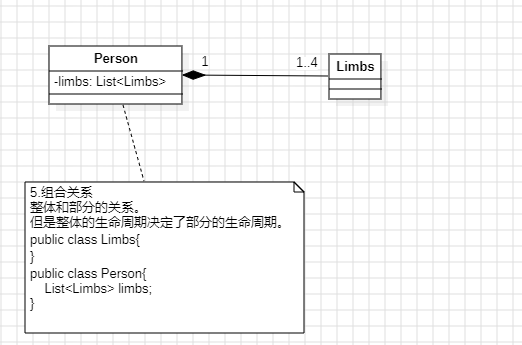
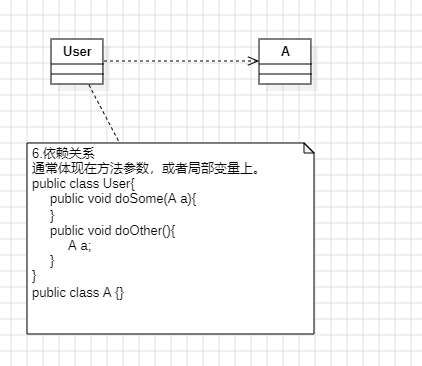
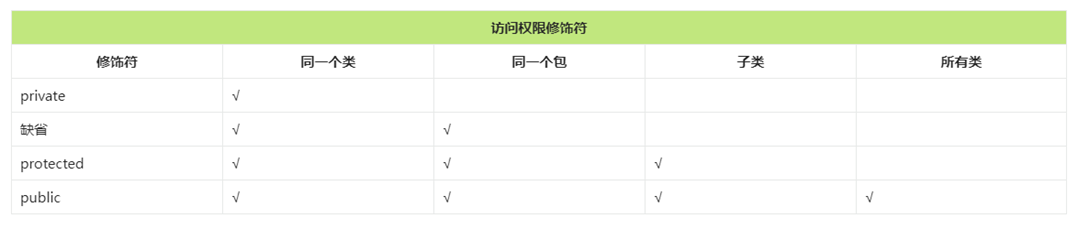
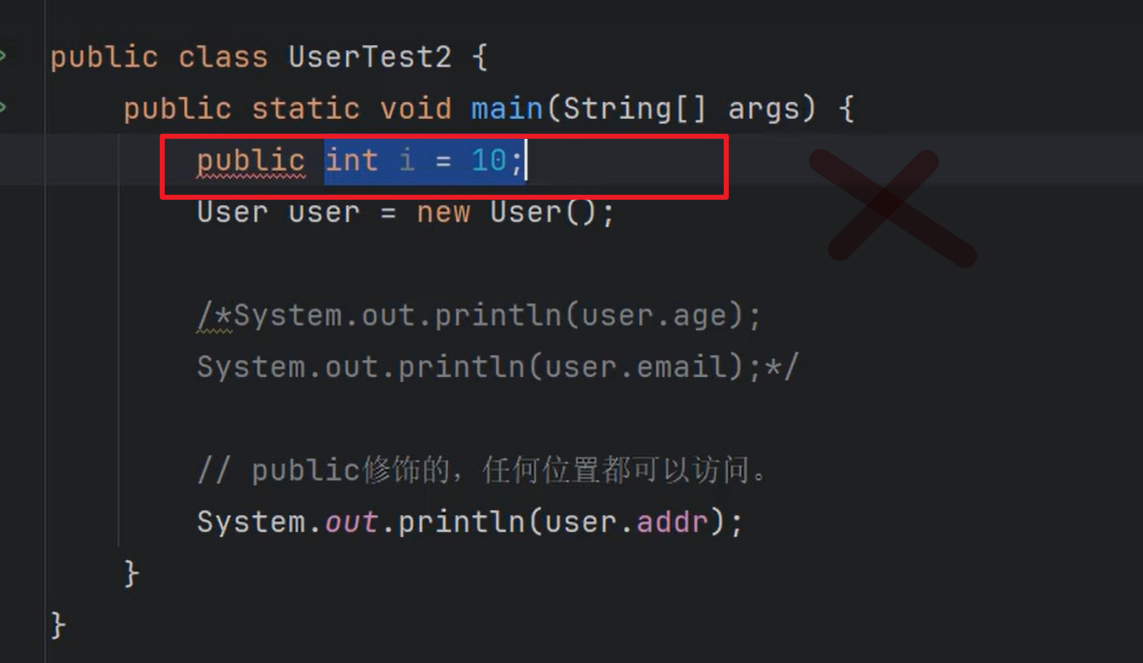
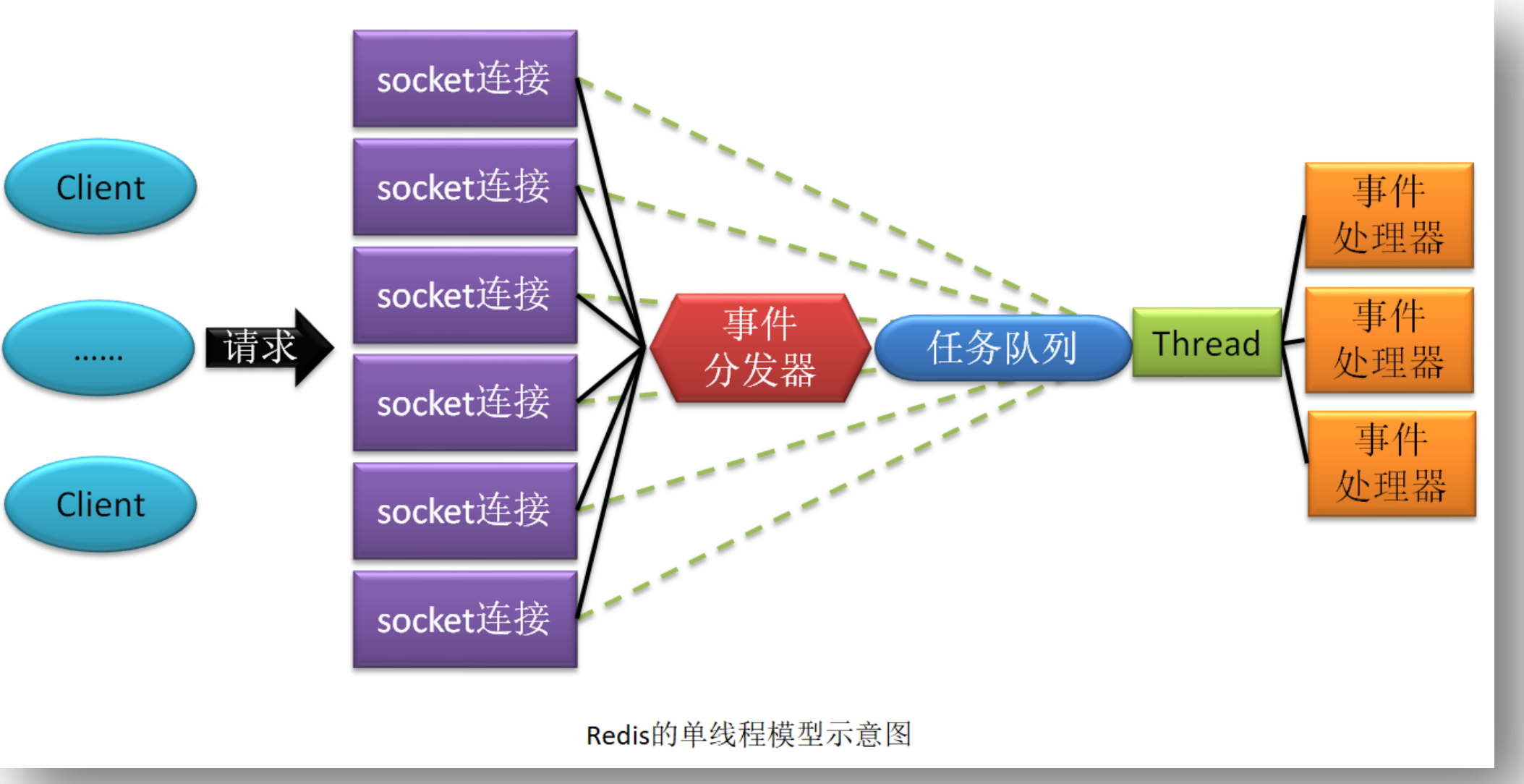
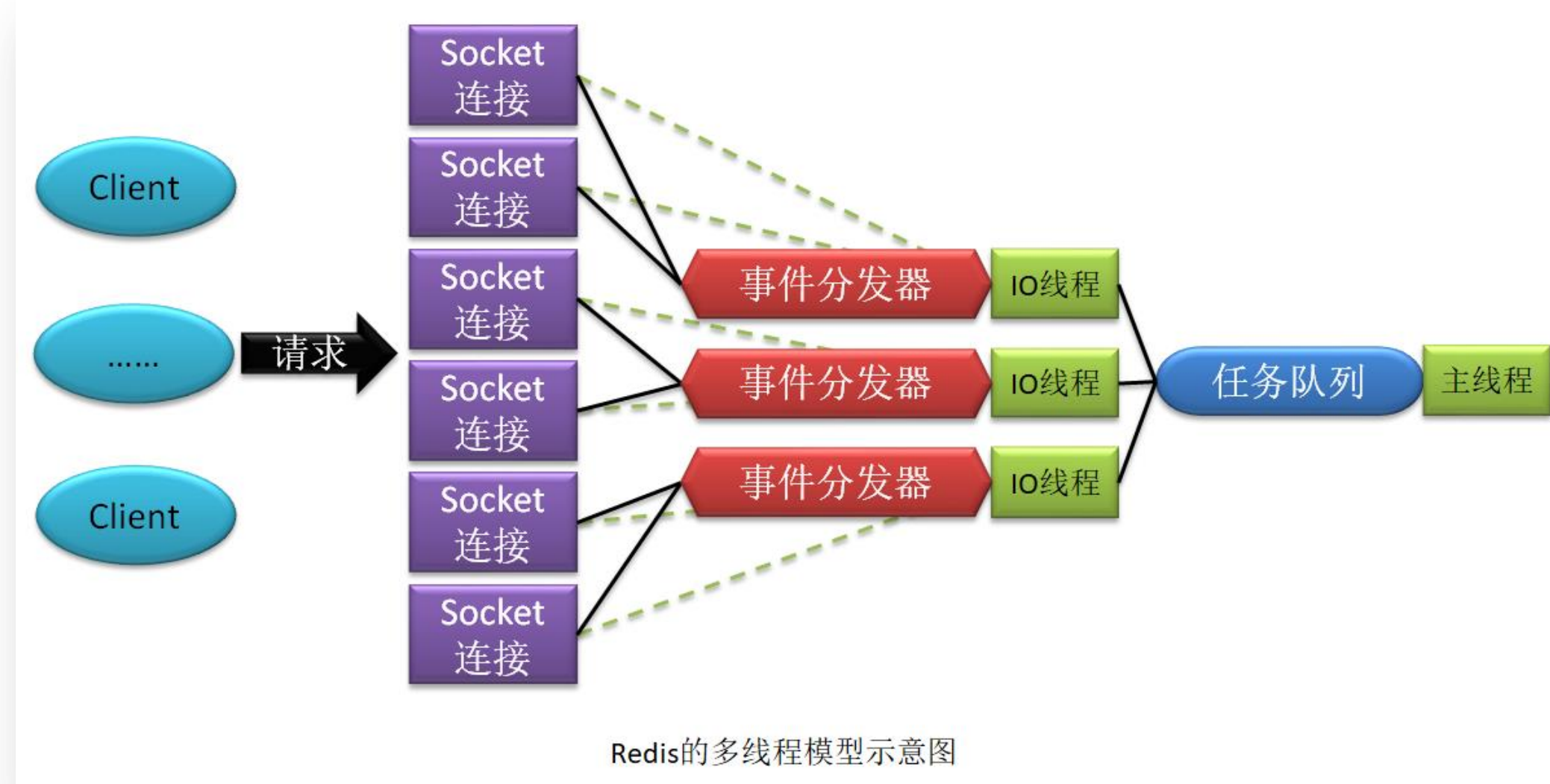
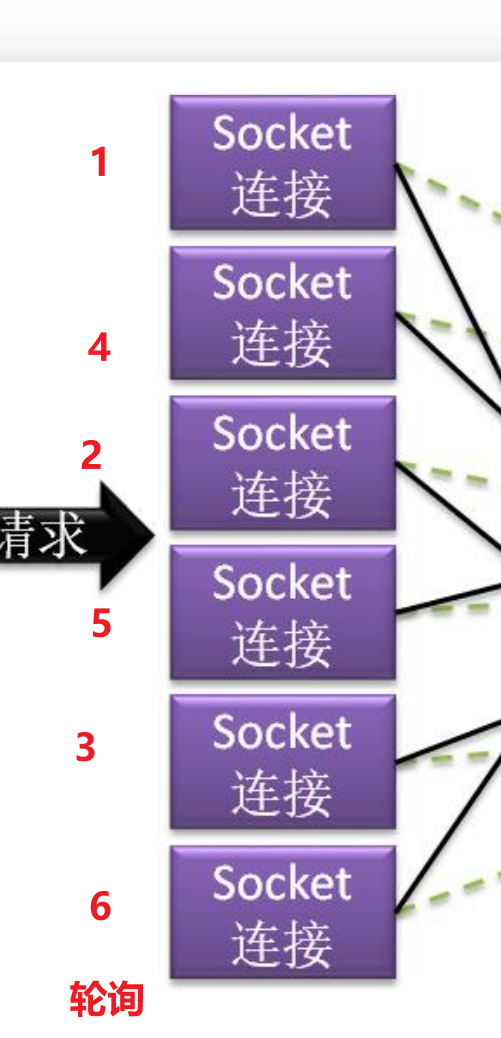
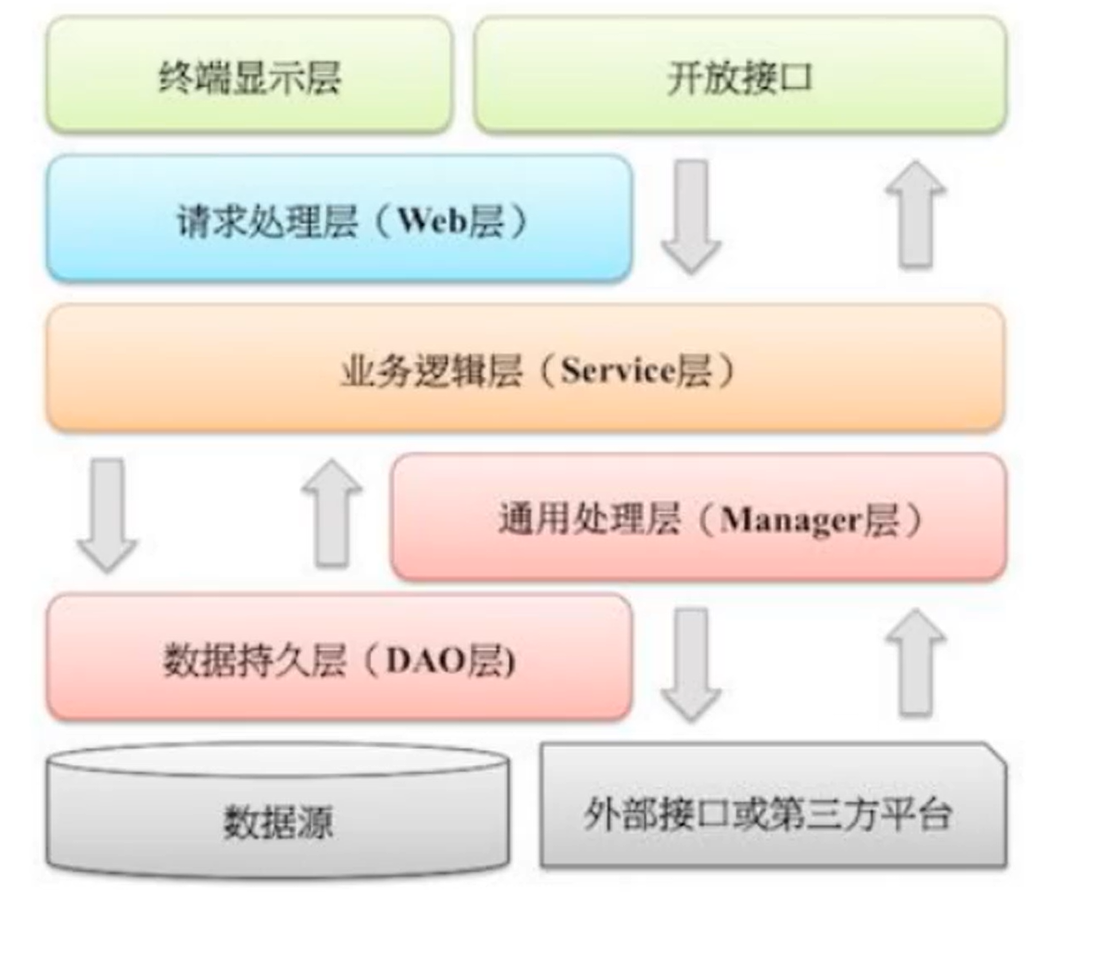
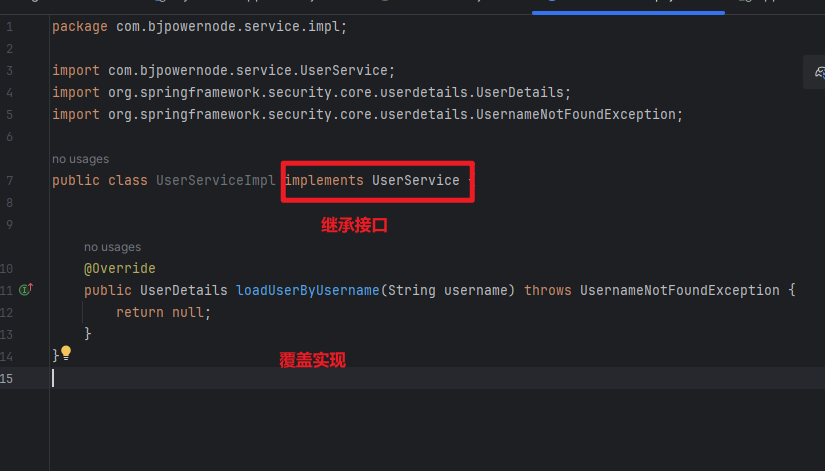
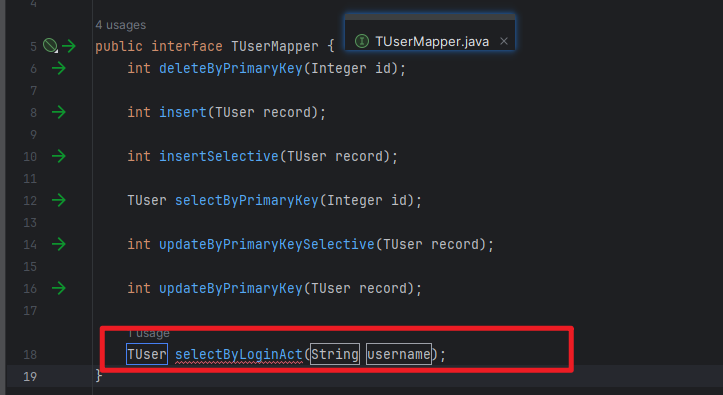
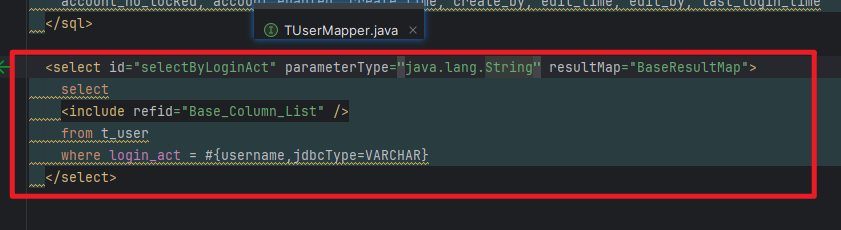
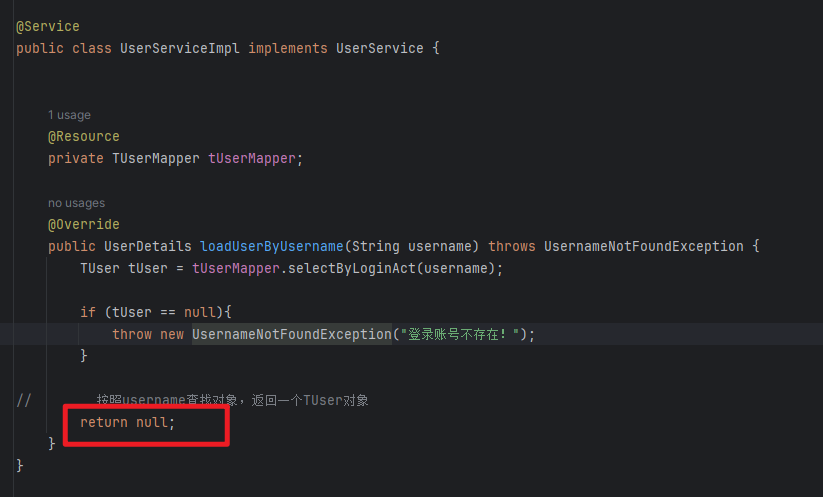
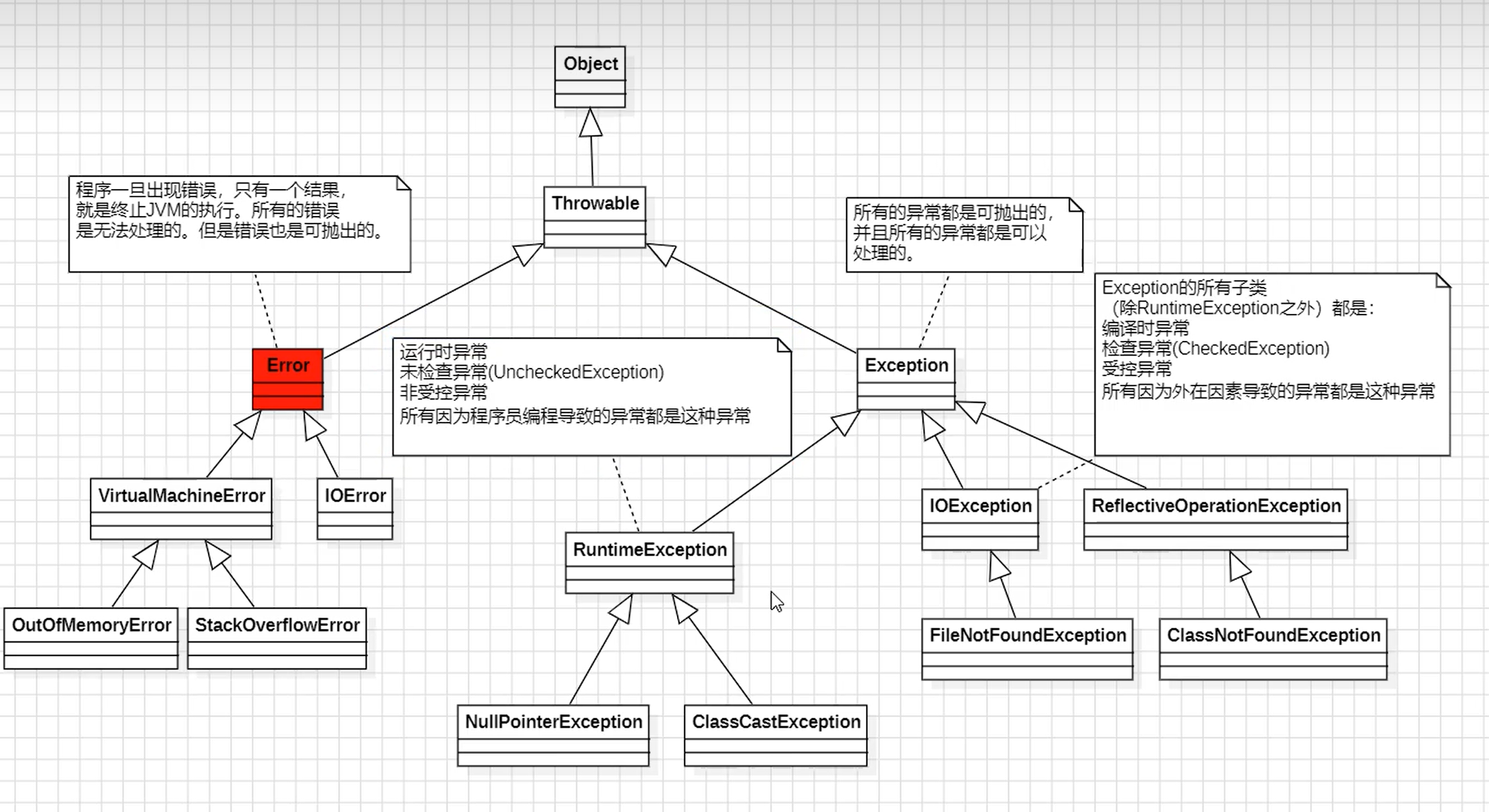
集合
集合概述
①什么是集合,有什么用?
