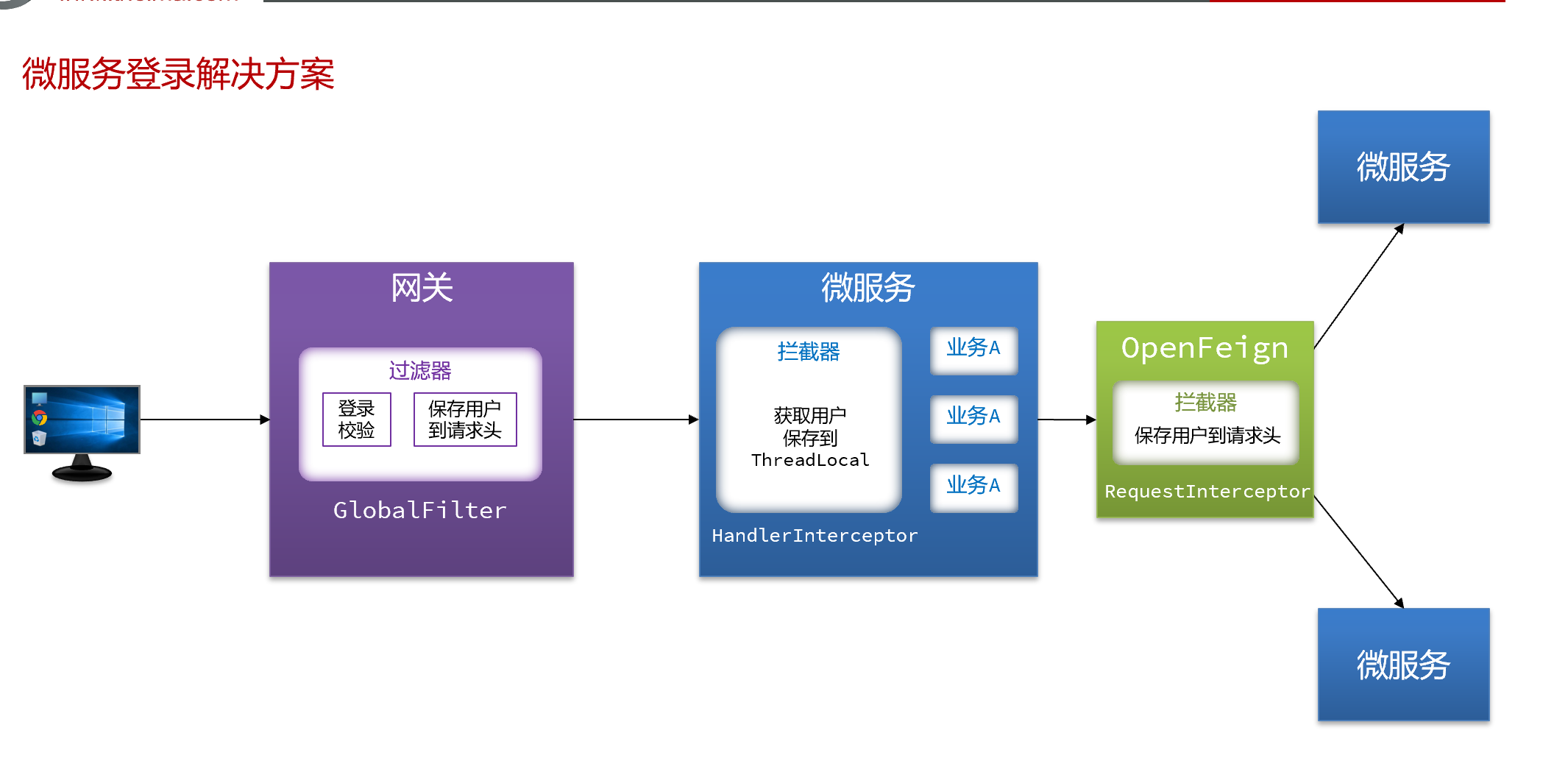
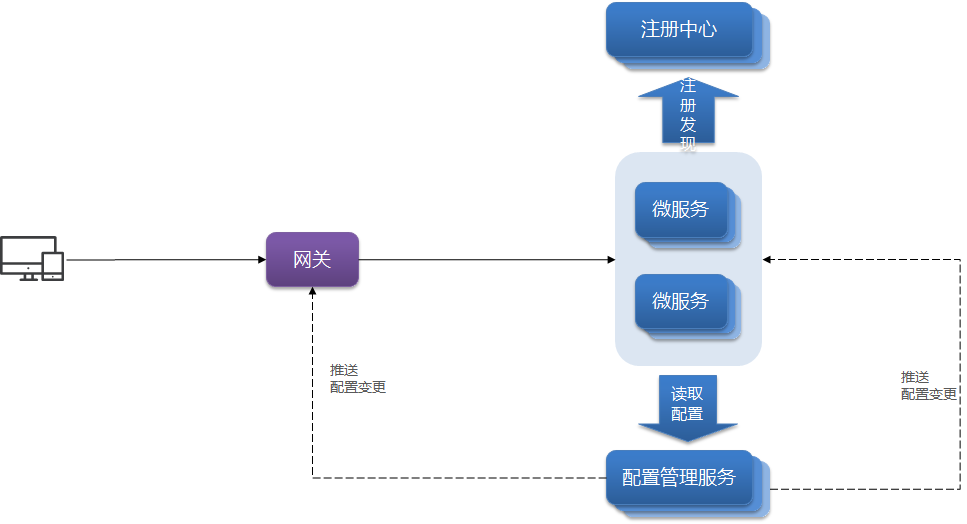
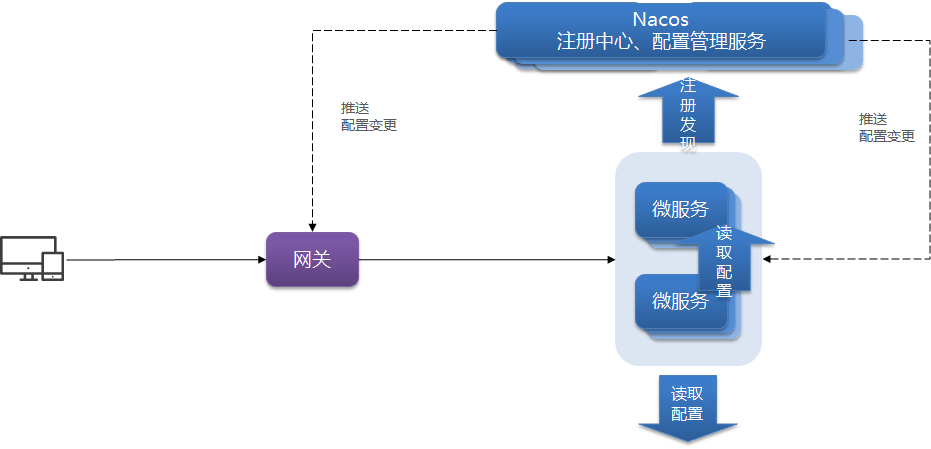
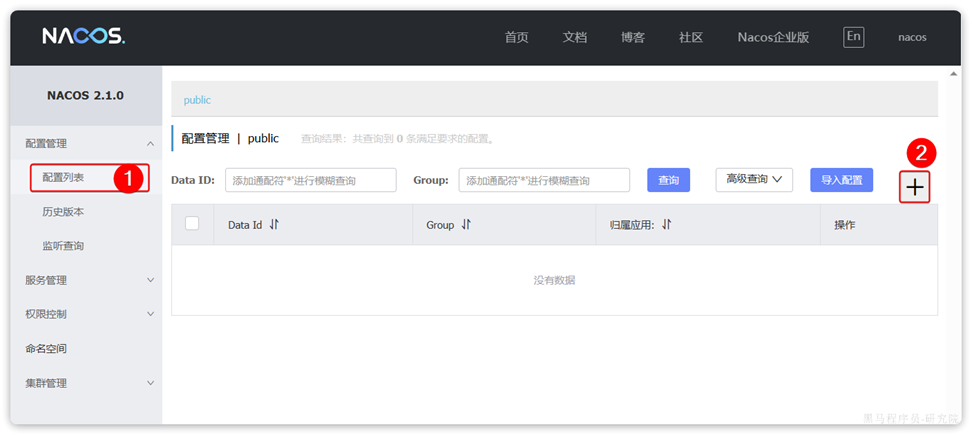
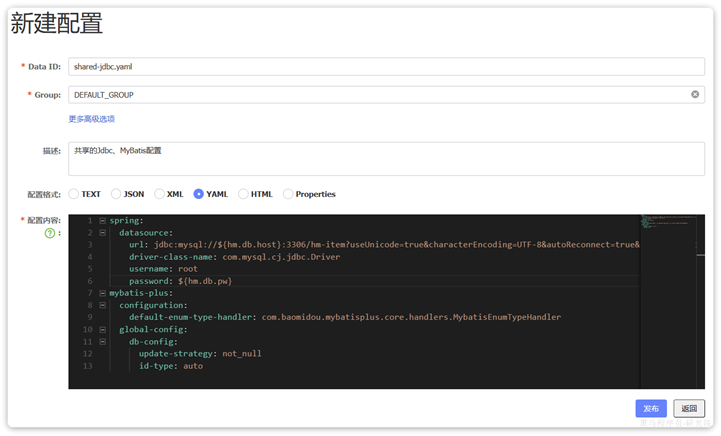