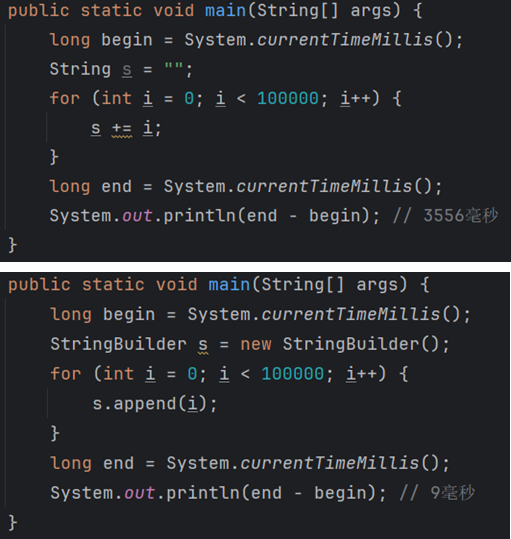
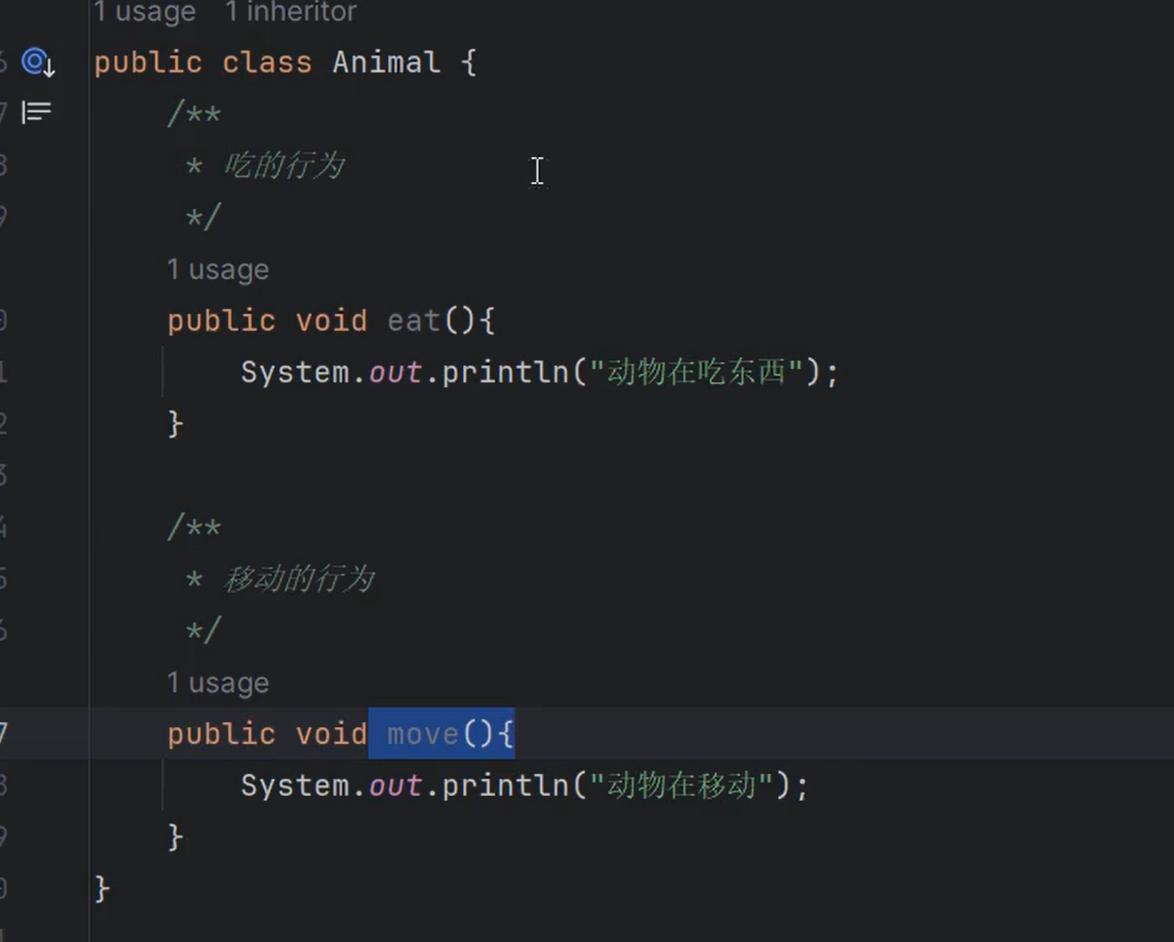
1.集合是一种容器,用来组织和管理数据的。非常重要。
2.Java的集合框架对应的这套类库其实就是对各种数据结构的实现。
3.每一个集合类底层采用的数据结构不同,例如ArrayList集合底层采用了数组,LinkedList集合底层采用了双向链表,HashMap集合底层采用了哈希表,TreeMap集合底层采用了红黑树。
4.我们不用写数据结构的实现了。直接用就行了。但我们需要知道的是在哪种场合下选择哪一个集合效率是最高的。
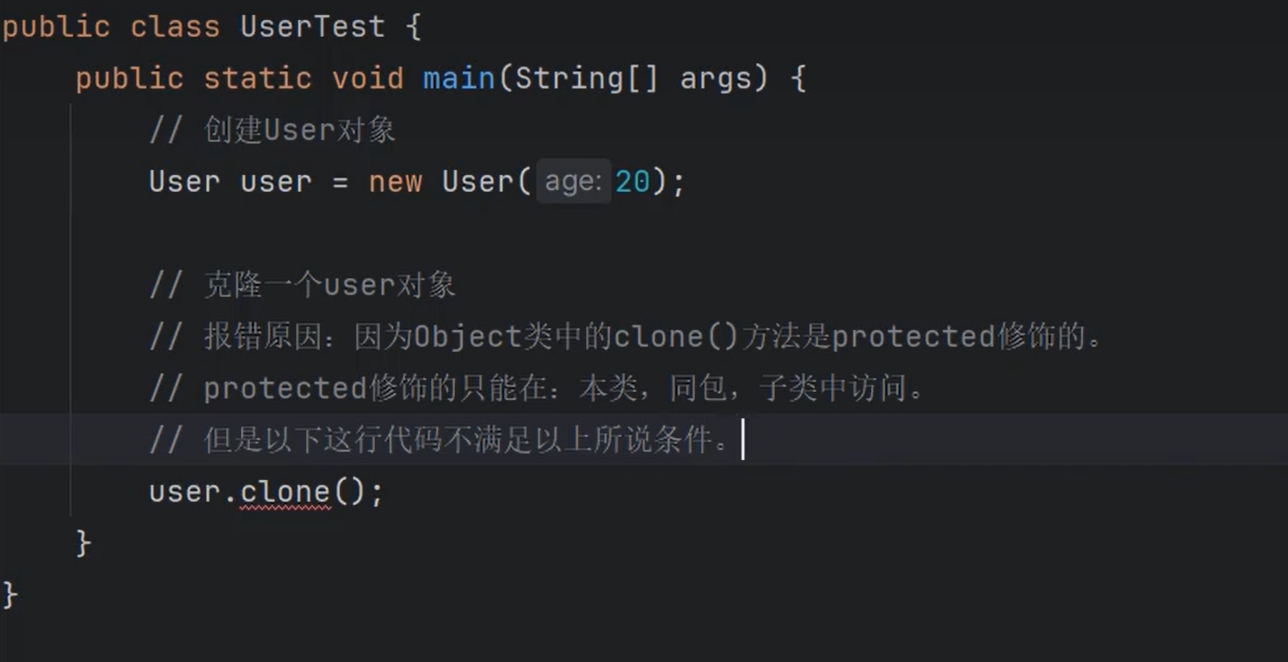
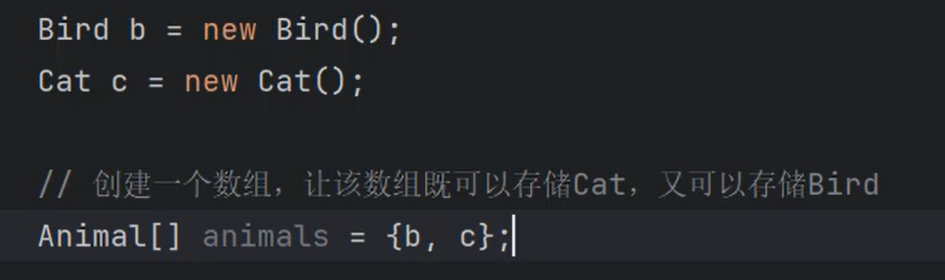
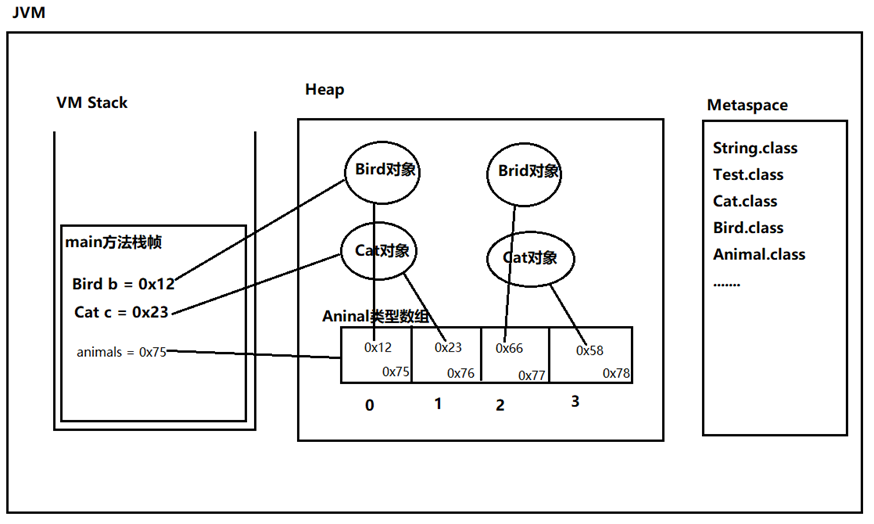
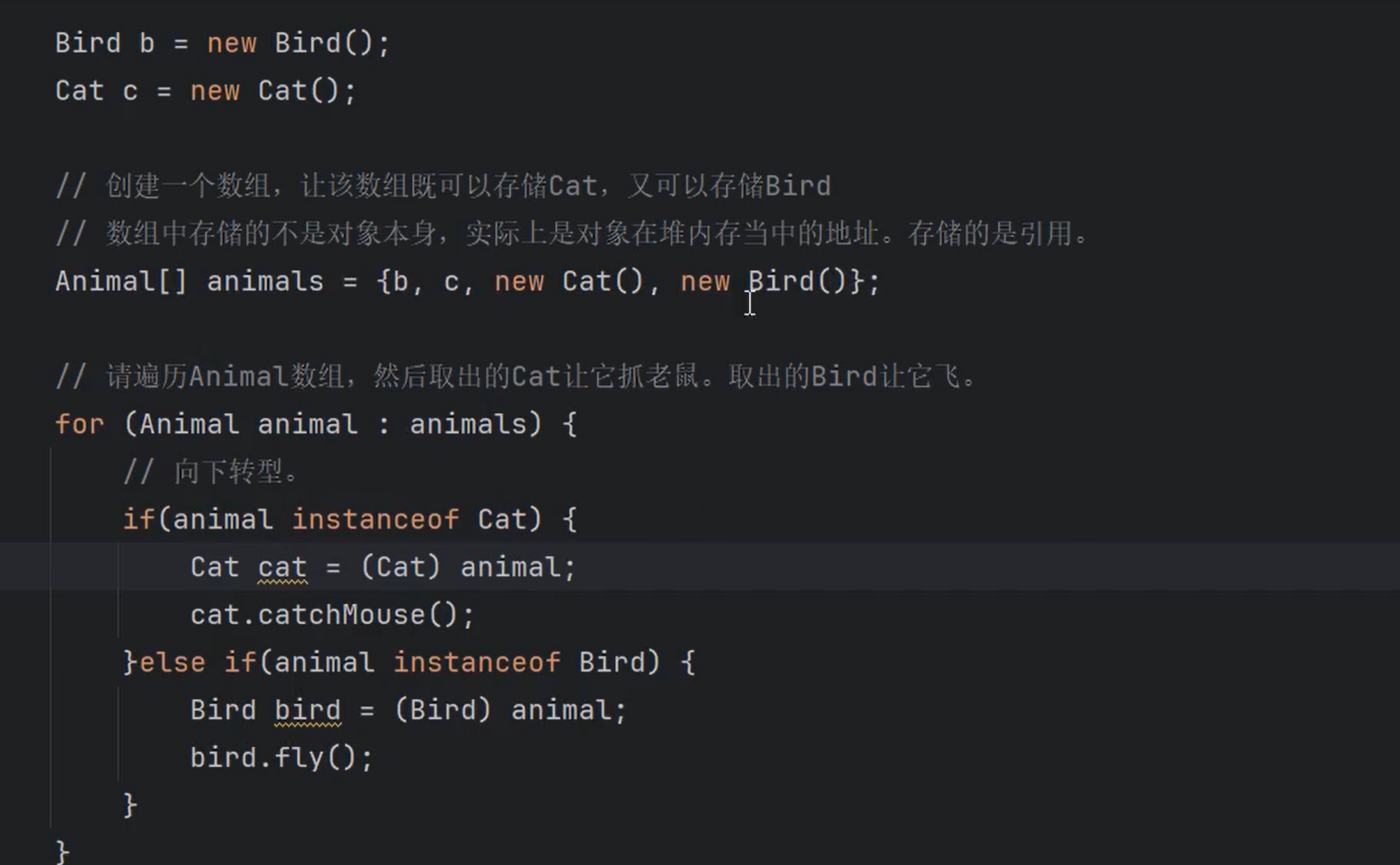
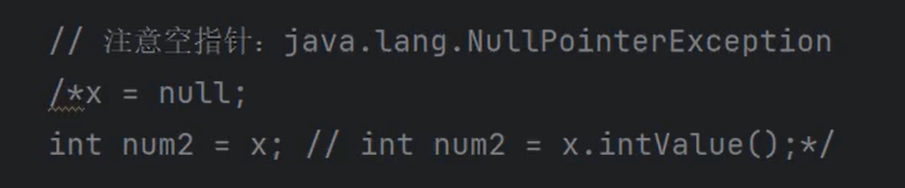
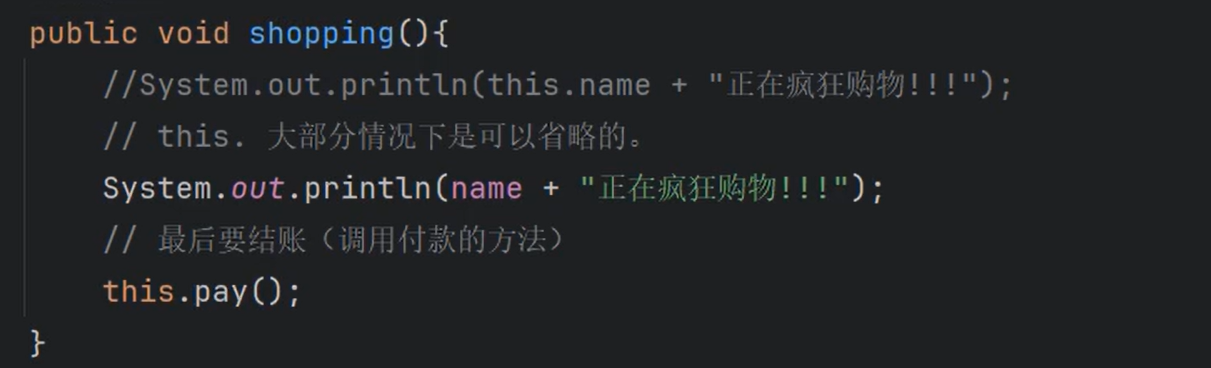
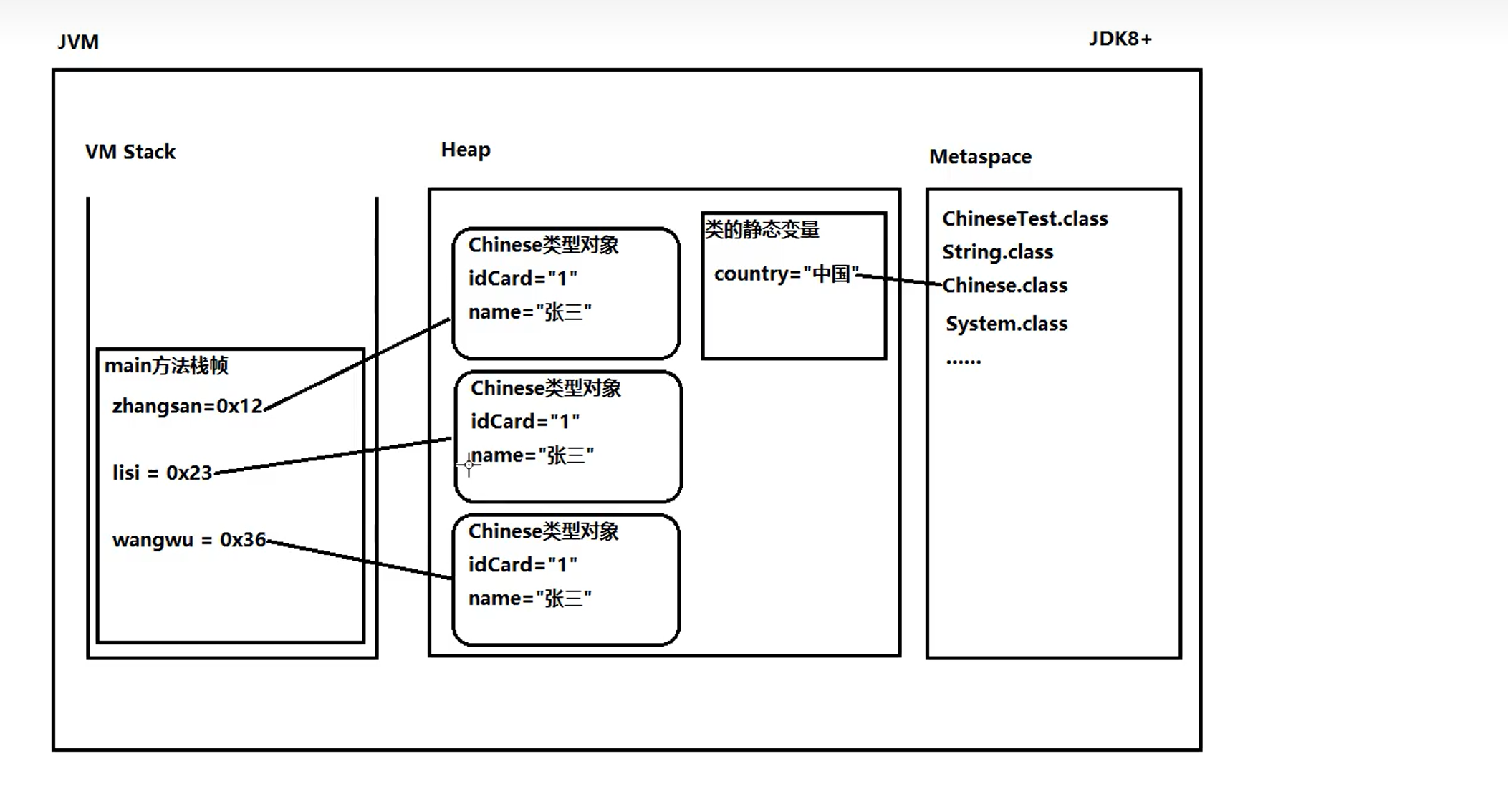
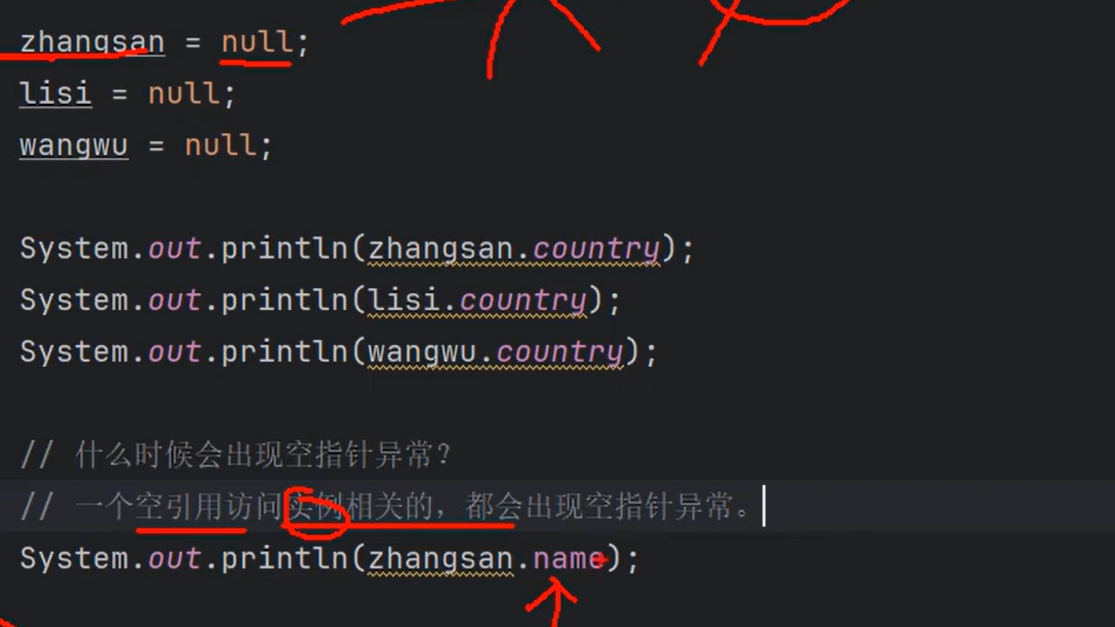
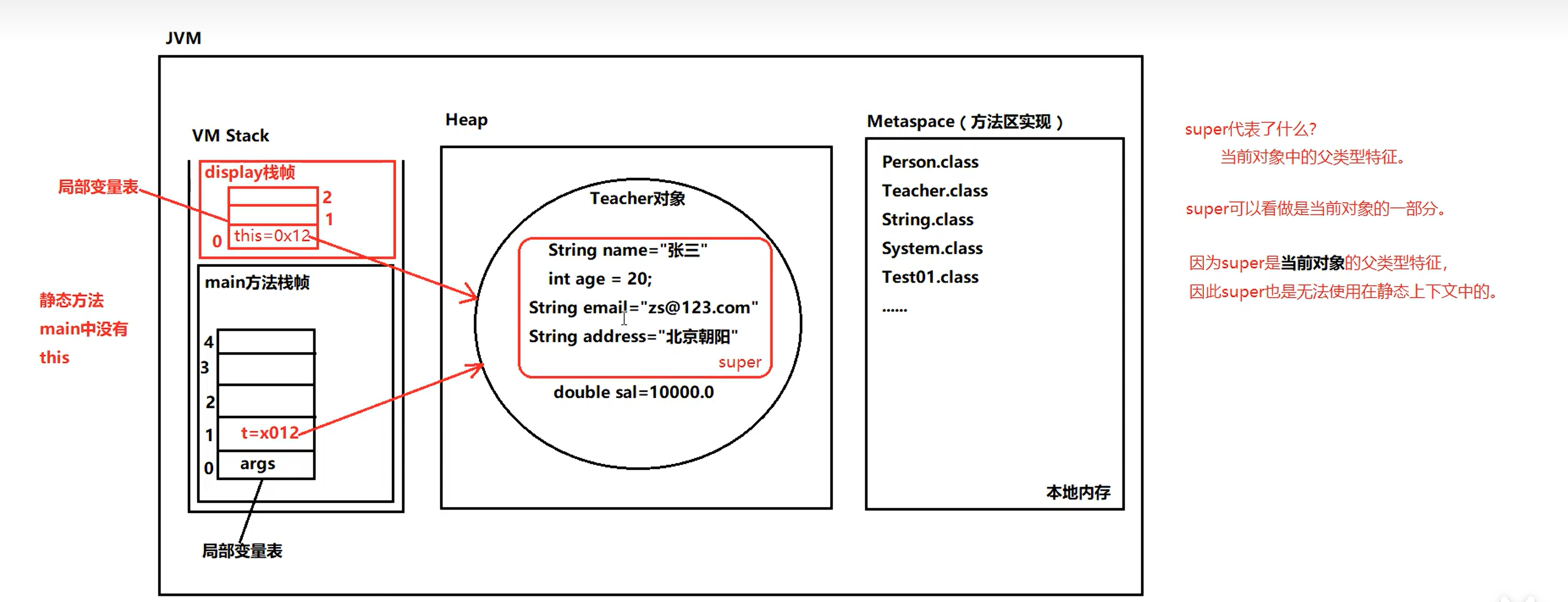
②集合中==存储的是引用==,不是把堆中的对象存储到集合中,是把==对象的地址==存储到集合中。
③默认情况下,==如果不使用泛型的话,集合中可以存储任何类型的引用,只要是Object的子类都可以存储。==
1
2
3
4
5
6
7
8
9
10
| public class CollectionTest01 {
public static void main(String[] args) {
Collection collection = new ArrayList();
collection.add(1);
collection.add(new Object());
collection.add("A");
}
}
|
④Java集合框架相关的类都在 java.util 包下。
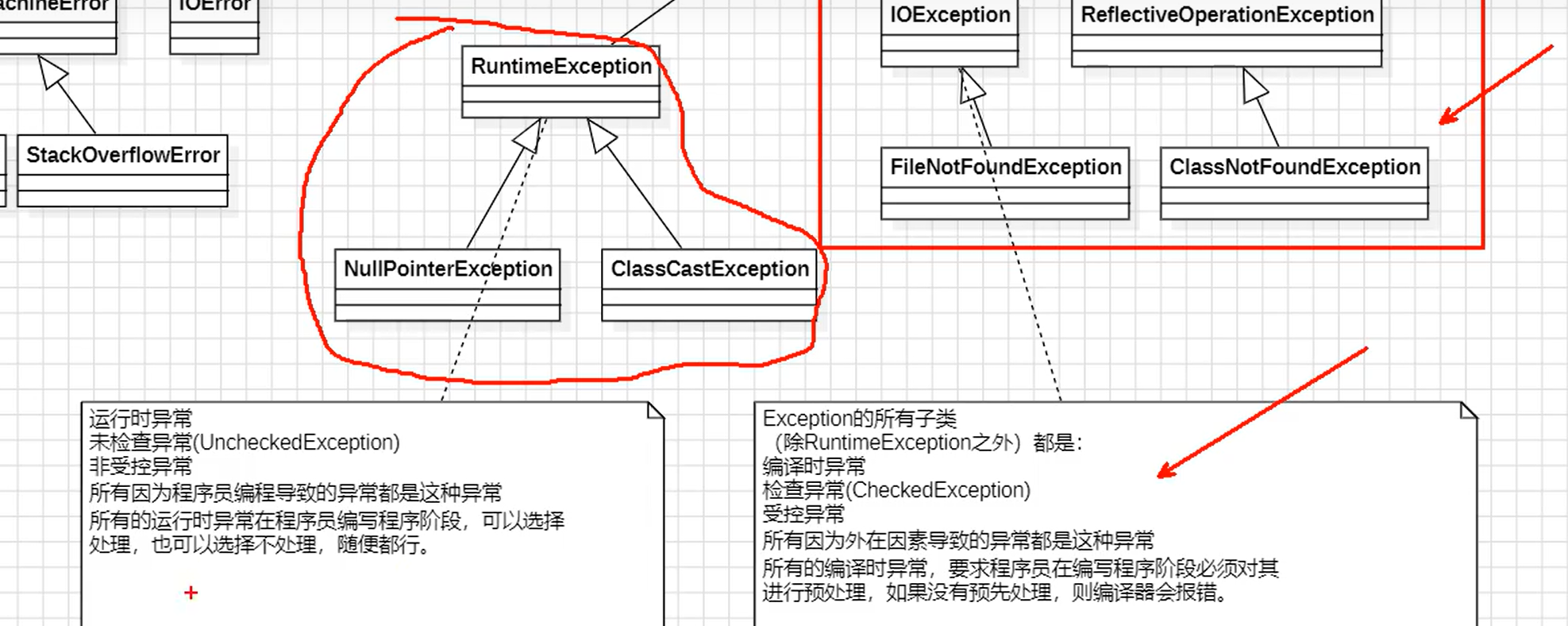
⑤Java集合框架分为两部分:
1.Collection结构:元素以单个形式存储。
2.Map结构:元素以键值对的映射关系存储。
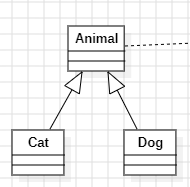
Collection继承结构
Collection接口是一个所有以单个方式存储元素的所有集合的超级接口,所有的以单个方式存储元素的这些集合都继承了Collection接口
Collection接口继承了iterable接口,所以都是可以遍历的,接口返回值iterator
Collection和iterator,依赖关系。
List重复,set不可以重复
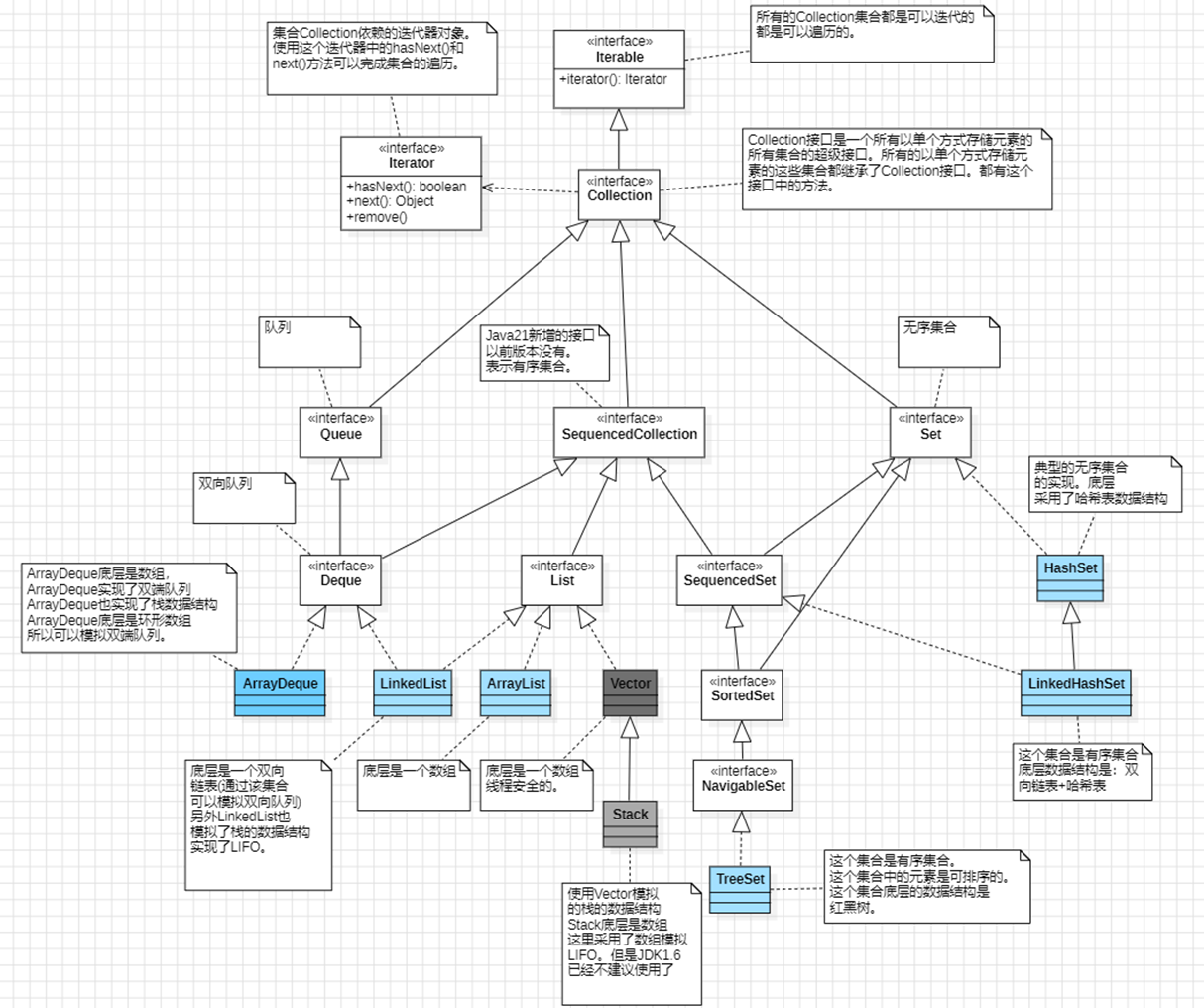
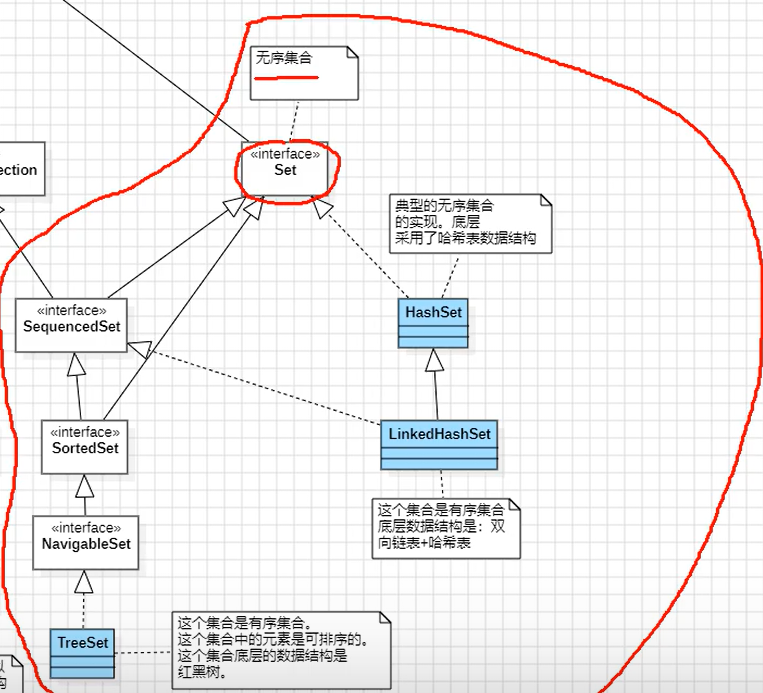
①SequencedCollection和SequencedSet接口都是Java21新增的接口。
②图中蓝色的是实现类。其它的都是接口。
③6个实现类中只有HashSet是无序集合。剩下的都是有序集合。
1.有序集合:集合中存储的元素**==有下标==或者集合中存储的元素是可排序的**。
2.无序集合:集合中存储的元素**==没有下标==并且集合中存储的元素也没有排序**。
④每个集合实现类对应的数据结构如下:
1.LinkedList:双向链表(不是队列数据结构,但使用它可以模拟队列)
2.ArrayList:数组
3.Vector:数组(线程安全的)
4.HashSet:哈希表
5.LinkedHashSet:双向链表和哈希表结合体
6.TreeSet:红黑树
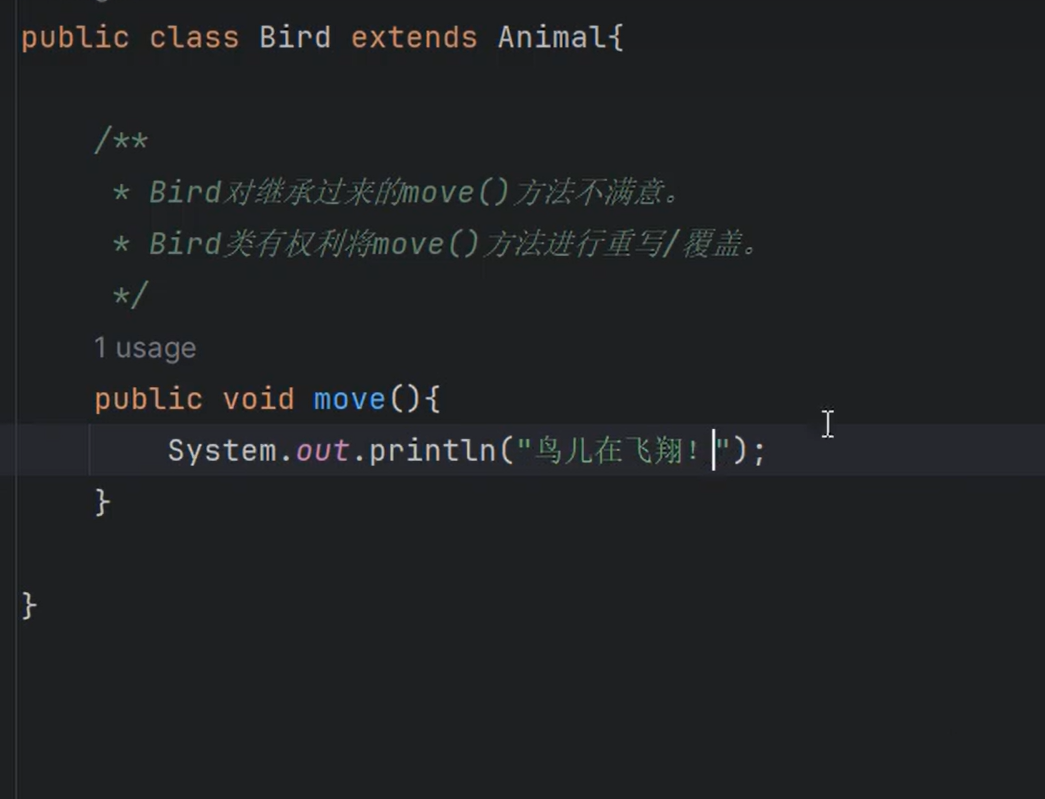
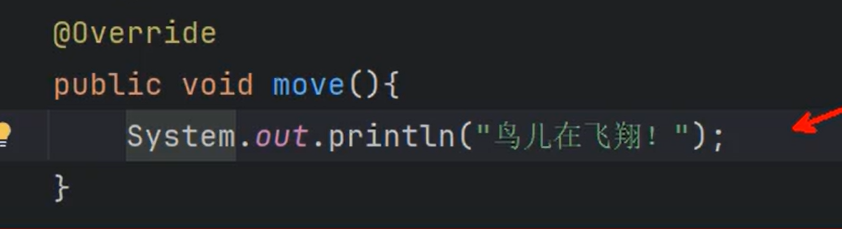
==⑤List集合中存储的元素可重复。Set集合中存储的元素不可重复。==
Collection接口(超级接口)
Collection接口的通用方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| boolean add(E e);
int size();
boolean addAll(Collection c);
boolean contains(Object o);
boolean remove(Object o);
void clear();
boolean isEmpty();
Object[] toArray();
|
Collection的遍历(集合的通用遍历方式)
①第一步:获取当前集合依赖的迭代器对象
1
2
| Iterator it = collection.iterator();
|
②第二步:编写循环,循环条件是:当前光标指向的位置是否存在元素。
1
2
3
4
| while(it.hasNext()){}
|
③第三步:如果有,将光标指向的当前元素返回,并且将光标向下移动一位。
1
2
3
4
| Object obj = it.next();
|
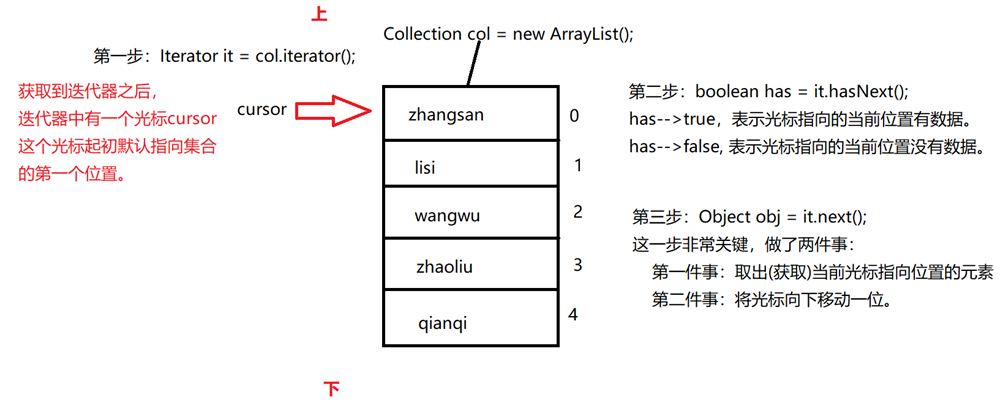
1
2
3
4
5
6
7
8
9
| for(Iterator it = collection.iterator();it.hasNext();){
Object obj = it.next();
System.out.println(obj);
}
Iterator i = collection.iterator();
while (i.hasNext()){
Object obj2 = i.next();
System.out.println(obj2);
}
|
SequencedCollection接口**==有序集合==**
所有的**==有序集合==**都实现了SequencedCollection接口
①SequencedCollection接口是Java21版本新增的。
②SequencedCollection接口==(有序集合)==中的方法:
1
2
3
4
5
6
7
8
9
10
11
12
| void addFirst(Object o):
void addLast(Object o):
Object removeFirst():
Object removeLast():
Object getFirst():
Object getLast():
SequencedCollection reversed();
|
==③ArrayList,LinkedList,Vector,LinkedHashSet,TreeSet,Stack 都可以调用这个接口中的方法。==
泛型(编译阶段的功能)
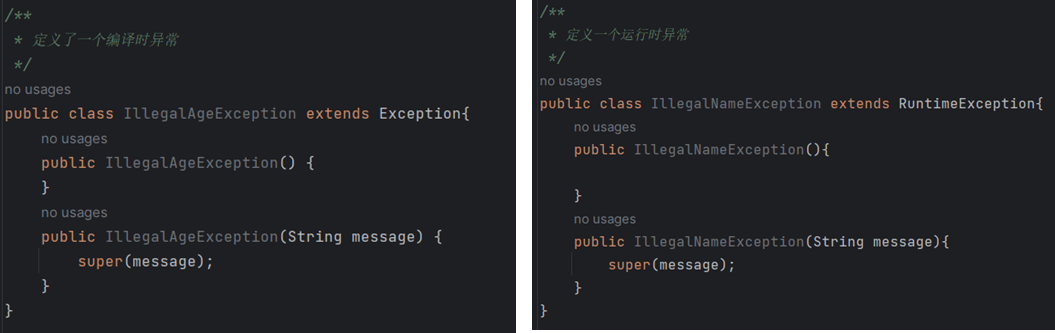
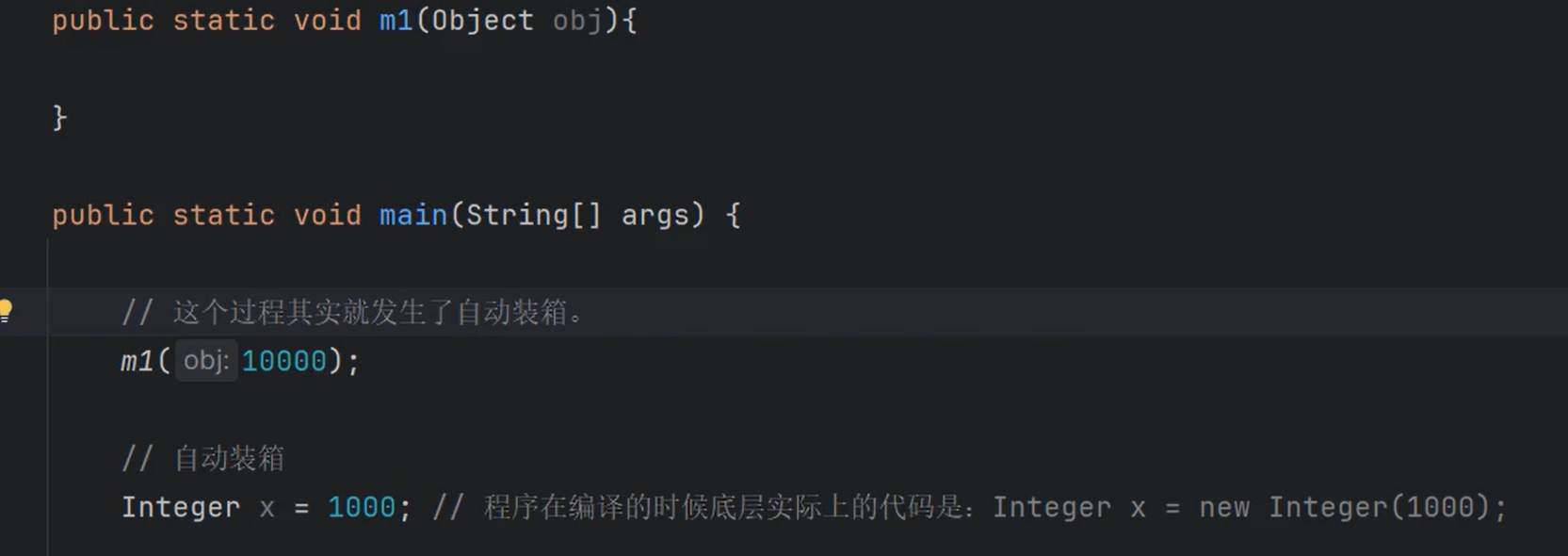
①泛型是Java5的新特性,属于编译阶段的功能。
②泛型可以让开发者在编写代码时指定集合中存储的数据类型
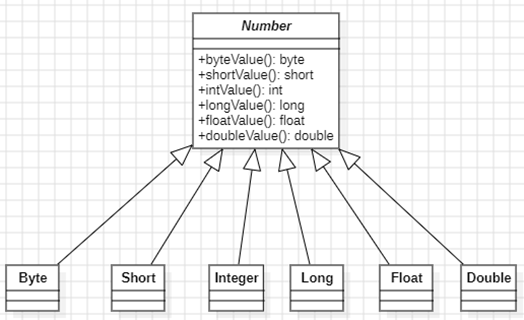
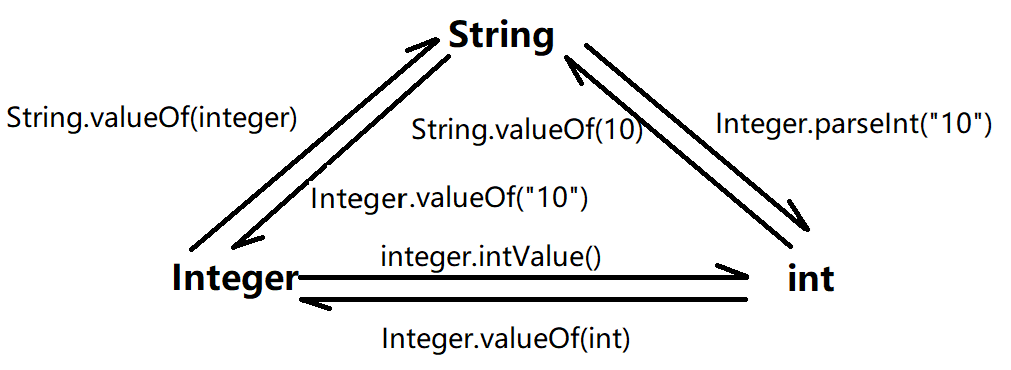
③泛型作用:
1.类型安全:指定了集合中元素的类型之后,**==编译器会在编译时进行类型检查==,如果尝试将错误类型的元素添加到集合中,就会在编译时报错,避免了在运行时出现类型错误的问题。**
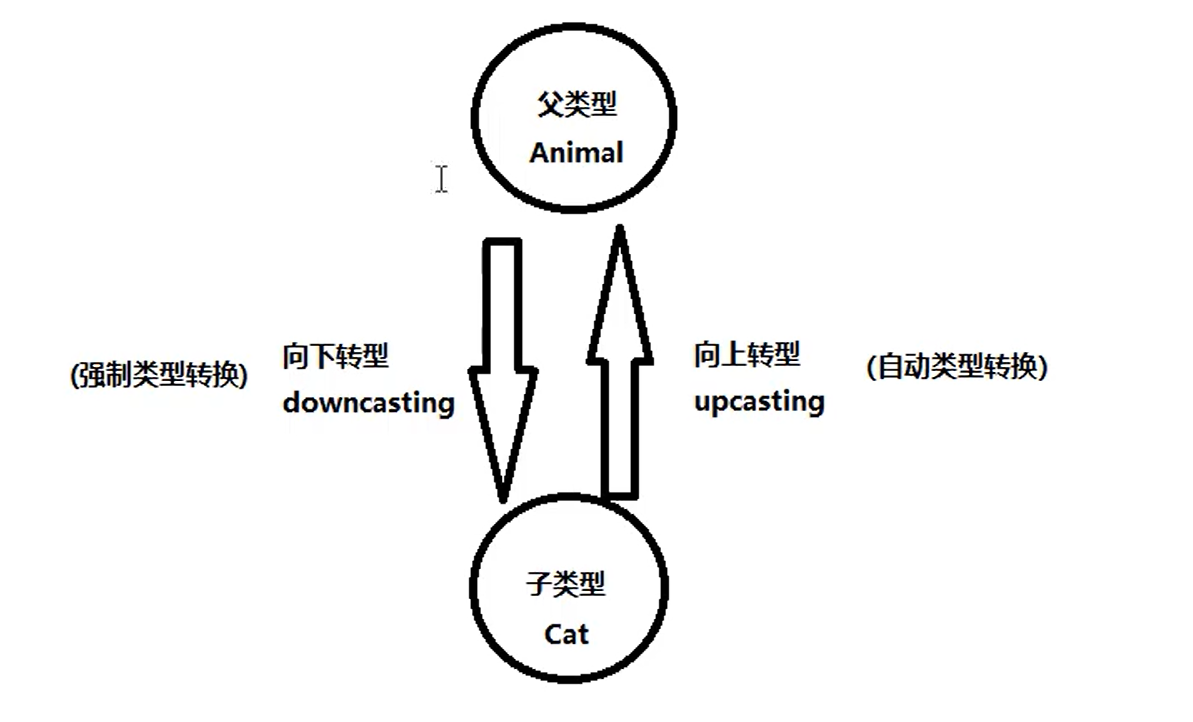
2.代码简洁:使用泛型可以简化代码,避免了繁琐的类型转换操作。比如,在没有泛型的时候,需要使用 Object 类型来保存集合中的元素,并在使用时==强制类型转换成实际类型==(向下转型),而有了泛型之后,只需要在定义集合时指定类型即可。
④在集合中使用泛型
1
2
3
4
5
6
|
Iterator i = collection.iterator();
while (i.hasNext()){
Object obj2 = i.next();
System.out.println(obj2);
}
|
1
2
|
Collection<String> strs = new ArrayList<String>();
|
这就表示该集合只能存储字符串,存储其它类型时编译器报错。
并且以上代码使用泛型后,避免了繁琐的类型转换,集合中的元素可以直接调用String类特有的方法。
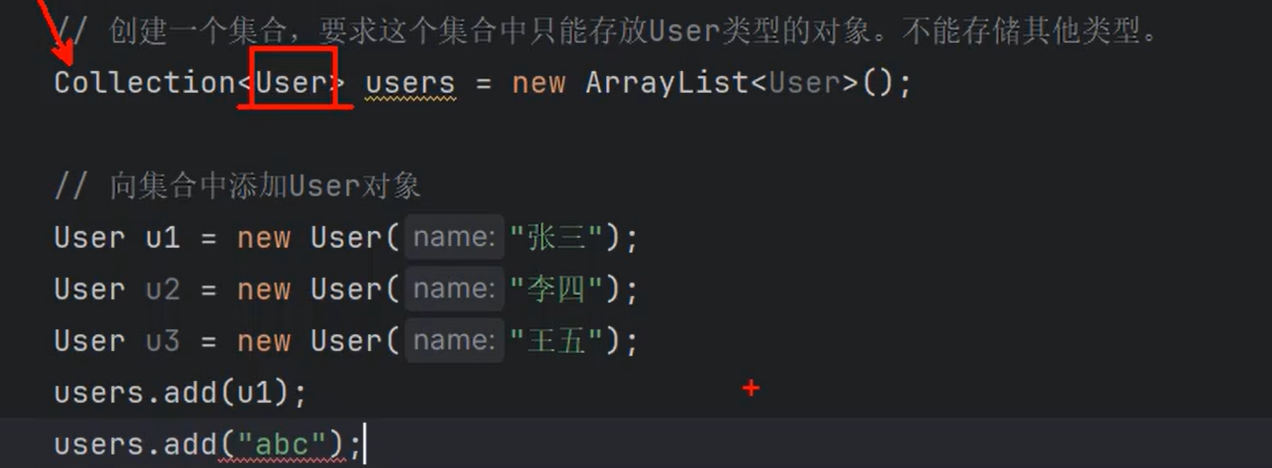
⑤Java7的新特性:钻石表达式
1
2
3
| Collection<String> strs = new ArrayList<String>();
Collection<String> strs = new ArrayList<>();
|
泛型的擦除与补偿(了解)
①泛型的出现提高了编译时的安全性,正因为**==编译时对添加的数据做了检查,则程序运行时才不会抛出类型转换异常。==**因此泛型本质上是编译时期的技术,是专门给编译器用的。
==泛型只是给Javac看的,在运行的时候,加载类的时候,会将泛型擦除掉(擦除之后的类型为Object类型),这个称为泛型擦除。==
②为什么要有泛型擦除呢?兼容低版本的JDK其本质是为了让JDK1.4和JDK1.5能够兼容同一个类加载器。在JDK1.5版本中,程序编译时期会对集合添加的元素进行安全检查,如果检查完是安全的、没有错误的,那么就意味着添加的元素都属于同一种数据类型,则加载类时就可以把这个泛型擦除掉,将泛型擦除后的类型就是Object类,这样擦除之后的代码就与JDK1.4的代码一致。
③由于加载类的时候,会默认将类中的泛型擦除为Object类型,所以添加的元素就被转化为Object类型,同时取出的元素也默认为Object类型。而我们获得集合中的元素时,按理说取出的元素应该是Object类型,为什么取出的元素却是实际添加的元素类型呢?
④这里又做了一个默认的操作,我们称之为**==泛型的补偿==。==在程序运行时,通过获取元素的实际类型进行强转,这就叫做泛型补偿(不必手动实现强制转换)。获得集合中的元素时,虚拟机 会根据获得元素的实际类型进行向下转型,也就是会恢复获得元素的实际类型,因此我们就无需手动执行向下转型操作,从本质上避免了抛出类型转换异常。==**
自定义泛型
在类上定义泛型


在方法上定义泛型
实例方法可以,静态方法不能直接用
因为实例方法跑的时候要new实例,刚好在创建的时候会确定泛型的类型。而静态方法不需要创建实例,不能确定类型
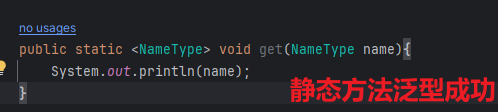
①在类上定义的泛型,在**==静态方法中无法使用==**。如果在静态方法中使用泛型,则需要再方法返回值类型前面进行泛型的声明。
②语法格式:<泛型1, 泛型2, 泛型3, …> 返回值类型 方法名(形参列表) {}
在接口上定义泛型
①语法格式:
1
2
| interface 接口名<泛型1,泛型2,...> {}
|
②例如:
1
2
3
4
5
6
7
| public interface Flayable<T>{}
public interface MyComparable <T>{
int compareTo(T o);
}
|
③实现接口时,如果知道具体的类型,则:
1
2
| public class MyClass implements Flyable<Bird>{}
public class CollectionTest03 implements MyComparable<CollectionTest03>{}
|
④实现接口时,如果不知道具体的类型,则:
1
| public class MyClass<T> implements Flyable<T>{}
|
泛型通配符
这个是从使用泛型的角度,不是从泛型定义的角度