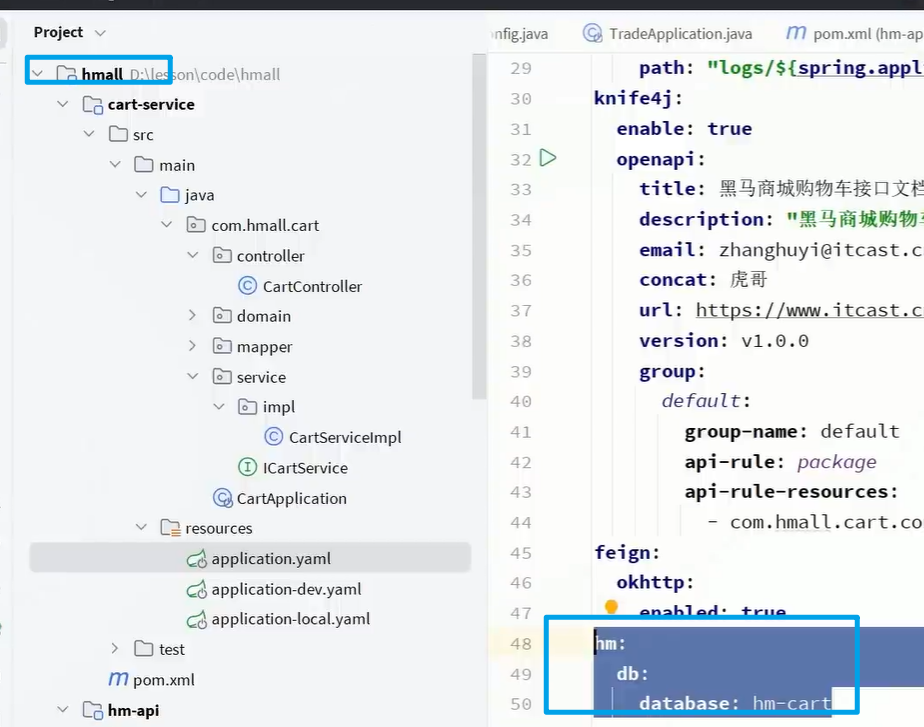
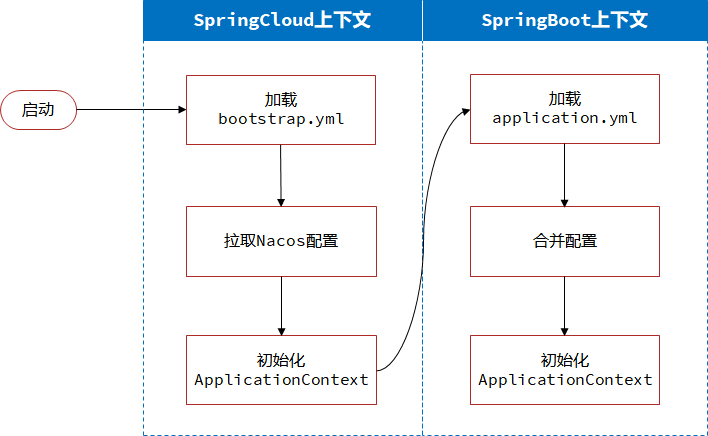
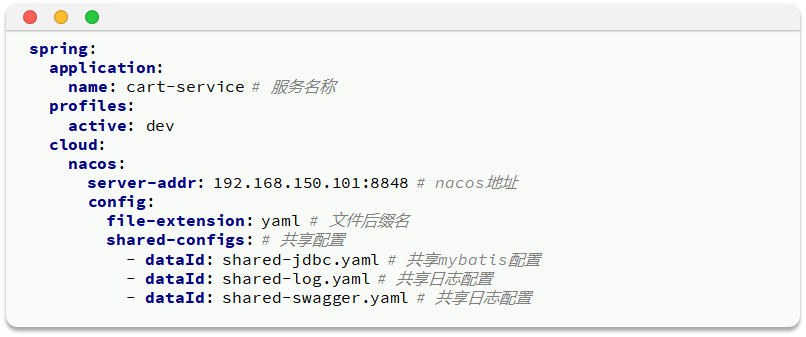
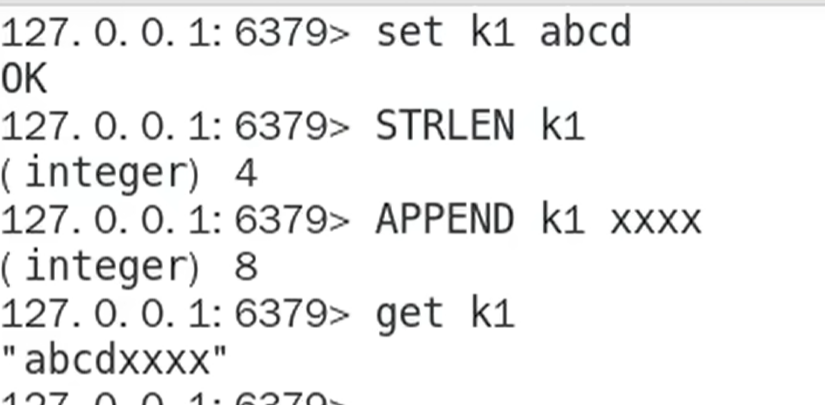
Redis-复制
Redis复制(replica)