别人把泛型定义好了,我来用
①泛型是在限定数据类型,当在集合或者其他地方使用到泛型后,那么这时一旦明确泛型的数据类型,那么在使用的时候只能给其传递和数据类型匹配的类型,否则就会报错。
②有的情况下,我们在定义方法时,根本无法确定集合中存储元素的类型是什么。为了解决这个“无法确定集合中存储元素类型”问题,那么Java语言就提供了泛型的通配符。
③通配符的几种形式:
- 无限定通配符,<?>,此处“?”可以为任意引用数据类型。不确定类型
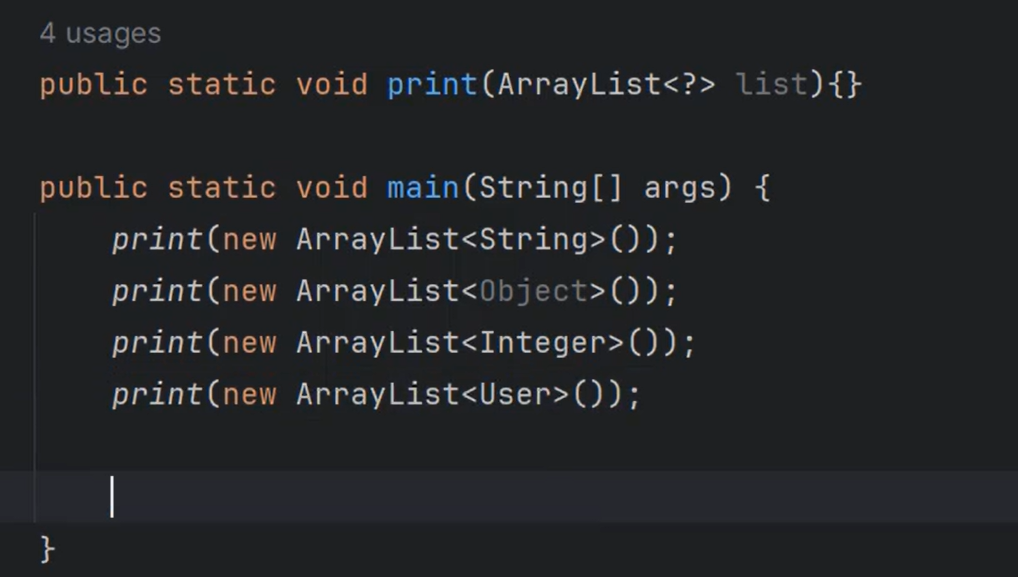
上限通配符,<? extends Number>,此处“?”必须为Number及其子类。
下限通配符,<? super Number>,此处“?”必须为Number及其父类。
集合迭代时删除元素
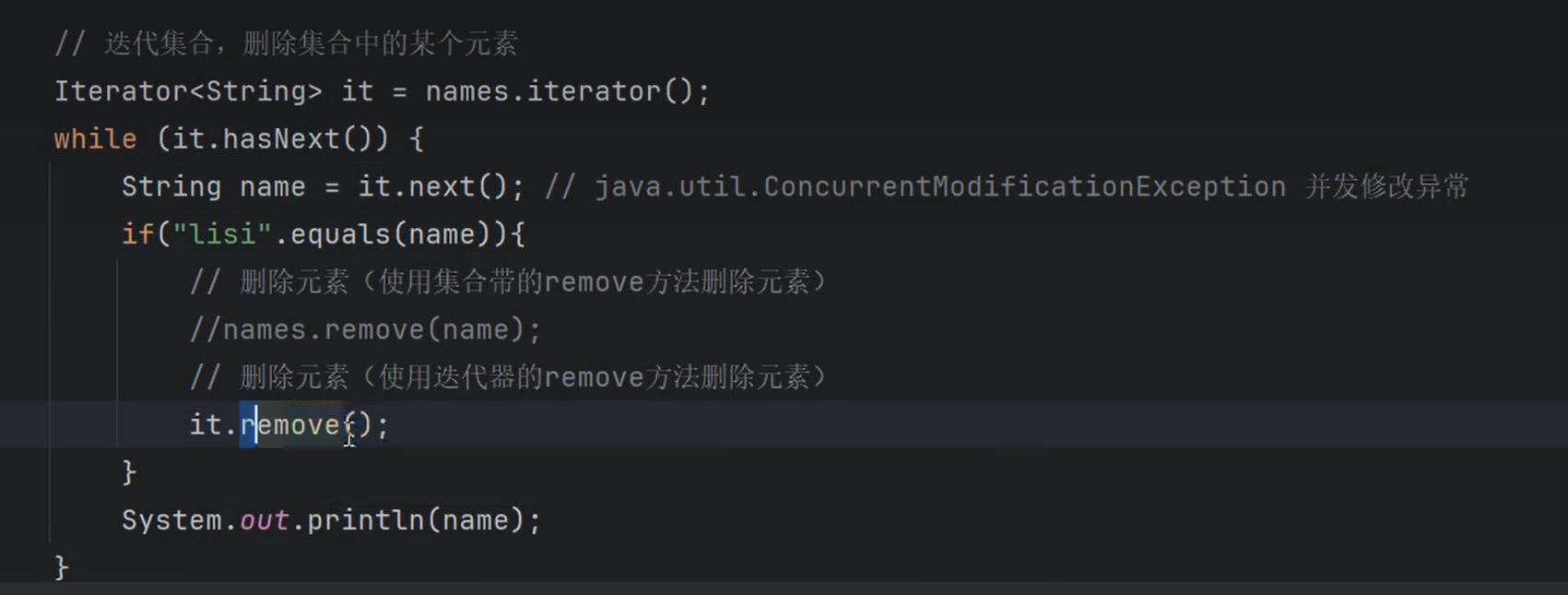
①迭代集合时删除元素
使用“集合对象.remove(元素)”:会出现ConcurrentModificationException异常。(并发修改异常)
使用“迭代器对象.remove()”:不会出现异常。
it.next前后的变化
②关于集合的并发修改问题
想象一下,有两个线程:A和B。A线程负责迭代遍历集合,B线程负责删除集合中的某个元素。当这两个线程同时执行时会有什么问题?
③如何解决并发修改问题:==fail-fast机制==
fail-fast机制又被称为:快速失败机制。也就是说只要程序发现了程序对集合进行了并发修改。就会立即让其失败,以防出现错误。
④fail-fast机制是如何实现的?以下是源码中的实现原理:
集合中设置了一个modCount属性,用来记录修改次数,使用集合对象执行增,删,改中任意一个操作时,modCount就会自动加1。
获取迭代器对象的时候,会给迭代器对象初始化一个expectedModCount属性。并且将expectedModCount初始化为modCount,即:int expectedModCount = modCount;
当使用集合对象删除元素时:modCount会加1。但是迭代器中的expectedModCount不会加1。而当迭代器对象的next()方法执行时,会检测expectedModCount和modCount是否相等,如果不相等,则抛出:ConcurrentModificationException异常。
当使用迭代器删除元素的时候:modCount会加1,并且expectedModCount也会加1。这样当迭代器对象的next()方法执行时,检测到的expectedModCount和modCount相等,则不会出现ConcurrentModificationException异常。
⑤注意:虽然我们当前写的程序是单线程的程序,并没有使用多线程,但是通过迭代器去遍历的同时使用集合去删除元素,这个行为将被认定为并发修改。
⑥结论:迭代集合时,删除元素要使用“迭代器对象.remove()”方法来删除,避免使用“集合对象.remove(元素)”。主要是为了避免ConcurrentModificationException异常的发生。
注意:迭代器的remove()方法删除的是next()方法的返回的那个数据。remove()方法调用之前一定是先调用了next()方法,如果不是这样的,就会报错。
List接口 有下标、有序
List接口常用方法
①List集合存储元素特点:有序可重复。
- 有序:是因为List集合中的元素都是有下标的,从0开始,以1递增。
存进去顺序
- 可重复:存进去1,还可以再存一个1。
②List接口下常见的实现类有:
- ArrayList:数组
- Vector、Stack:数组(线程安全的)
- LinkedList:双向链表
③List接口特有方法:(在Collection和SequencedCollection中没有的方法,只适合List家族使用的方法,这些方法都和下标有关系。)
- 1.void add(int index, E element) 在指定索引处插入元素
- 2.E set(int index, E element); 修改索引处的元素
- 3.E get(int index); 根据索引获取元素(通过这个方法List集合具有自己特殊的遍历方式:根据下标遍历)
- 4.E remove(int index); 删除索引处的元素
- 5.int indexOf(Object o); 获取对象o在当前集合中第一次出现时的索引。
- 6.int lastIndexOf(Object o); 获取对象o在当前集合中最后一次出现时的索引。
- 7.List subList(int fromIndex, int toIndex); 截取子List集合生成一个新集合(对原集合无影响)。[fromIndex, toIndex)
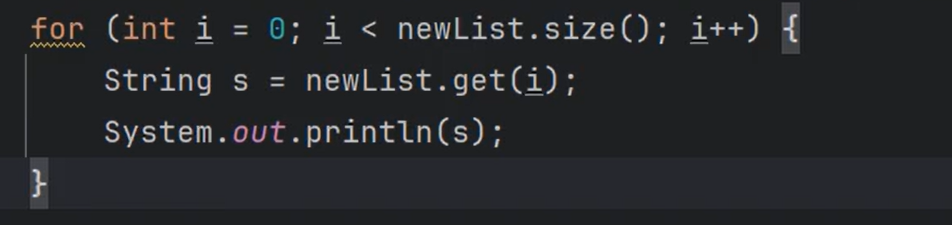
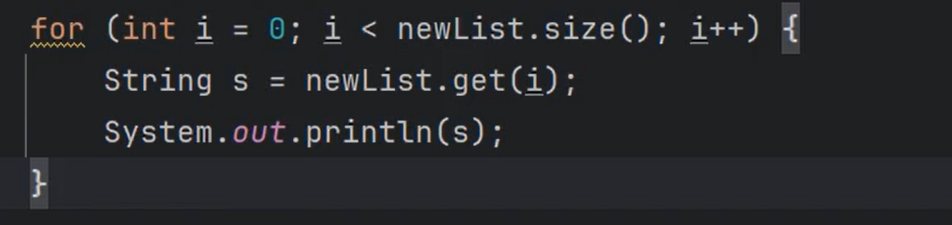
- 8.static List of(E… elements); 静态方法,返回包含任意数量元素的不可修改列表。(获取的集合是只读的,不可修改的。)
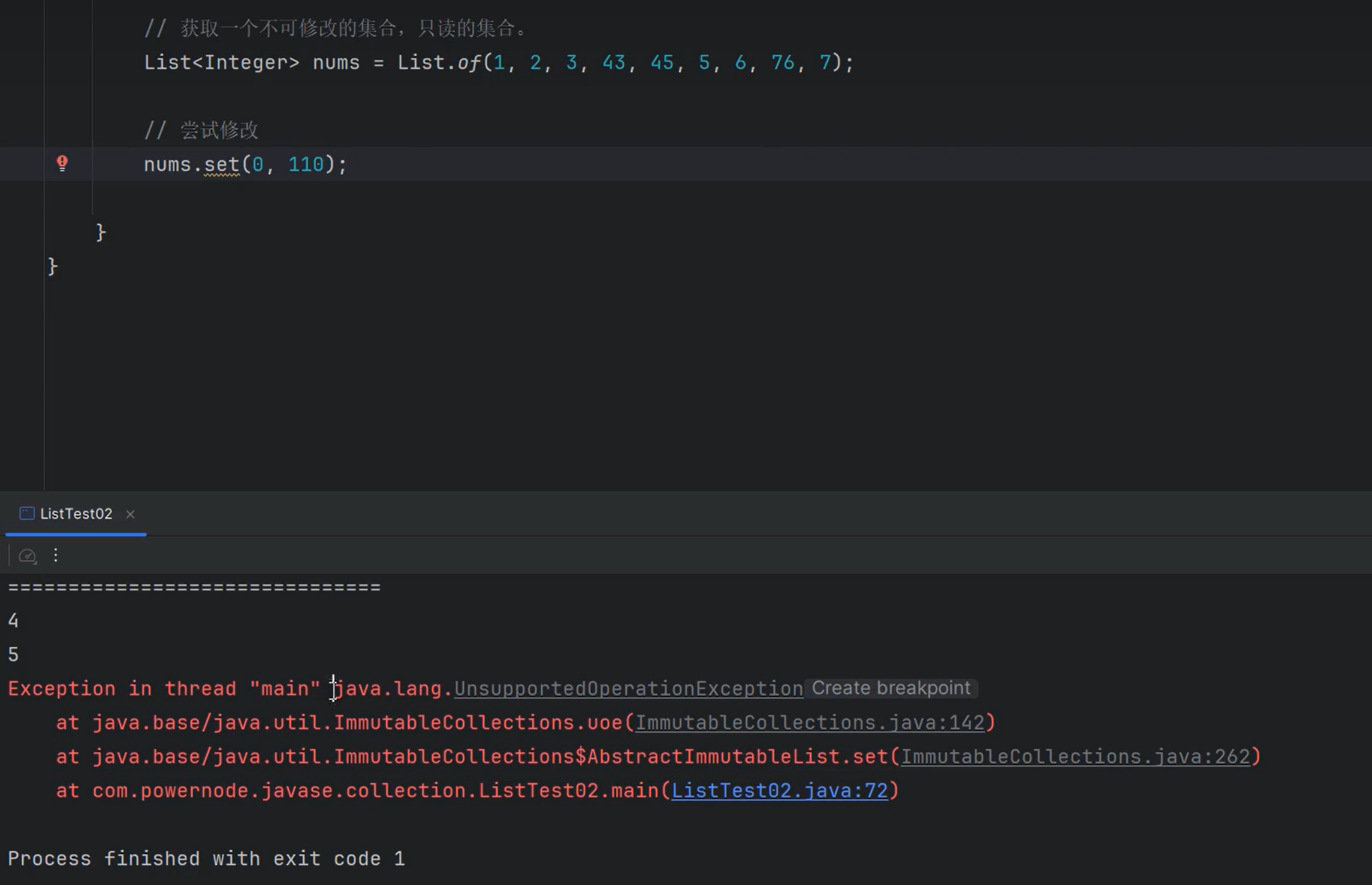
List接口特有迭代
①特有的迭代方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| ListIterator<E> listIterator();
ListIterator<E> listIterator(int index);
②ListIterator
boolean hasNext();
E next();
void remove();
void add(E e);
boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
void set(E e);
|
调用迭代器之前的remove也需要调用next()
List接口使用Comparator排序
①回顾数组中自定义类型是如何排序的?
所有自定义类型排序时必须指定排序规则。(int不需要指定,String不需要指定,因为他们都有固定的排序规则。int按照数字大小。String按照字典中的顺序)
如何给自定义类型指定排序规则?让自定义类型实现java.lang.Comparable接口,然后重写compareTo方法,在该方法中指定比较规则。
1
2
3
4
5
6
7
8
9
|
@Override
public int compareTo(CollectionTest03 o) {
return this.age - o.age;
}
|
②List集合的排序
两种方法:
1.一种是类继承comparable
1
2
3
4
| public class Person implements Comparable<Person>{
}
|
2.额外新建一个类
1
2
3
4
5
6
7
8
| public class PersonComparator implements Comparator<Person> {
@Override
public int compare(Person o1, Person o2) {
return o1.getAge()- o2.getAge();
}
}
persionList.sort(new PersonComparator());
|
default void sort(Comparator<? super E> c); 对List集合中元素排序可以调用此方法。
Class userClass = User.class;Constructor con = userClass.getDeclaredConstructor(Map.class);Type[] genericParameterTypes = con.getGenericParameterTypes();for(Type g :genericParameterTypes){ if(g instanceof ParameterizedType){ ParameterizedType parameterizedType = (ParameterizedType) g; Type[] actualTypeArguments = parameterizedType.getActualTypeArguments(); for(Type a : actualTypeArguments){ System.out.println(a.getTypeName()); } }}java
如何给自定义类型指定比较规则?可以对Comparator提供一个实现类,并重写compare方法来指定比较规则。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| package com.ljy.CollectionTest.ListTest;
import java.util.ArrayList;
import java.util.List;
public class ListSort {
public static void main(String[] args) {
Person p1 = new Person("张三",18);
Person p2 = new Person("李四",20);
Person p3 = new Person("王五",15);
Person p4 = new Person("赵六",19);
Person p5 = new Person("孙七",23);
List<Person> list = new ArrayList<>();
list.add(p1);
list.add(p2);
list.add(p3);
list.add(p4);
list.add(p5);
list.sort(new PersonComparator());
for (Person person : list){
System.out.println(person.getName()+":"+person.getAge());
}
}
}
|
1
2
3
4
5
6
| persionList.sort(new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
return o1.getAge()-o2.getAge();
}
});
|
当然,Comparator接口的实现类也可以采用**==匿名内部类==**的方式。
ArrayList1.5倍扩容
①ArrayList集合底层采用了数组这种数据结构。
②ArrayList集合优点:
底层是数组,因此根据下标查找元素的时间复杂度是O(1)。因此检索效率高。
底层是数组,内存存储是连续的,有下标、有偏移量,就可以用数学表达式很快的实现各种元素的访问
③ArrayList集合缺点:
随机增删元素效率较低。不过只要数组的容量还没满,对末尾元素进行增删,效率不受影响。
④ArrayList集合适用场景:
需要频繁的检索元素,并且很少的进行随机增删元素时建议使用。
⑤ArrayList默认初始化容量?
从源码角度可以看到,当调用无参数构造方法时,初始化容量0,
当第一次调用add方法时将ArrayList容量初始化为10个长度。
⑥ArrayList集合扩容策略?
底层扩容会创建一个新的数组,然后使用数组拷贝。扩容之后的新容量是原容量的1.5倍。
如果正常情况下,就是10+5;15+15/2
⑦ArrayList集合源码分析:
- 属性分析
- 构造方法分析(使用ArrayList集合时最好也是预测大概数量,给定初始化容量,减少扩容次数。)
- 添加元素:向末尾加add
- 修改元素 set 返回olddata
- 插入元素 中间插入,存在位移
- 删除元素
添加删除都调用了arraycopy,增加效率
Vector2倍扩容
vector和stack都是线程安全的,但是效率不是很高,现在也有更好的控制线程安全的方法
①Vector底层也是数组,和ArrayList相同。
②不同的是Vector几乎所有的方法都是线程同步的
vector所有方法都被synchronized修饰:线程排队执行,不能并发),因此Vector是**==线程安全==**的,但由于效率较低,很少使用。因为控制线程安全有新方式。
③Vector初始化容量:10
④Vector扩容策略:扩容之后的容量是原容量的2倍。
链表存储结构link
链表
xxxxxxxxxx // 创建一个线程池对象(线程池中有3个线程)ExecutorService executorService = Executors.newFixedThreadPool(3);// 将任务交给线程池(你不需要触碰到这个线程对象,你只需要将要处理的任务交给线程池即可。)executorService.submit(new Runnable() { @Override public void run() { for (int i = 0; i < 10; i++) { System.out.println(Thread.currentThread().getName() + “—>” + i); } }});// 最后记得关闭线程池executorService.shutdown();java
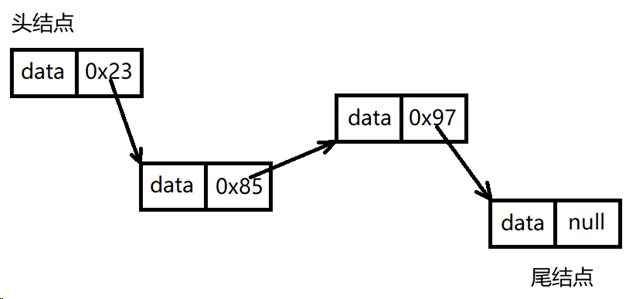
每个节点维护两个部分,一个头一个指针指向下一个节点。
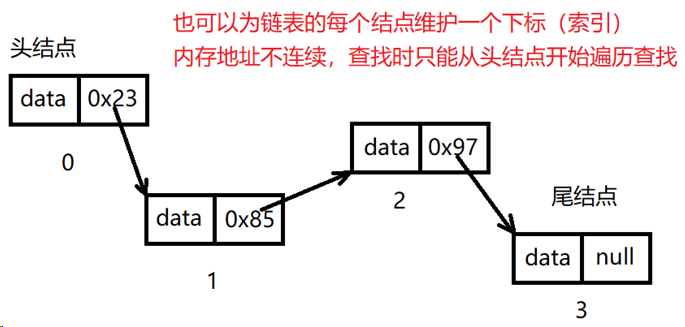
内存地址不连续
优点:,增删效率O(1)
缺点:检索的效率很慢,挨个找,越大越慢
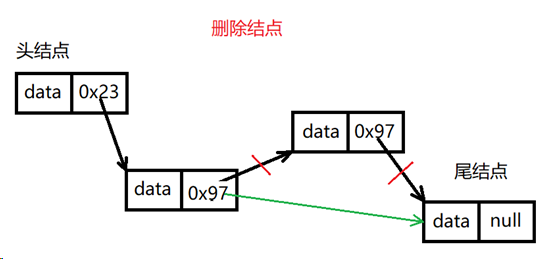
删除结点O(1)
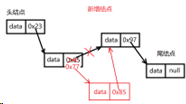
新增结点O(1)
②双向链表
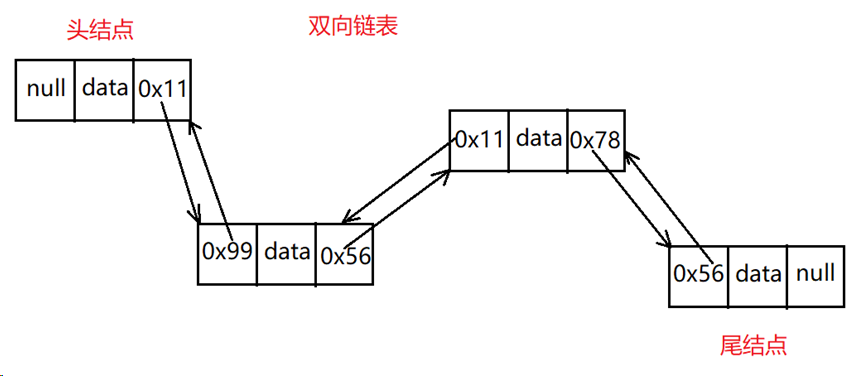
优点:查找效率比单向的快
缺点:查找效率虽然比单向的快,但是还是慢
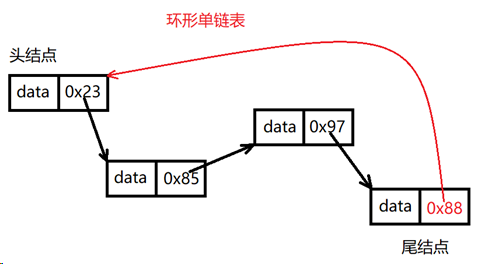
③环形链表
环形单链表
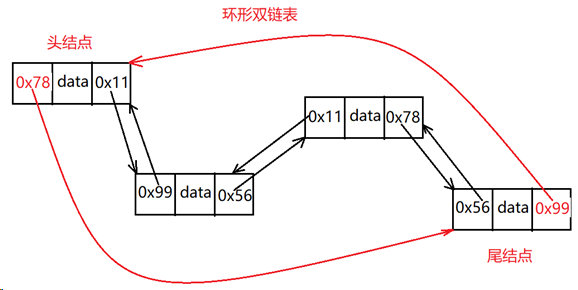
环形双链表
④链表优点:
因为链表节点在空间存储上,内存地址不是连续的。因此删除某个节点时不需要涉及到元素位移的问题。==因此随机增删元素效率较高。时间复杂度O(1)==
⑤链表缺点:
==链表中元素在查找时,只能从某个节点开始顺序查找,因为链表节点的内存地址在空间上不是连续的。链表查找元素效率较低,时间复杂度O(n)==
⑥链表的适用场景:
需要频繁进行随机增删,但很少的查找的操作时。
LinkedList
①LinkedList是一个**==双向链表==**
注意,虽然是双向链表,但是还是只能从头或者从尾开始寻找,效率还是非常的慢
②源码分析:
属性分析
构造方法分析
添加元素:
add ,向末尾添加元素 addlast
修改元素
set: 查找、修改
set()方法返回的是改前的值oldvalue
插入元素
add(index):
删除元素
remove()
③手写单向链表
栈数据结构//使用的很少了,不建议使用了
这里是使用一个数组实现的
①LIFO原则(Last In,First Out):后进先出
②实现栈数据结构,可以用数组来实现,也可以用双向链表来实现。
③用数组实现的代表是:Stack、ArrayDeque
- Stack:Vetor的子类,实现了栈数据结构,除了具有Vetor的方法,还扩展了其它方法,完成了栈结构的模拟。不过在JDK1.6(Java6)之后就不建议使用了,因为它是线程安全的,太慢了。Stack中的方法如下:
1
2
3
4
5
6
7
| E push(E item):
E pop():
int search(Object o):
E peek():
|
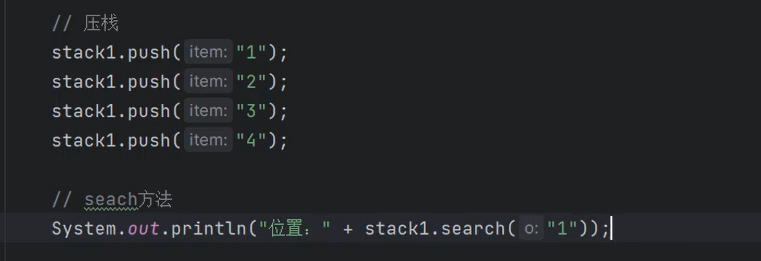
返回4,search()栈顶是1,下一个是2……..
- ArrayDeque
④用链表实现的代表是:LinkedList
LinkedList实现了栈,可以直接创建Linklist进行pushback
队列数据结构queue(FIFO)

①queue的删除插入
queue队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作(poll),而在表的后端(rear)进行插入操作(offer)。
队列是一种操作受限制的线性表。进行插入操作(入口)的端称为队尾,进行删除操作(出口)的端称为队头。
②队列是一种先进先出(First In First Out)的线性表,简称FIFO表
队列的插入操作只能在队尾操作,队列的删除操作只能在队头操作,因此
③Queue接口是一种基于FIFO(先进先出)的数据结构,而Deque接口则同时支持FIFO和LIFO(后进先出)两种操作。因此Deque接口也被称为“双端队列”。
④Java集合框架中队列的实现:
- ①链表实现方式:LinkedList
- ②数组实现方式:ArrayDeque
- ③LinkedList和ArrayDeque都实现了Queue、Deque接口,因此这两个类都具备队列和双端队列的特性。
- ④LinkedList底层是基于双向链表实现的,因此它天然就是一个双端队列,既支持从队尾入队,从队头出队,也支持从队头入队,从队尾出队。
- 用Deque的实现方式来说,就是它既实现了队列的offer()和poll()方法,也实现了双端队列的offerFirst()、offerLast()、pollFirst()和pollLast()方法等。
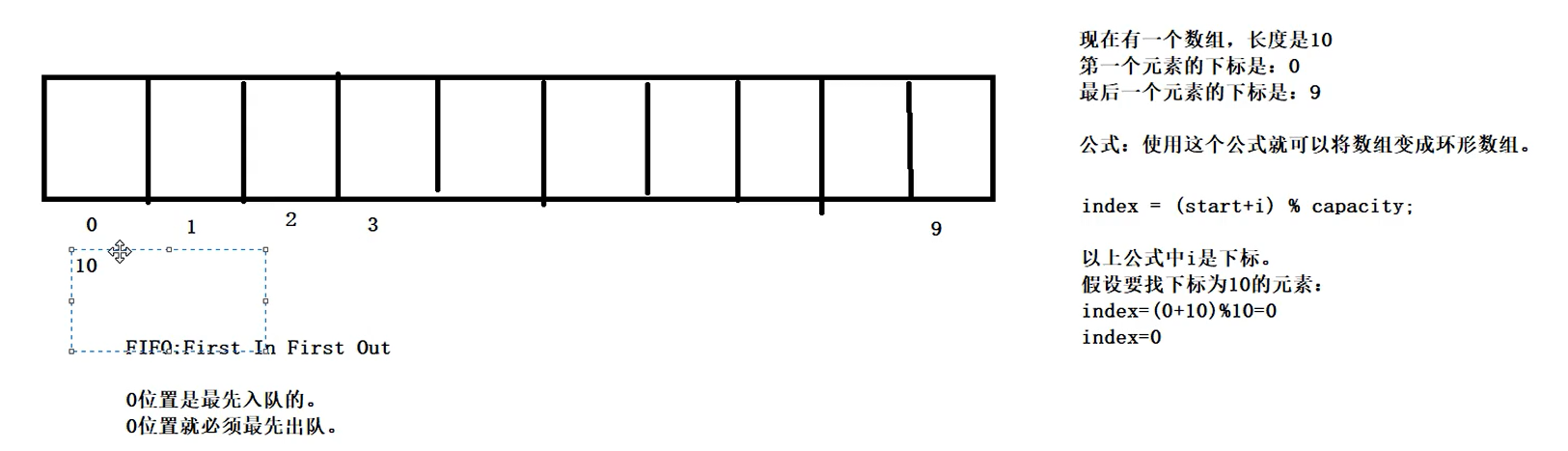
- ⑤ArrayDeque底层是使用环形数组实现的,也是一个双端队列。它比LinkedList更加高效,因为在数组中随机访问元素的时间复杂度是O(1),而链表中需要从头或尾部遍历链表寻找元素,时间复杂度是O(N)。
- 循环数组:index = (start + i) % capacity
①Queue接口基于Collection扩展的方法包括:
1
2
3
4
5
6
7
8
9
| boolean offer(E e); 入队。
E poll(); 出队,如果队列为空,返回null。
E remove(); 出队,如果队列为空,抛异常。
E peek(); 查看队头元素,如果为空则返回null。
E element(); 查看对头元素,如果为空则抛异常。
|
①Deque接口基于Queen接口扩展的方法包括:
以下2个方法可模拟队列:
1
2
3
4
5
6
7
8
9
10
11
12
13
| boolean offerLast(E e); 从队尾入队
E pollFirst(); 从队头出队
以下4个方法可模拟双端队列:
boolean offerLast(E e); 从队尾入队
E pollFirst(); 从队头出队
boolean offerFirst(E e); 从队头入队
E pollLast(); 从队尾出队
|
另外offerLast+pollLast或者pollFirst+offerFirst可以模拟栈数据结构。或者也可以直接调用push/pop方法。
Map继承结构(独立的)
set集合是map集合的一部分
map和collection之间没有继承关系
无序指的是插入顺序和实际的存储顺序不一致
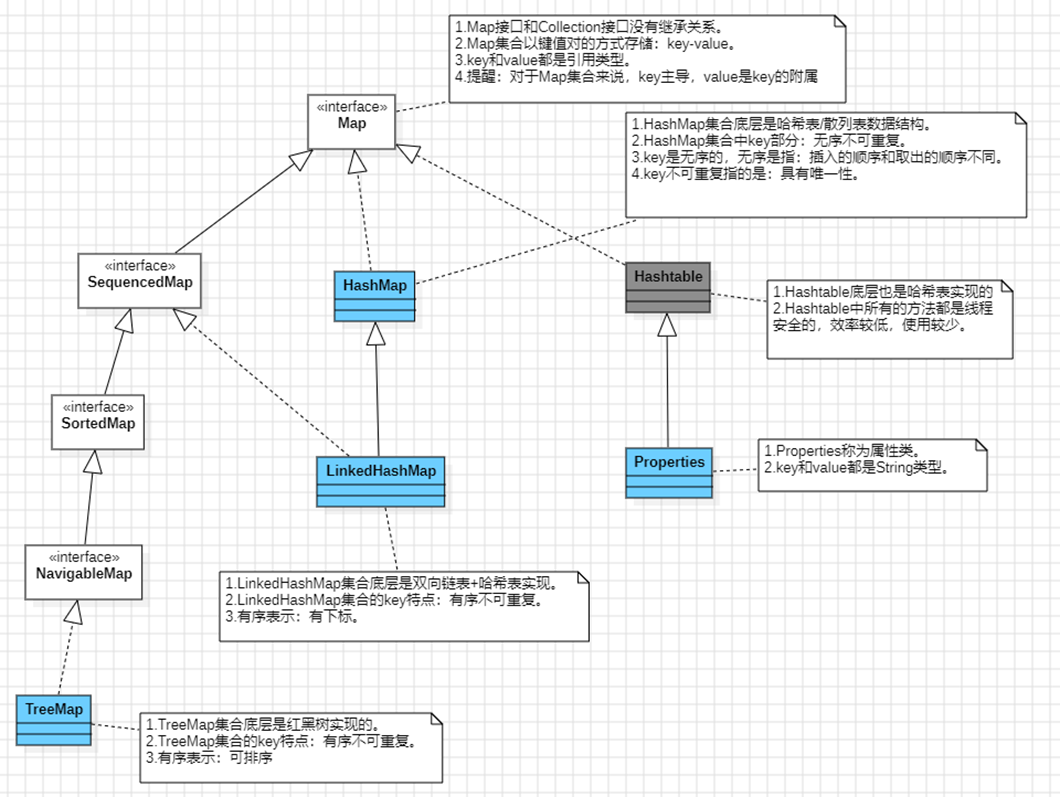
- ①Map集合以key和value的键值对形式存储。key和value存储的都是引用。
- ②Map集合中key起主导作用。value是附属在key上的。
- ③SequencedMap是Java21新增的。
- ④LinkedHashMap和TreeMap都是有序集合。(key是有序的)
- ⑤HashMap,Hashtable,Properties都是无序集合。(key是无序的)
- ⑥Map集合的key都是不可重复的。key重复的话,value会覆盖。
- ⑦HashSet集合底层是new了一个HashMap。往HashSet集合中存储元素实际上是将元素存储到HashMap集合的key部分。HashMap集合的key是无序不可重复的,因此HashSet集合就是无序不可重复的。HashMap集合底层是哈希表/散列表数据结构,因此HashSet底层也是哈希表/散列表。
- ⑧TreeSet集合底层是new了一个TreeMap。往TreeSet集合中存储元素实际上是将元素存储到TreeMap集合的key部分。TreeMap集合的key是不可重复但可排序的,因此TreeSet集合就是不可重复但可排序的。TreeMap集合底层是红黑树,因此TreeSet底层也是红黑树。它们的排序通过java.lang.Comparable和java.util.Comparator均可实现。
- ⑨LinkedHashSet集合底层是new了一个LinkedHashMap。LinkedHashMap集合只是为了保证元素的插入顺序,效率比HashSet低,底层采用的哈希表+双向链表实现。
- ⑩根据源码可以看到向Set集合中add时,底层会向Map中put。value只是一个固定不变的常量,只是起到一个占位符的作用。主要是key。
Map接口常用方法



1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| V put(K key, V value);
void putAll(Map<? extends K,? extends V> m);
V get(Object key);
boolean containsKey(Object key);
boolean containsValue(Object value);
V remove(Object key);
void clear();
int size();
boolean isEmpty();
Collection<V> values();
for(String value: values){
}
Set<K> keySet();
Set<Map.Entry<K,V>> entrySet();
static <K,V> Map<K,V> of(K k1, V v1, K k2, V v2, K k3, V v3);
|
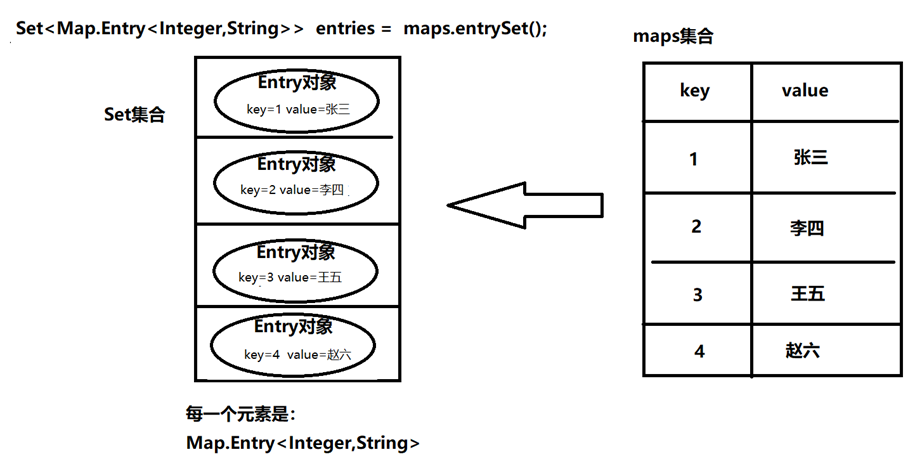
Map怎么进行遍历
遍历Map集合的所有key,然后遍历每个key,通过key获得value。
Set keySet(); //获取所有的key
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
Set<String> set = map.keySet();
Iterator<String> it = set.iterator();
while (it.hasNext()){
String key = it.next();
System.out.println(key + "=" + map.get(key));
}
System.out.println("----------------");
for (String key : set) {
System.out.println(key);
}
|
Set<Map.Entry<K,V>> entrySet(); //获取所有键值对的Set视图。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
//遍历Map的第二种方法;这种方法效率比较的高
// Set<Map.Entry<K,V>> entrySet(); //获取所有键值对的Set视图。
// entry 是一个键值对的对象
Set<Map.Entry<String, String>> entrySet = mapself.entrySet();
Iterator<Map.Entry<String, String>> it2 = entrySet.iterator();
while (it2.hasNext()) {
Map.Entry<String, String> entry = it2.next();
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "=" + value);
// System.out.println(entry.getKey() + "=" + entry.getValue());
}
|
HashMap(散列表)
hashset底层就是hashmap,把map中的所有k取出来就是set
hash是什么,是key的hashcode执行结果
transient Node<k,v>[] table;
get()方法:给出一个key,先计算hashcode,然后到相应的单链表里找,最多可以n/k 效率提高
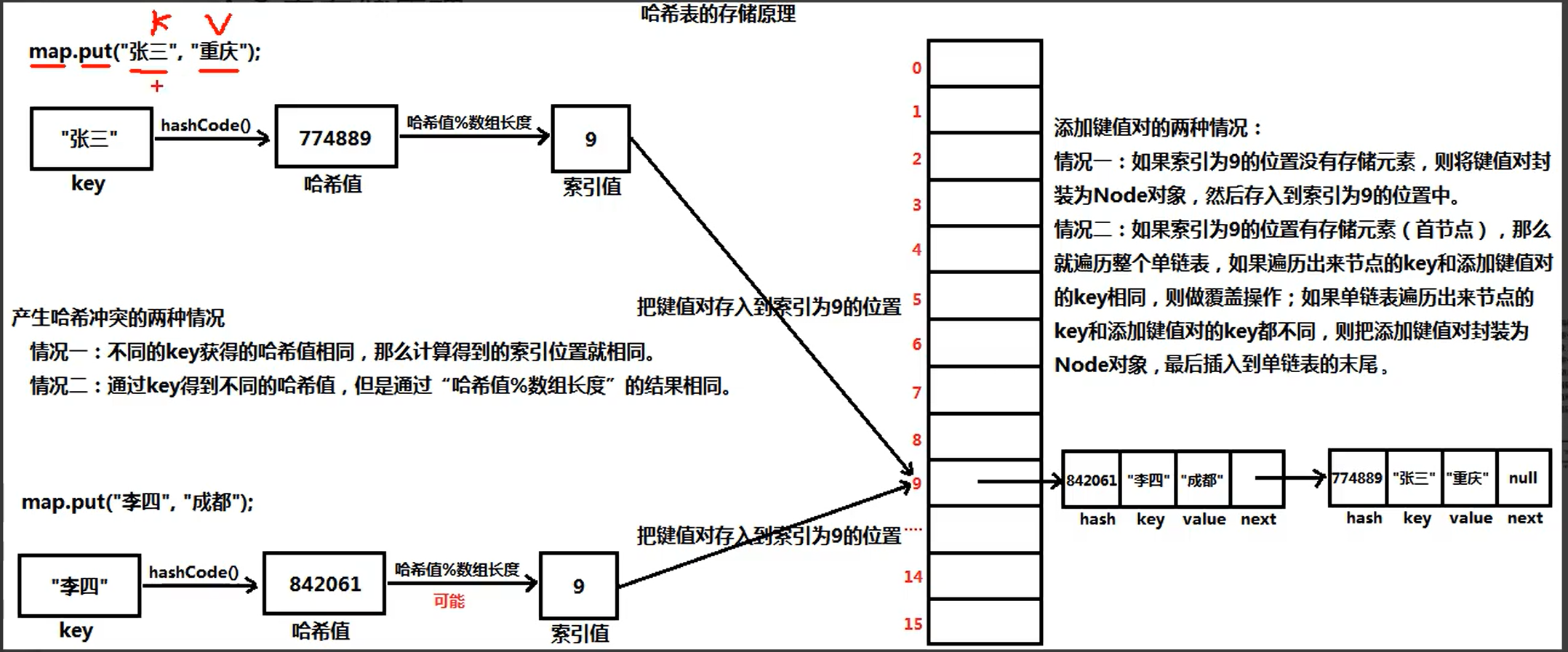
key进行hashCode编码,取模。
HashMap(散列表)
①HashMap集合的key是==无序不可重复==的。
无序:插入顺序和取出顺序不一定相同。
不可重复:key具有唯一性。
②向HashMap集合中put时,key如果重复的话,value会覆盖。
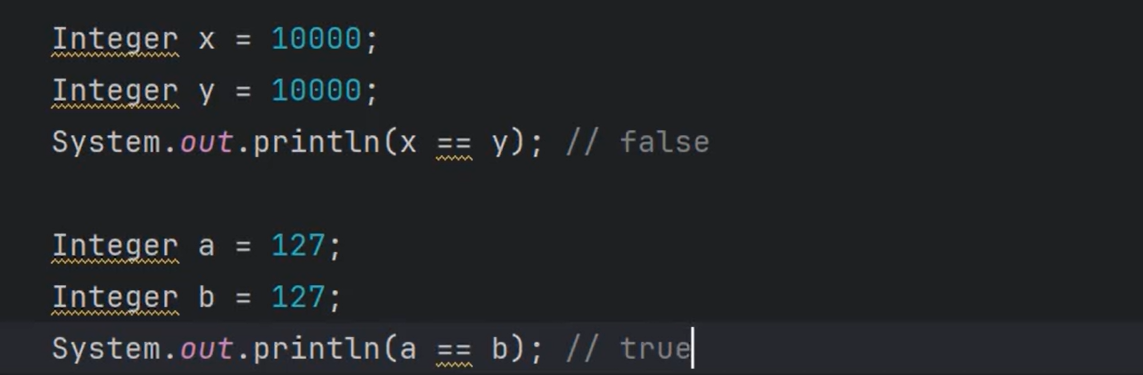
③HashMap集合的key具有唯一性,向key部分插入自定义的类型会怎样?如果自定义的类型重写equals之后会怎样???