就是主从复制,master以写为主,Slave以读为主
当master数据变化的时候,自动iang新的数据异步同步到其他的slave数据库
能干什么
读写分离
写找master 读找slave
容灾恢复
数据备份
水平扩容支持高并发
怎么操作
配置从库不配置主库

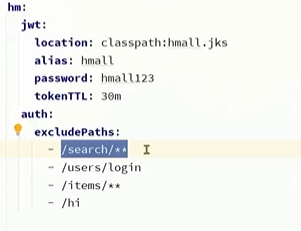
master 如果配置了requirepass参数,需要密码登录
那么slave就要配置masterauth来设置校验密码,否则master就会拒绝slave的访问请求。
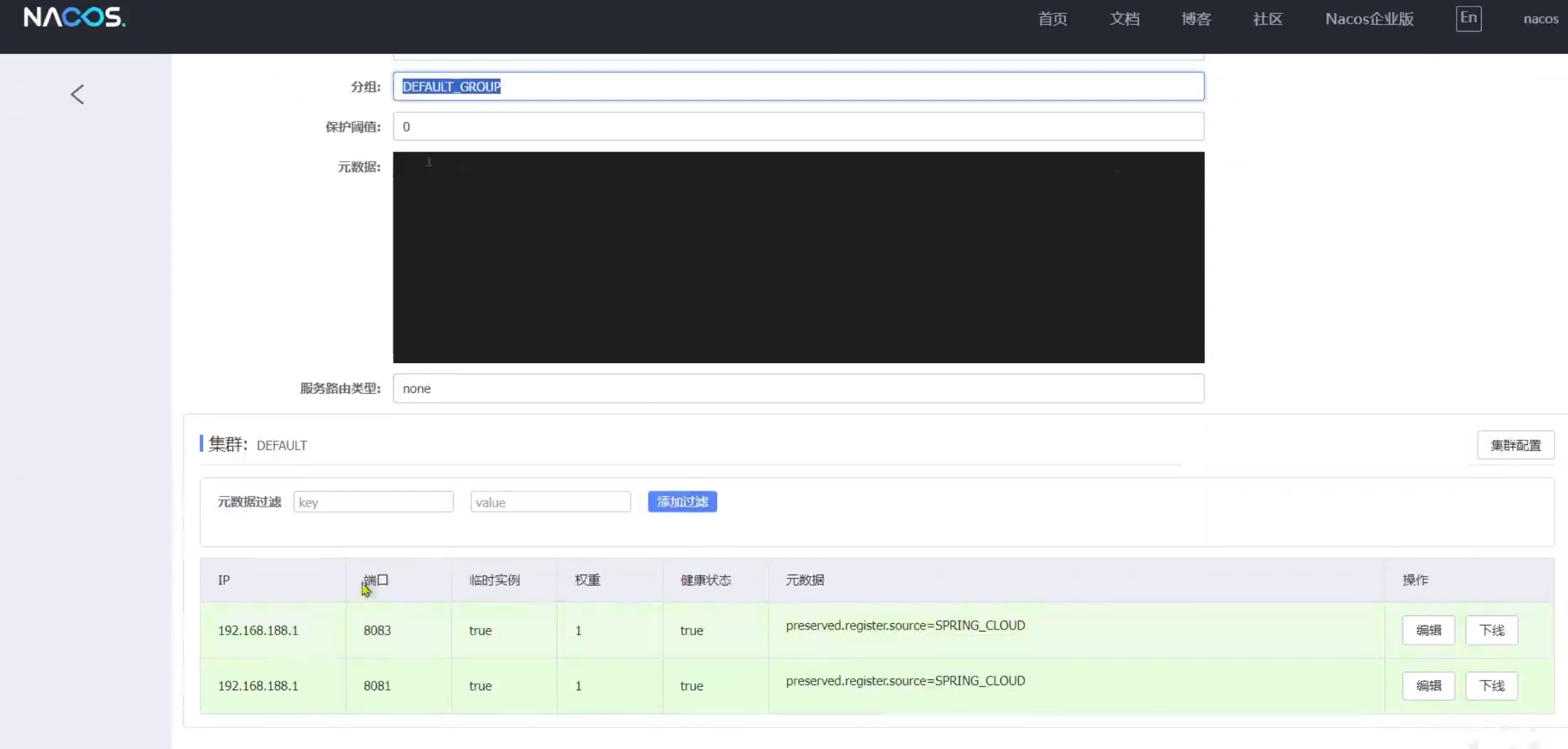
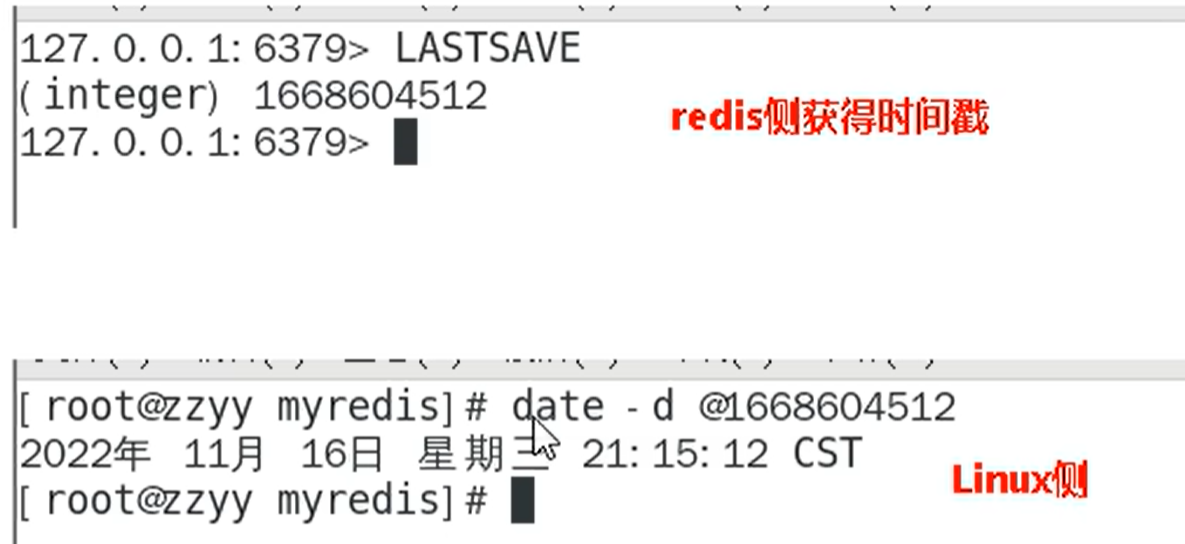
info replication
建立了主从关系之后可以查看复制节点的主从关系和配置信息