如果没有重写equals,就会调用Object的equals,就是用==进行比较的,就是比较内存地址。
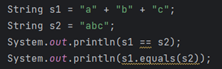
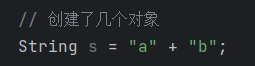
按照加双引号的字面量会在JVM开始的时候就在字符串常量池中创建的规则,相同的都放进去了
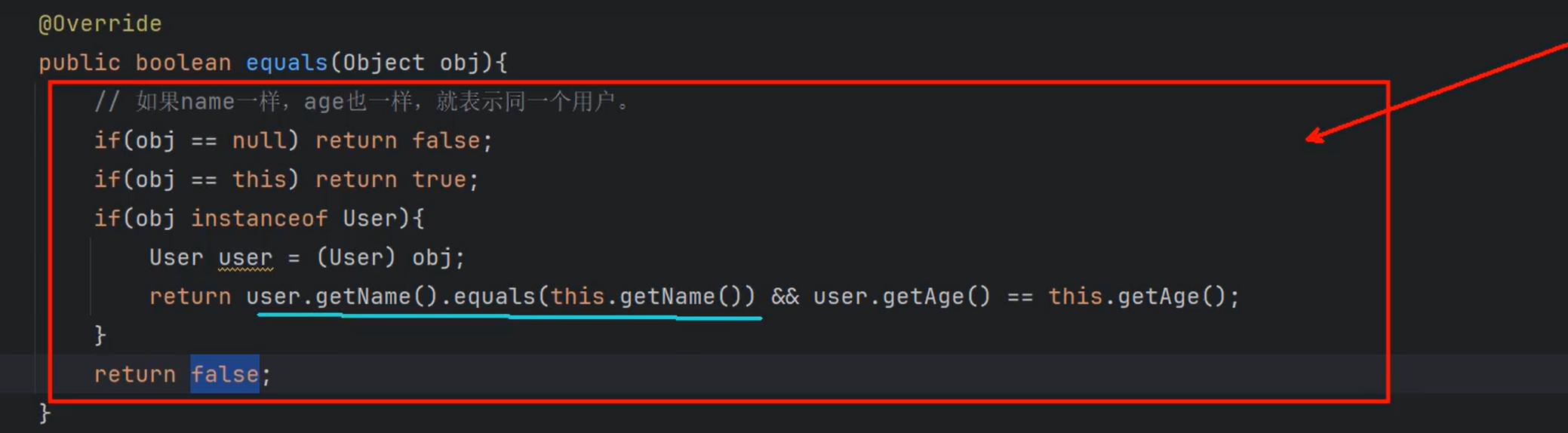
④HashMap底层的数据结构是:哈希表/散列表
hash是key调Object的hashcode方法得到的
- ①哈希表是一种查询和增删效率都很高的一种数据结构,非常重要,在很多场合使用,并且面试也很常见。必须掌握。
- ②哈希表如何做到的查询和增删效率都好的呢,因为哈希表是“数组 + 链表”的结合体。数组和链表的结合不是绝对的。
- ③哈希表可能是:数组 + 链表,数组 + 红黑树, 数组 + 链表 + 红黑树等。
⑤HashMap集合底层部分源码:
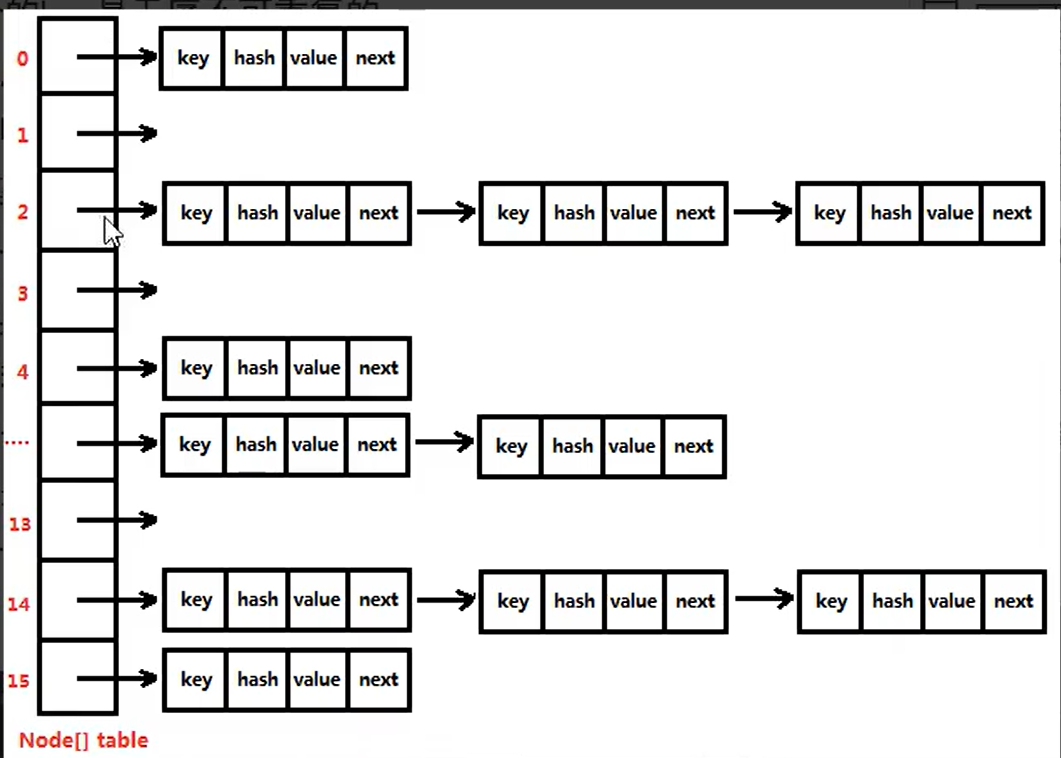
长度永远是2的倍数,一维数组挂链表
哈希表存储原理
①概念:
1. 哈希表:一种数据结构的名字。
2. 哈希函数:
- ①通过哈希函数可以将一个Java对象映射为一个数字。(就像现实世界中,每个人(对象)都会映射一个身份证号(哈希值)一样。)
- ②也就是说通过哈希函数的执行可以得到一个哈希值。
- ③在Java中,hashCode()方法就是哈希函数。
- ④也就是说hashCode()方法的返回值就是哈希值。
- ⑤一个好的哈希函数,可以让散列分布均匀。
3.哈希值:也叫做哈希码。是哈希函数执行的结果。
4.哈希碰撞:也叫做哈希冲突。
- ①当两个对象“哈希值%数组长度”之后得到的下标相同时,就发生了哈希冲突。
- ②如何解决哈希冲突?将冲突的挂到同一个链表上或同一个红黑树上。
5.以上描述凡是“哈希”都可以换为“散列”。
②重点:
- ①存放在HashMap集合key部分的元素必须同时重写hashCode+equals方法。
如果是
- ②equals返回true时,hashCode必须相同。
Hashcode和equals要同时重写
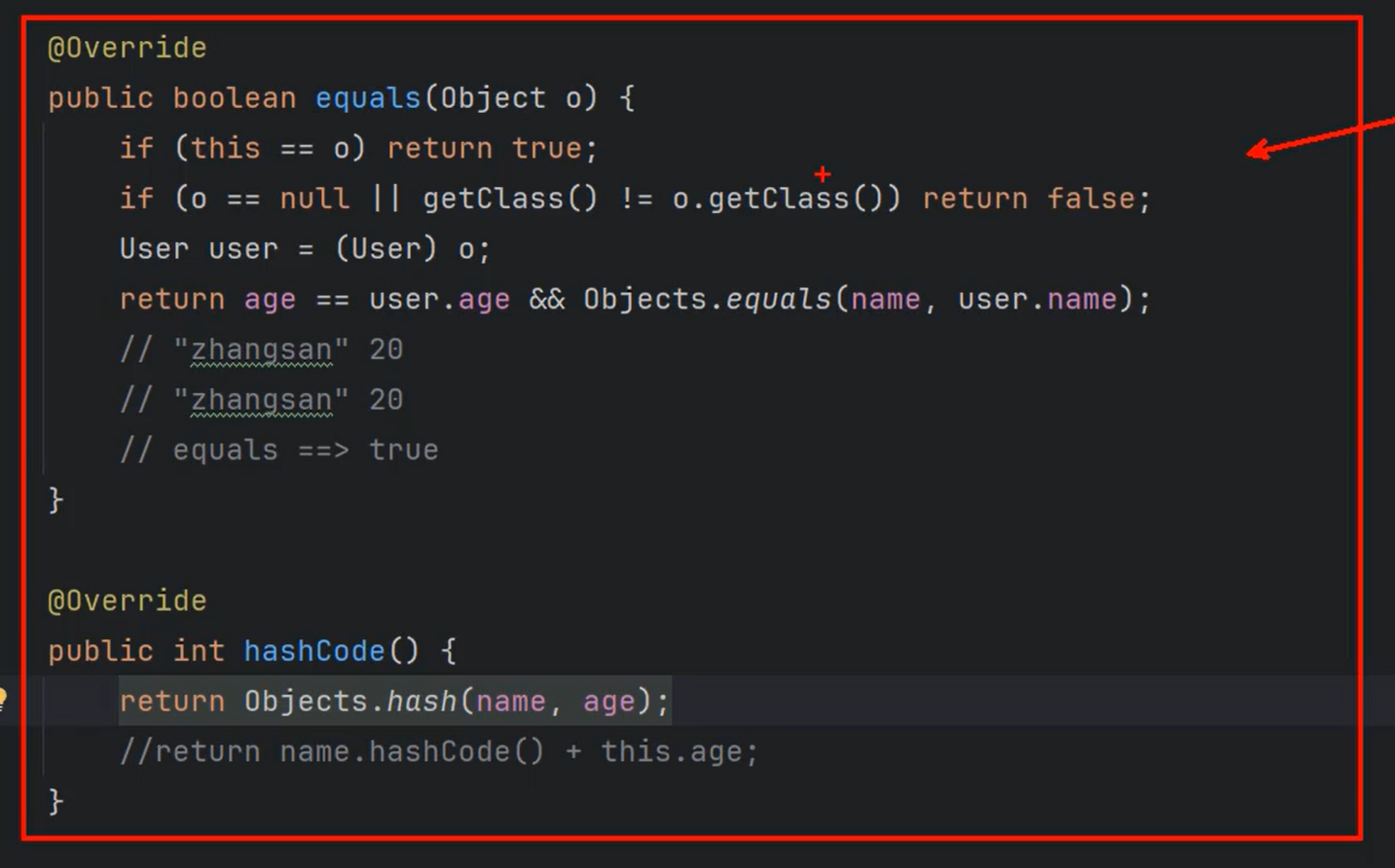
手写HashMap的put方法
①【第一步】:处理key为null的情况
key可以是null,null只能有一个
如果添加键值对的key就是null,则将该键值对存储到table数组索引为0的位置。
②【第二步】:获得key对象的哈希值
如果添加键值对的key不是null,则就调用key的hashcode()方法,获得key的哈希值。
③【第三步】:获得键值对的存储位置
因为获得的哈希值在数组合法索引范围之外,因此我们就需要将获得的哈希值转化为[0,数组长度-1]范围的整数,
那么可以通过取模法来实现,也就是通过“哈希值 % 数组长度”来获得索引位置(i)。
④【第四步】:将键值对添加到table数组中
当table[i]返回结果为null时,则键键值对封装为Node对象并存入到table[i]的位置。
当table[i]返回结果不为null时,则意味着table[i]存储的是单链表。我们首先遍历单链表,如果遍历出来节点的
key和添加键值对的key相同,那么就执行覆盖操作;如果遍历出来节点的key和添加键值对的key都不同,则就将键键
值对封装为Node对象并插入到单链表末尾。
HashMap在Java8后的改进(包含Java8)

①初始化时机:
- ①Java8之前,构造方法执行时初始化table数组。
- ②Java8之后,第一次调用put方法时初始化table数组。
②插入法:
- ①Java8之前,头插法
- ②Java8之后,尾插法
③数据结构:
- ①Java8之前:数组 + 单向链表
- ②Java8之后:数组 + 单向链表 + 红黑树。
- ③最开始使用单向链表解决哈希冲突。如果结点数量 >= 8,并且table的长度 >= 64。单向链表转换为红黑树。
- ④当删除红黑树上的结点时,结点数量 <= 6 时。红黑树转换为单向链表。
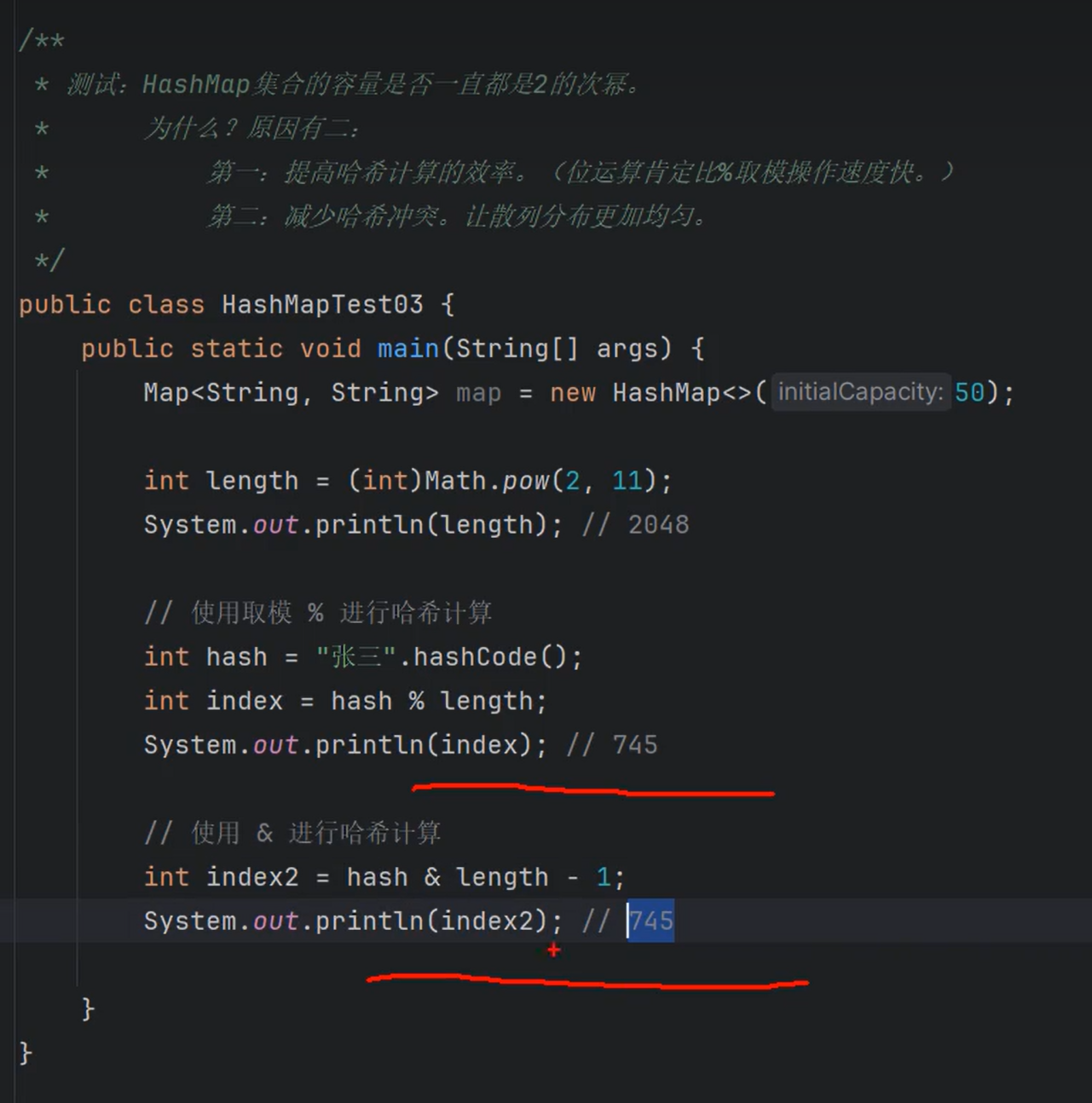
HashMap初始化容量永远都是2的次幂
①HashMap集合初始化容量16(第一次调用put方法时初始化)
②HashMap集合的容量永远都是2的次幂,假如给定初始化容量为31,它底层也会变成32的容量。
③将容量设置为2的次幂作用是:加快哈希计算,减少哈希冲突。
④为什么会加快哈希计算?
- ①首先你要知道,使用二进制运算是最快的。
- ②当一个数字是2的次幂时,例如数组的长度是2的次幂:
①hash & (length-1) 的结果和 hash % length的结果相同。
②注意:只有是2的次幂时,以上等式才会成立。因为了使用 & 运算符,让效率提升,因此建议容量一直是2的次幂。
⑤为什么会减少哈希冲突?
- ①底层运算是:hash & length - 1
- ②如果length是偶数:length-1后一定是奇数,奇数二进制位最后一位一定是1,1和其他二进制位进行与运算,结果可能是1,也可能是0,这样可以减少哈希冲突,让散列分布更加均匀。
- ③如果length是奇数:length-1后一定是偶数,偶数二进制位最后一位一定是0,0和任何数进行与运算,结果一定是0,这样就会导致发生大量的哈希冲突,白白浪费了一半的空间。
Hashtable
Properties
二叉树与红黑二叉树
TreeMap(底层红黑树)
Set接口(无序、不可重复)
Collections工具类
IO流
IO流概述
①什么是IO流?