replicaof 主库IP 主库端口
在从机上写清楚,找哪个为主机,一般写入redis.conf配置文件内的
slaveof 主库IP 主库端口
有些类似于上一个指令(写进配置文件的) 的命令版本
每次与master断开之后,都要重新连接,除非你配置进redis,conf文件
==在运行期间修改slave节点的消息,如果该数据库已经是某个主数据库的从数据库,那么就会停止和原主数据库的同步关系转而和新的数据库同步,重新设置主数据库==
slaveof no one

使当前数据库停止与其他数据库的同步,转为主数据库
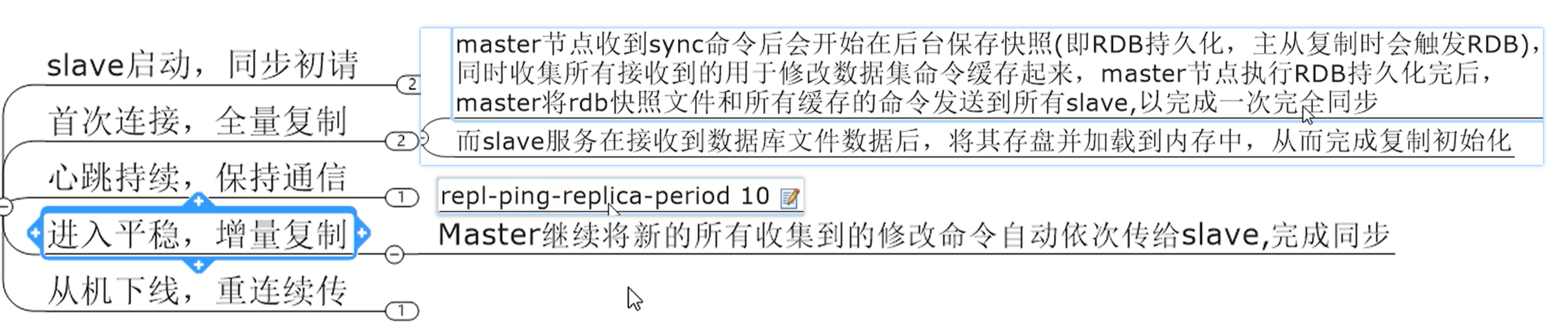
复制的原理和工作流程
1 slave 启动成功连接到master后会发送一个syncm’l
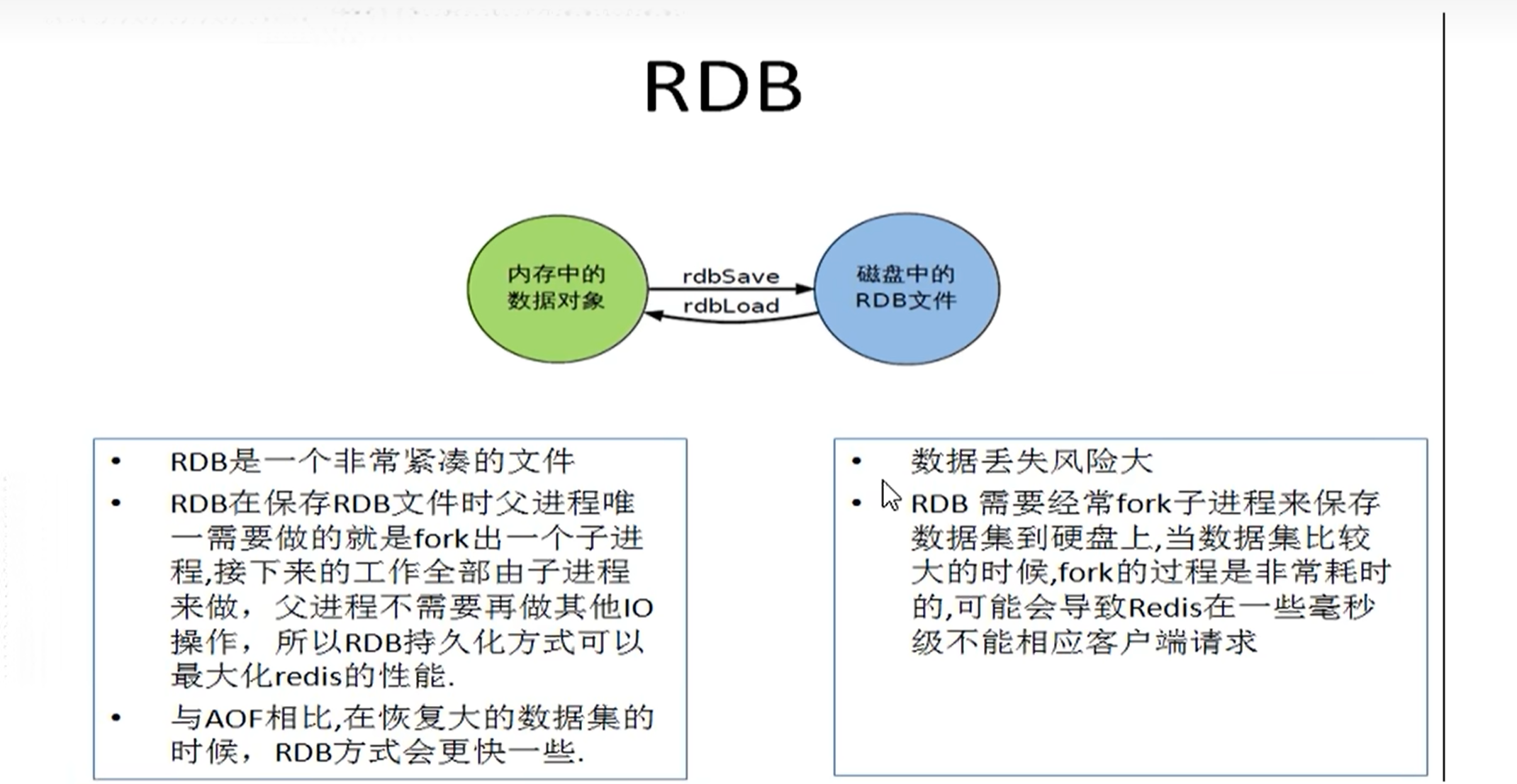
slave首次全新连接master,一次完全同步,(全量复制)将会被自动的执行,slave自身原有数据会被master数据覆盖

复制的缺点
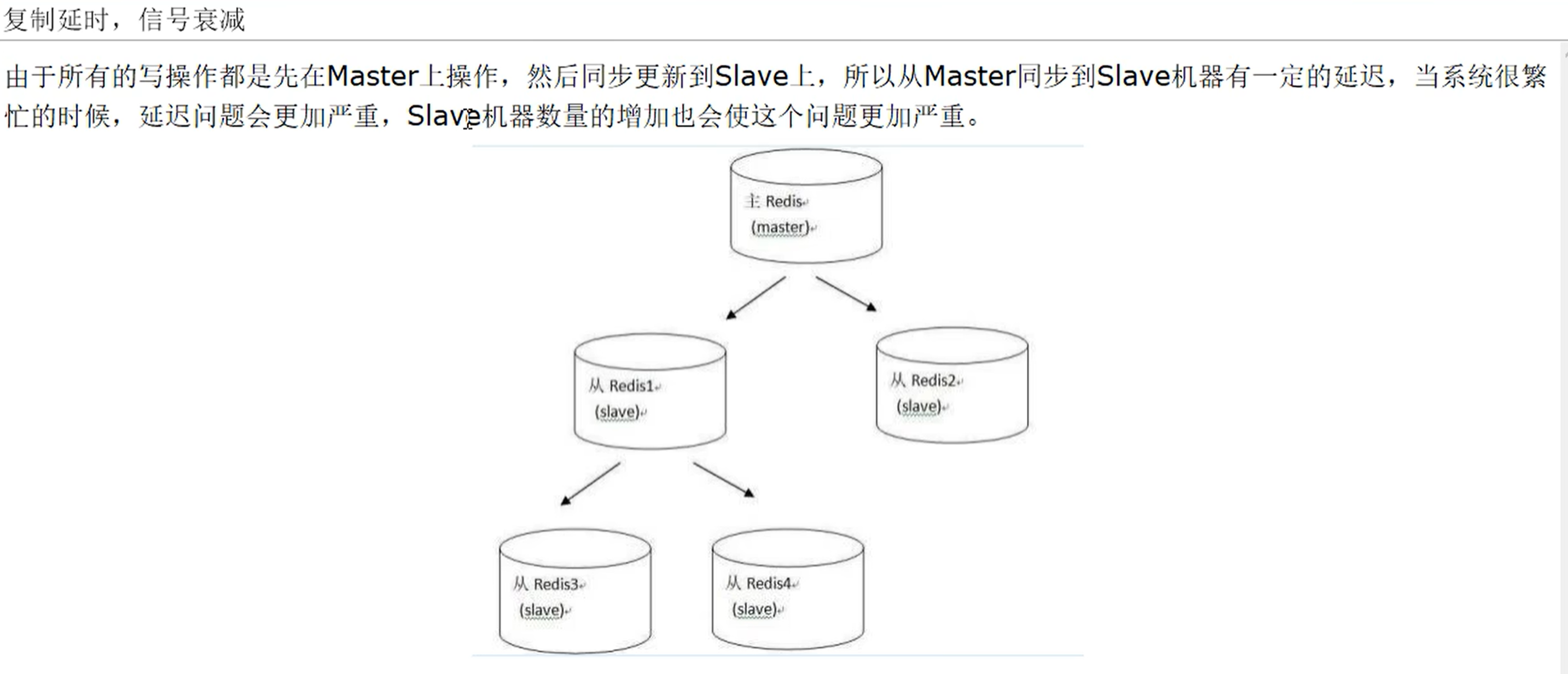
复制延时,信号衰减
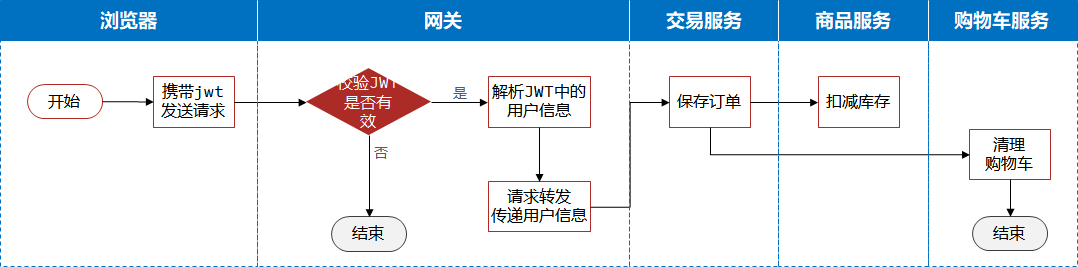
master挂了怎么办?


























