水分子的移动形成了水流。
IO流指的是:程序中数据的流动。数据可以从内存流动到硬盘,也可以从硬盘流动到内存。
Java中IO流最基本的作用是:完成文件的读和写。
②IO流的分类?
根据数据流向分为:输入和输出是相对于内存而言的。
①输入流:从硬盘到内存。(输入又叫做读:read)
②输出流:从内存到硬盘。(输出又叫做写:write)
根据读写数据形式分为:
①字节流:一次读取一个字节。适合读取非文本数据。例如图片、声音、视频等文件。(当然字节流是万能的。什么都可以读和写。)
②字符流:一次读取一个字符。只适合读取普通文本。不适合读取二进制文件。因为字符流统一使用Unicode编码,可以避免出现编码混乱的问题。
==注意:Java的所有IO流中凡是以Stream结尾的都是字节流。凡是以Reader和Writer结尾的都是字符流。==
根据流在IO操作中的作用和实现方式来分类:
①节点流:节点流负责数据源和数据目的地的连接,是IO中最基本的组成部分。
②处理流:处理流对节点流进行装饰/包装,提供更多高级处理操作,方便用户进行数据处理。
③Java中已经将io流实现了,在java.io包下,可以直接使用。
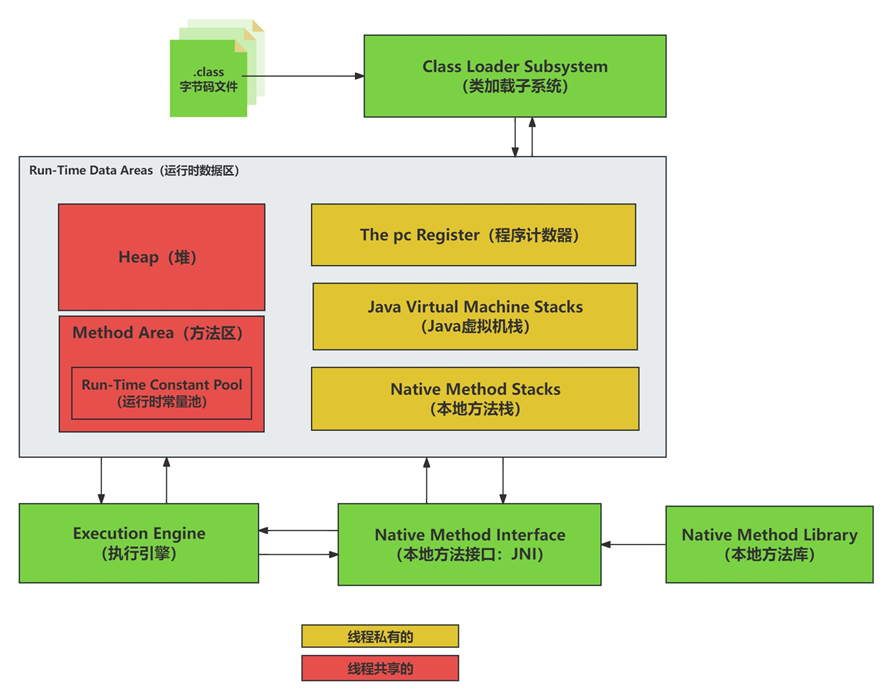
IO流体系结构

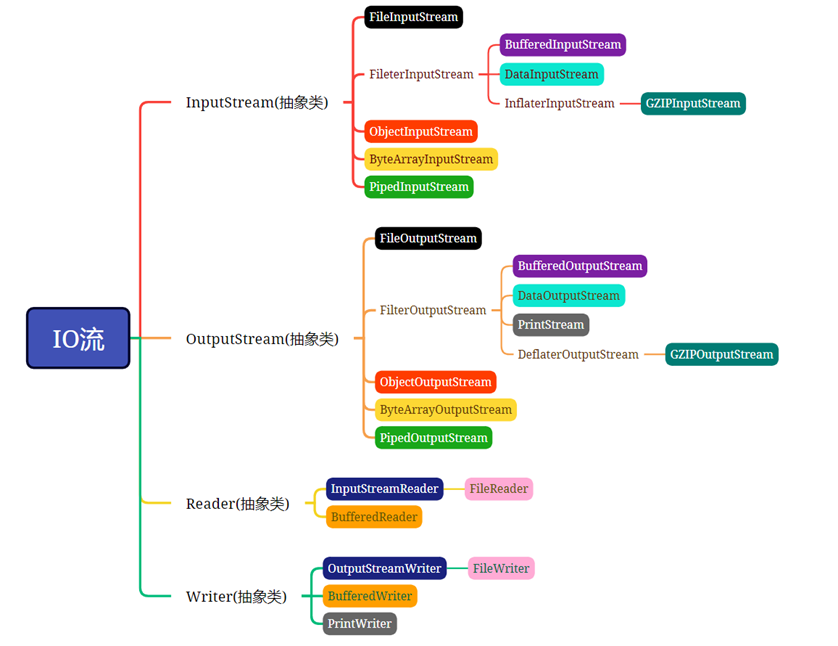
IO流的体系结构
①右图是常用的IO流。实际上IO流远远不止这些。
②InputStream:字节输入流
③OutputStream:字节输出流
④Reader:字符输入流
⑤Writer:字符输出流
⑥以上4个流都是抽象类,是所有IO流的四大头领!!!
⑦所有的流都实现了Closeable接口,都有close()方法,流用完要关闭。
finally{
close()
}
⑧所有的输出流都实现了Flushable接口,都有flush()方法,flush方法的作用是,将缓存清空,全部写出。养成好习惯,以防数据丢失。
①文件字节输入流,可以读取任何文件。
②常用构造方法
FileInputStream(String name):创建一个文件字节输入流对象,参数是文件的路径

③常用方法
1
2
3
4
5
6
7
8
9
10
11
12
| int read();
int read(byte[] b);
int read(byte[] b, int off, int len); 读到数据后向byte数组中存放时,从off开始存放,最多读取len个字节。读取不到任何数据则返回 -1
long skip(long n); 跳过n个字节
int available();
void close()
flush 把缓存里的内容全部写出 全部清空
|
④使用FileInputStream读取的文件中有中文时,有可能读取到中文某个汉字的一半,在将byte[]数组转换为String时可能出现乱码问题,因此FileInputStream不太适合读取纯文本。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| public static void main(String[] args) throws IOException {
FileInputStream in = new FileInputStream("src/hello.txt");
int readByte = 0 ;
while((readByte = in.read() )!= -1){
System.out.println(readByte);
}
System.out.println("Hello world!");
}
FileInputStream fis = null;
try {
fis = new FileInputStream("src/hello.txt");
int readByte = 0;
byte[] bytes = new byte[4];
int readCount = fis.read(bytes);
String s1 = new Strin (bytes);
System.out.println(s1);
System.out.println("the first time:"+readCount);
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
} catch (IOException e) {
throw new RuntimeException(e);
}
|
FileOutputStream
文件字节输出流。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
常用构造方法:
FileOutputStream(String name)
FileOutputStream(String name, boolean append)
append = true 不会清空文件的内容,在源文件的末尾追加写入
append =false 会清空源文件的内容,然后写入
常用方法:
write(int b)
void write(byte[] b);
void write(byte[] b, int off, int len);
void close()
void flush()
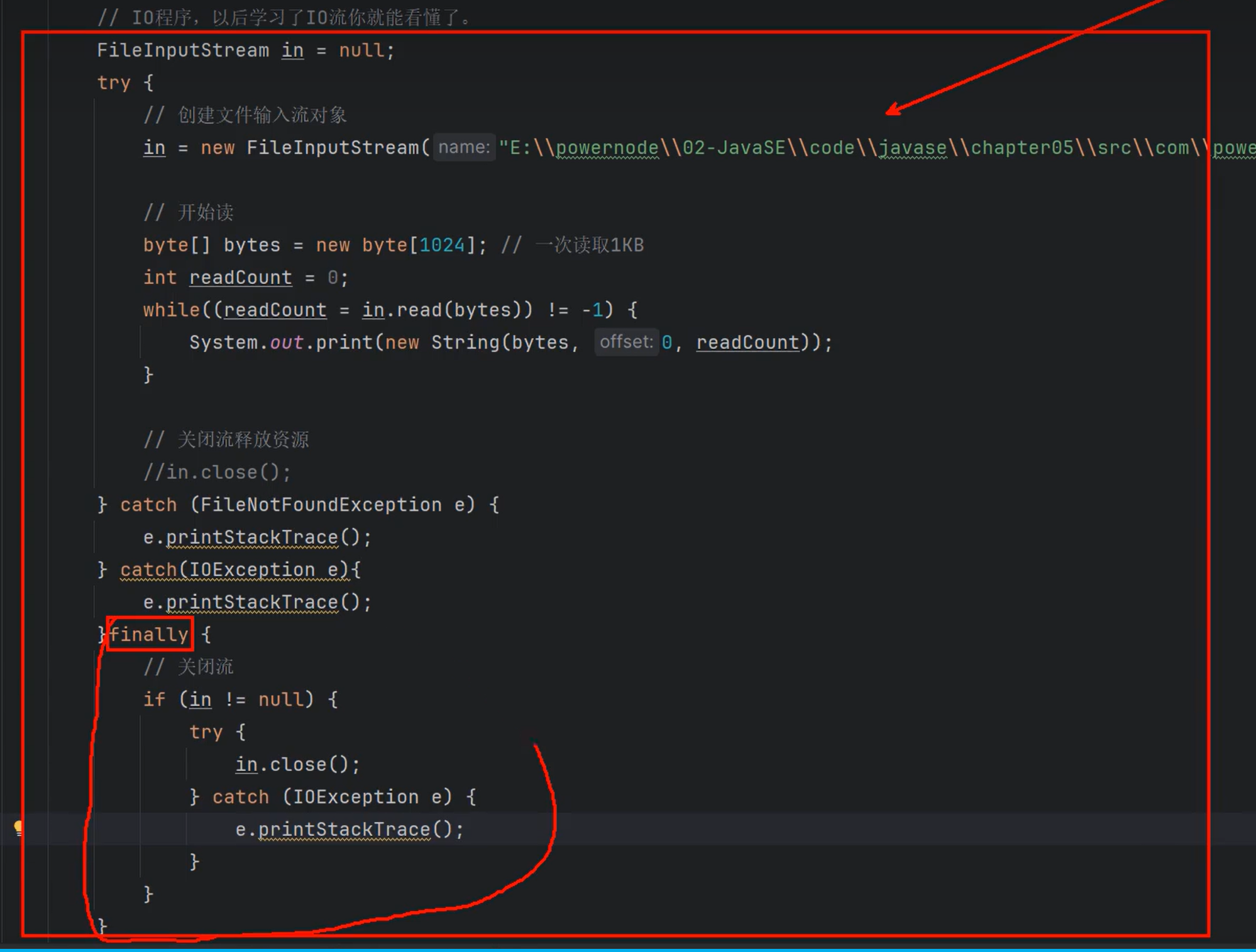
使用FileInputStream和FileOutputStream完成文件的复制。
|
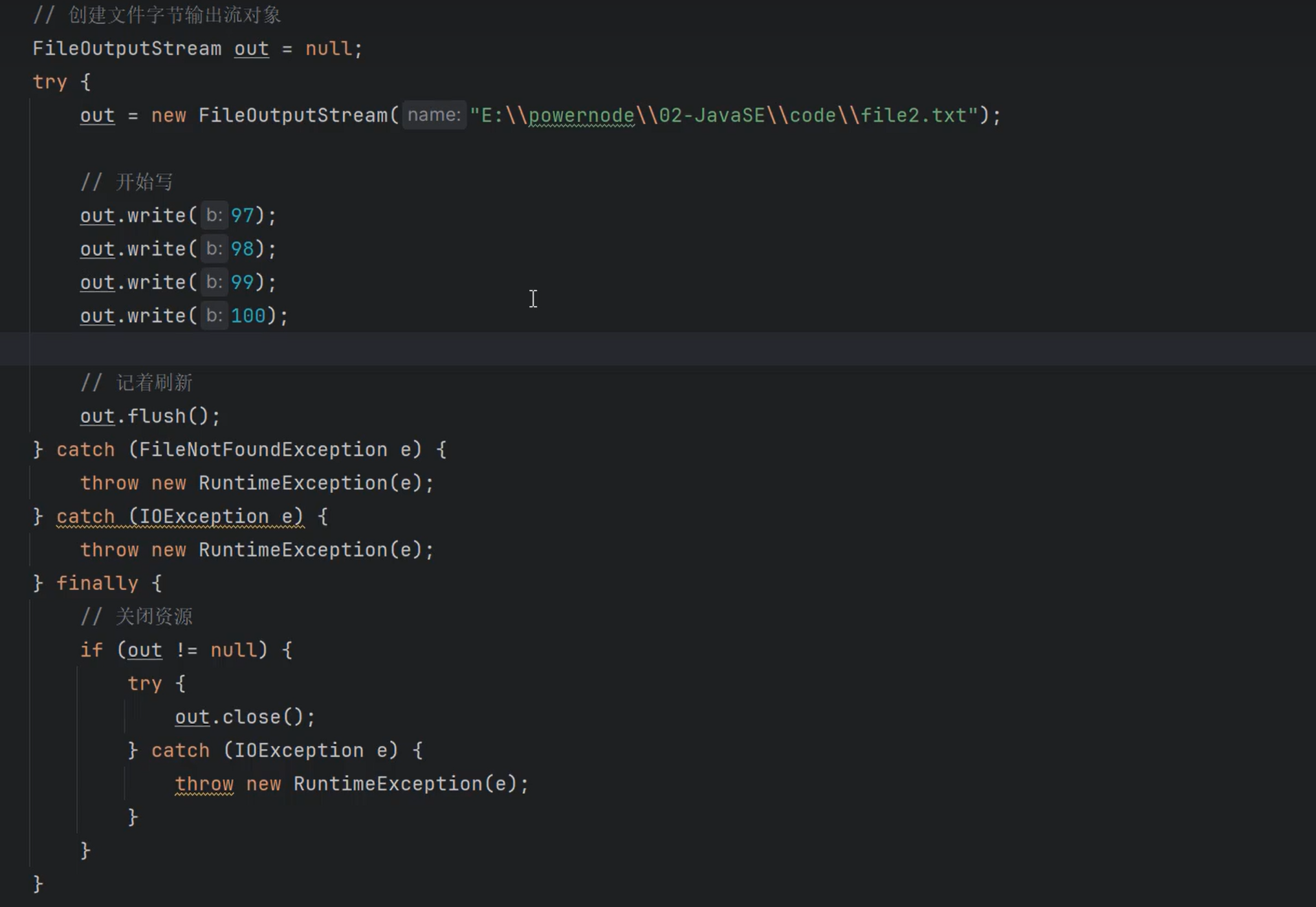
copy文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| package com.ljy.CollectionTest.IOstream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileInputOutputStreamCopy {
public static void main(String[] args) {
FileInputStream in = null;
FileOutputStream out = null;
try {
in = new FileInputStream("D:\\Blog-hexo\\source\\_posts\\Java基础部分4-集合.md");
out = new FileOutputStream("D:\\job\\code\\Java-Test\\src\\Java基础部分4-集合.md");
byte[] bytes= new byte[1024];
int readCount = 0;
while((readCount = in.read(bytes))!=-1){
out.write(bytes,0,readCount);
}
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
if (in != null){
try {
in.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
if(out != null){
try {
out.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}
}
|
Try-With-Resource
资源自动关闭

1
2
3
4
5
6
7
| try (FileInputStream in = new FileInputStream(("D:\\job\\code\\Java-Test\\src\\hello.txt"))){
in2 = in ;
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
} catch (IOException e) {
throw new RuntimeException(e);
}
|
这样可以实现资源的自动管理,如果在trycatch外面对于流进行读取,就会报“流已经关闭错误”
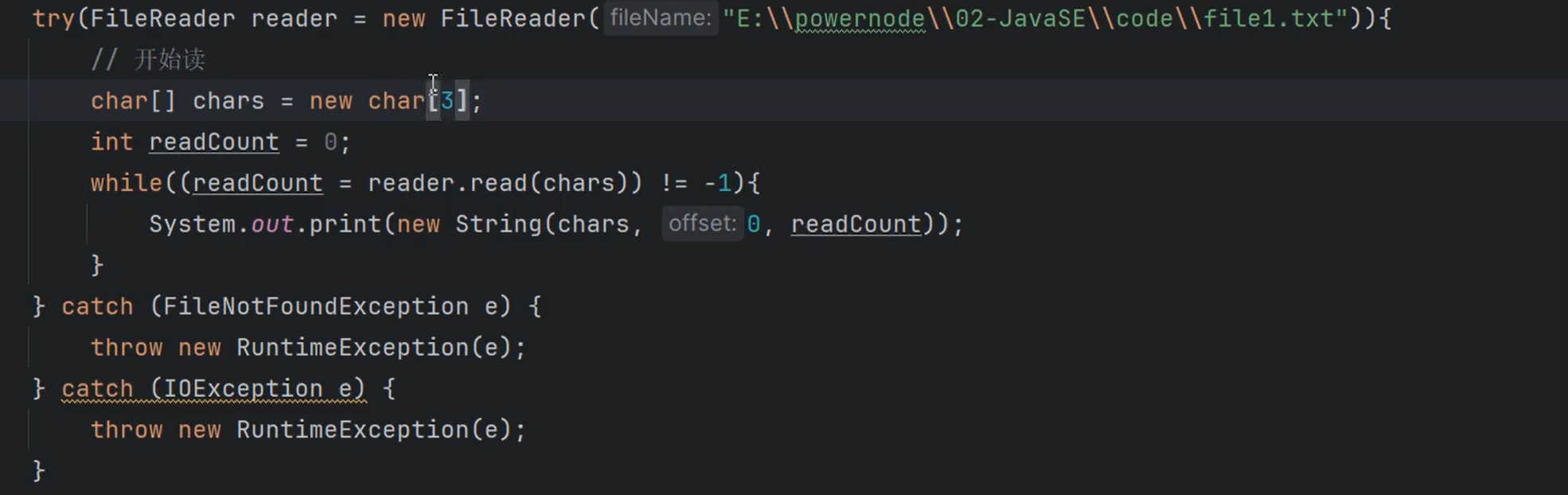
FileReader
FileInputStream 内部是byte[],这个内部是char[]
用法非常的相似
1
2
3
4
5
6
7
8
9
10
|
常用的构造方法:
FileReader(String fileName)
常用的方法:
int read()
int read(char[] cbuf);
int read(char[] cbuf, int off, int len);
long skip(long n);
void close()
|
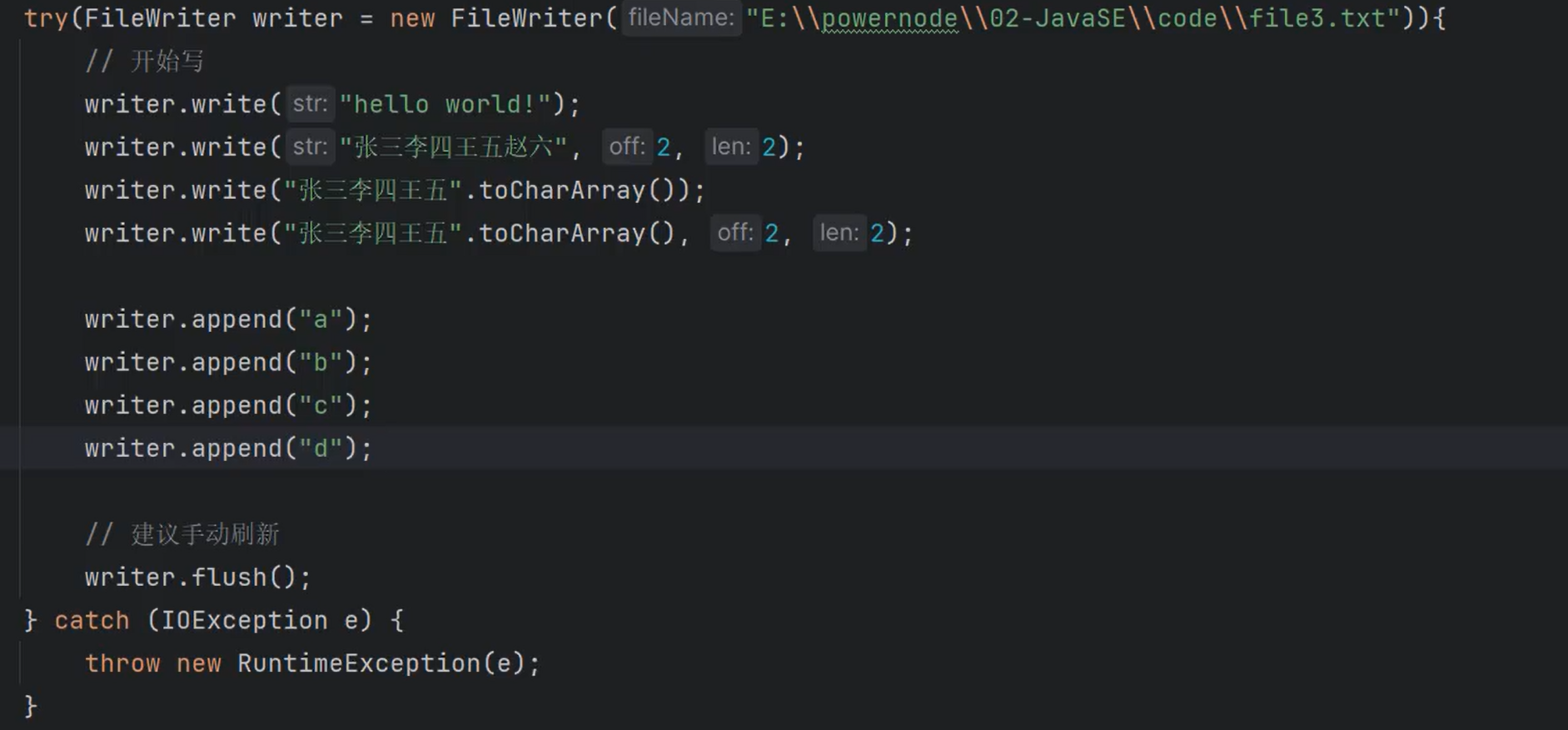
FileWriter
文件字符输出流,写普通文本用的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
常用的构造方法:
FileWriter(String fileName)
FileWriter(String fileName, boolean append)
常用的方法:
void write(char[] cbuf)
void write(char[] cbuf, int off, int len);
void write(String str);
void write(String str, int off, int len);
void flush();
void close();
Writer append(CharSequence csq, int start, int end)
使用FileReader和FileWriter拷贝普通文本文件
|
copy文件
用这种方式只能复制普通文本文件