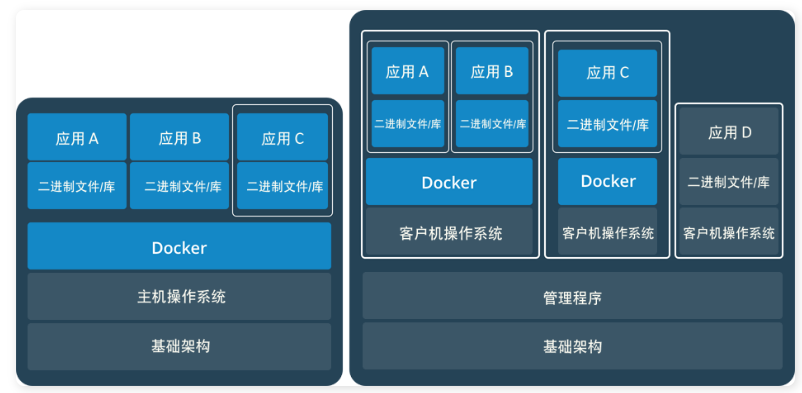
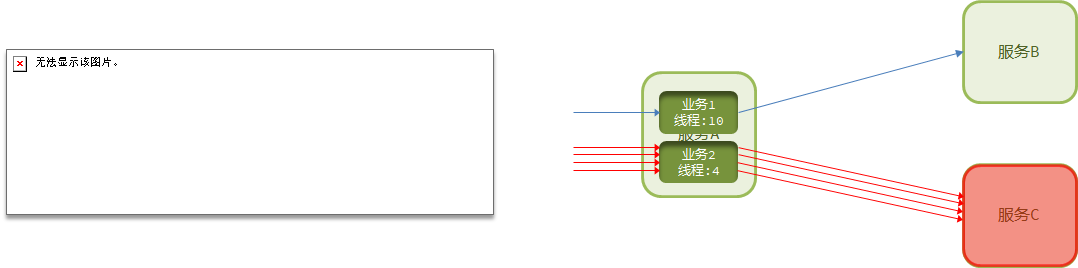
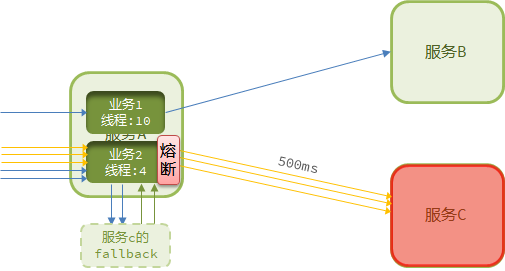
 有个服务很高 一个服务就所有的线程和进程全占了
有个服务很高 一个服务就所有的线程和进程全占了