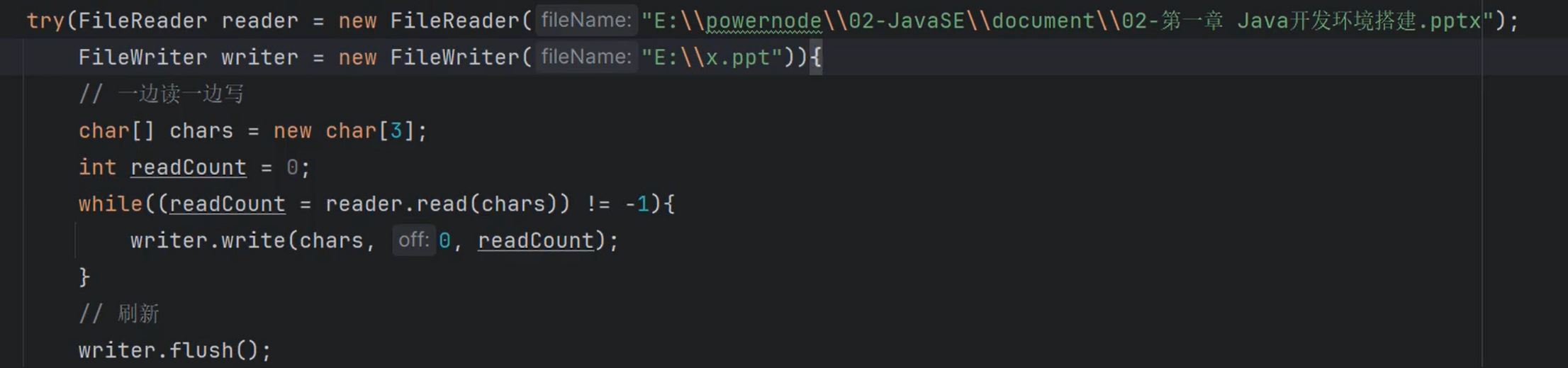
读写文件的路径问题
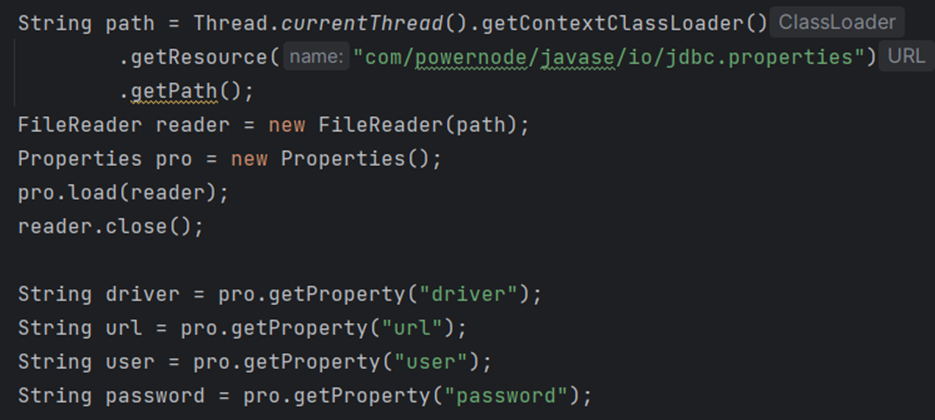
从类路径加载资源
1
2
| String path = Thread.currentThread().getContextClassLoader().getResource("自动从类中加载资源").getPath();
System.out.println(path);
|
 src
src
如果这个资源放在类路径之外,就不合适了
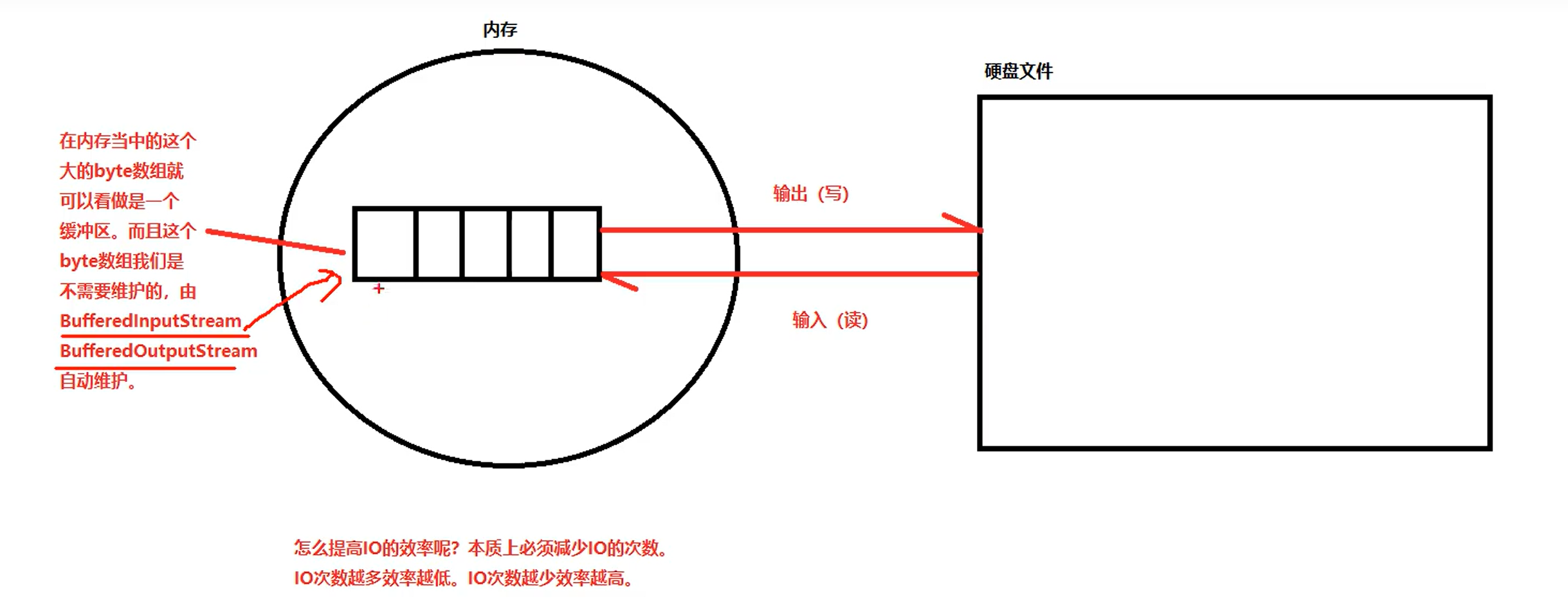
缓冲流(读大文件的时候建议)
带缓冲区的,效率会比较的高
FileInputStream是一个节点流
BufferedInputStream是一个缓冲流,效率高,自带缓冲区
②BufferedReader、BufferedWriter(适合读写普通文本文件。)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| BufferedInputStream bis = null;
try {
try {
bis = new BufferedInputStream(new FileInputStream("D:\\job\\code\\Java-Test\\src\\hello.txt"));
} catch (FileNotFoundException ex) {
throw new RuntimeException(ex);
}
} catch(Exception e){
e.printStackTrace();
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
long begin = System.currentTimeMillis();
try(BufferedInputStream bis = new BufferedInputStream(new FileInputStream("D:\\job\\code\\Java-Test\\src\\hello.txt"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("D:\\job\\code\\Java-Test\\src\\hello3.txt"))){
byte[] bytes = new byte[1024];
int readCount = 0;
while ((readCount = bis.read(bytes))!=-1){
bos.write(bytes,0,readCount);
}
bos.flush();
}
catch (FileNotFoundException e) {
throw new RuntimeException(e);
} catch (IOException e) {
throw new RuntimeException(e);
}
long end = System.currentTimeMillis();
System.out.println(end-begin);
|
③缓冲流的读写速度快原理
在内存中准备了一个缓存。读的时候从缓存中读。写的时候将缓存中的数据一次写出。都是在减少和磁盘的交互次数。如何理解缓冲区?家里盖房子,有一堆砖头要搬在工地100米外,单字节的读取就好比你一个人每次搬一块砖头,从堆砖头的地方搬到工地,这样肯定效率低下。然而聪明的人类会用小推车,每次先搬砖头搬到小车上,再利用小推车运到工地上去,这样你再从小推车上取砖头是不是方便多了呀!这样效率就会大大提高,缓冲流就好比我们的小推车,给数据暂时提供一个可存放的空间。
⑤关闭流只需要关闭最外层的处理流即可,通过源码就可以看到,当关闭处理流时,底层节点流也会关闭。
⑥输出效率是如何提高的?
在缓冲区中先将字符数据存储起来,当缓冲区达到一定大小或者需要刷新缓冲区时,再将数据一次性输出到目标设备。
⑦输入效率是如何提高的?
read()方法从缓冲区中读取数据。当缓冲区中的数据不足时,它会自动从底层输入流中读取一定大小的数据,并将数据存储到缓冲区中。大部分情况下,我们调用read()方法时,都是从缓冲区中读取,而不需要和硬盘交互。
⑧可以编写拷贝的程序测试一下缓冲流的效率是否提高了!
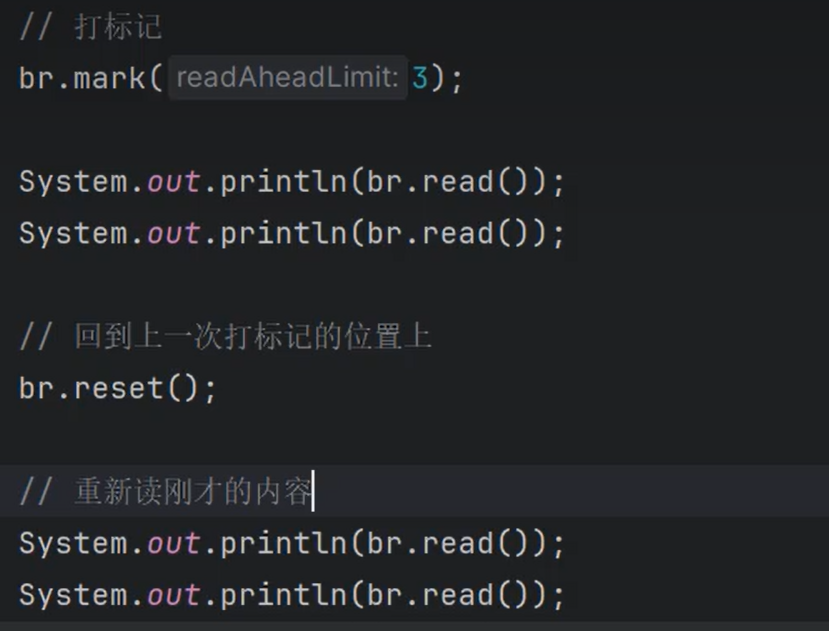
⑨缓冲流的特有方法(输入流):以下两个方法的作用是允许我们在读取数据流时回退到原来的位置(重复读取数据时用)
①void mark(int readAheadLimit); 标记位置(在Java21版本中,参数无意义。
低版本JDK中参数表示在标记处最多可以读取的字符数量,如果你读取的字符数超出的上限值,则调用reset()方法时出现IOException。)
②void reset(); 重新回到上一次标记的位置
③这两个方法有先后顺序:先mark再reset,另外这两个方法不是在所有流中都能用。有些流中有这个方法,但是不能用。
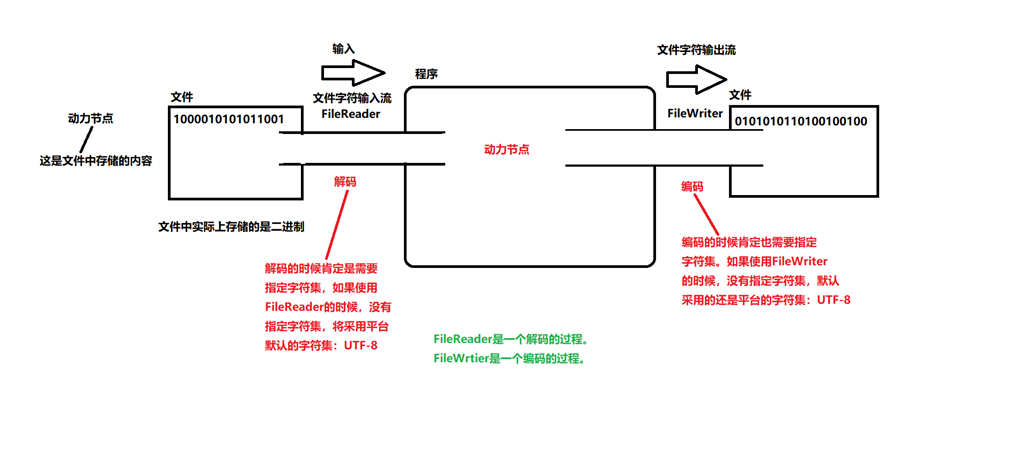
字符流 、转换流,是一个输入的过程,是一个解码的过程
节点流直接连接两个设备
①InputStreamReader为转换流,属于字符流。
②作用是将文件中的字节转换为程序中的字符。转换过程是一个解码的过程。
③常用的构造方法:
InputStreamReader(InputStream in, String charsetName) // 指定字符集
InputStreamReader(InputStream in) // 采用平台默认字符集
1
2
3
4
5
6
7
8
9
10
11
|

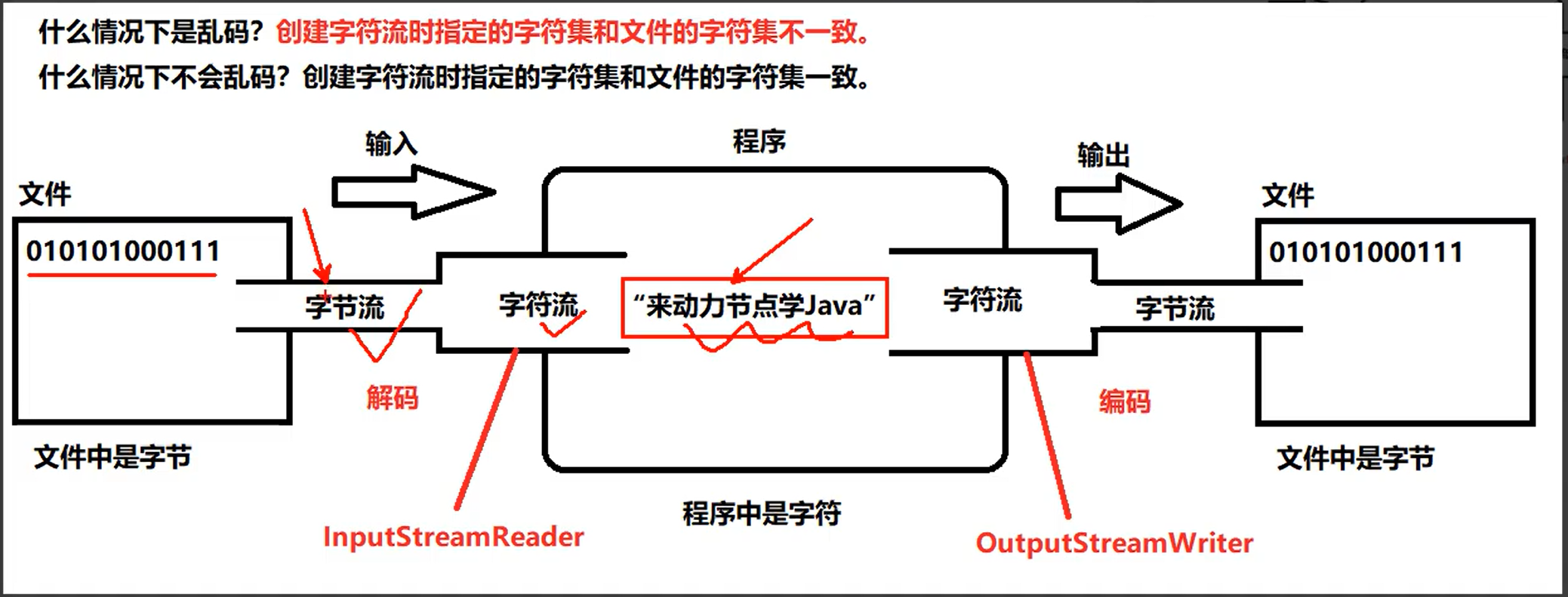
④乱码是如何产生的?文件的字符集和构造方法上指定的字符集不一致。
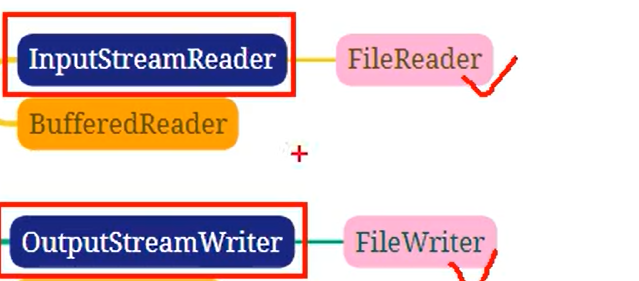
⑤**FileReader**是InputStreamReader的子类。本质上以下代码是一样的:
```java
Reader reader = new InputStreamReader(new FileInputStream(“file.txt”)); //采用平台默认字符集
Reader reader = new FileReader(“file.txt”); //采用平台默认字符集
|
因此FileReader的出现简化了代码的编写。
以下代码本质上也是一样的:
1
2
3
| Reader reader = new InputStreamReader(new FileInputStream(“file.txt”), “GBK”);
Reader reader = new FileReader("e:/file1.txt", Charset.forName("GBK"));
|
OutputStreamWriter(主要解决写的乱码问题)
①OutputStreamWriter是转换流,属于字符流。
②作用是将程序中的字符转换为文件中的字节。这个过程是一个编码的过程。
③常用构造方法:
1
2
3
4
| OutputStreamWriter(OutputStream out, String charsetName)
OutputStreamWriter(OutputStream out)
|
④乱码是如何产生的?文件的字符集与程序中构造方法上的字符集不一致。
⑤FileWriter是OutputStreamWriter的子类。以下代码本质上是一样的:
1
2
3
4
5
| Writer writer = new OutputStreamWriter(new FileOutputStream(“file1.txt”));
Writer writer = new FileWriter(“file1.txt”);
|
因此FileWriter的出现,简化了代码。
以下代码本质上也是一样的:
1
2
3
| Writer writer = new OutputStreamWriter(new FileOutputStream(“file1.txt”), “GBK”);
Writer writer = new FileWriter(“file1.txt”, Charset.forName(“GBK”));
|
数据流(DataOutputStream)
不涉及到任何的转换 ,二进制输入二进制出。
如果要恢复DataOutputStream的数据,要用DatainputStream
①这两个流都是包装流,读写数据专用的流。
②DataOutputStream直接将java程序中的数据写入文件,不需要转码,效率高。程序中是什么样子,原封不动的写出去。写完后,文件是打不开的。即使打开也是乱码,文件中直接存储的是二进制。
一次读八个比特位
④构造方法:
1
2
3
| DataInputStream(InputStream in)
DataOutputStream(OutputStream out)
|
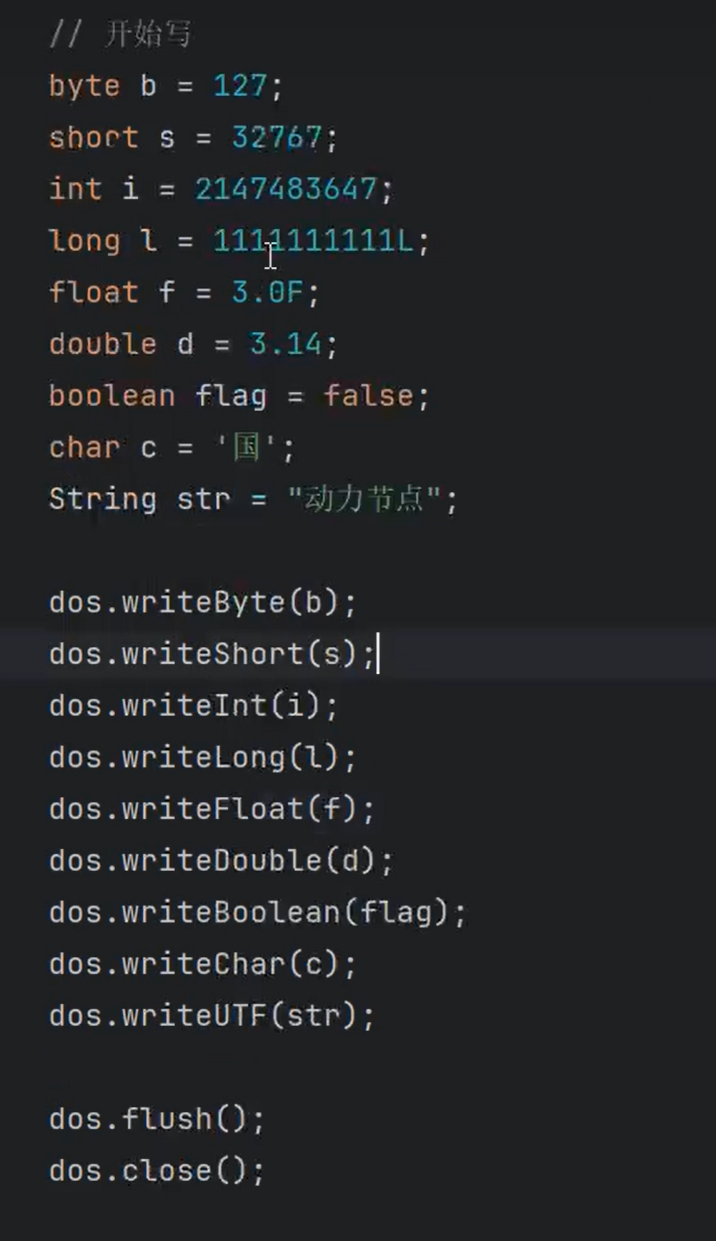
①写的方法:
writeByte()、writeShort()、writeInt()、writeLong()、writeFloat()、writeDouble()、writeBoolean()、writeChar()、writeUTF(String)
②读的方法:
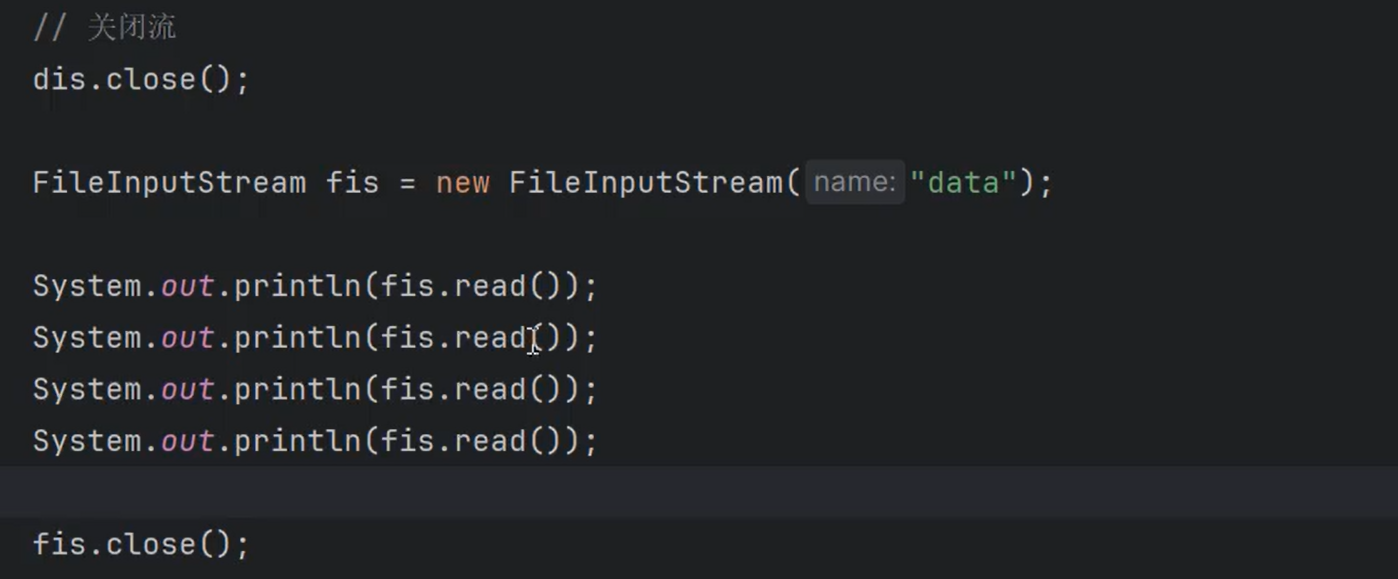
readByte()、readShort()、readInt()、readLong()、readFloat()、readDouble()、readBoolean()、readChar()、readUTF()
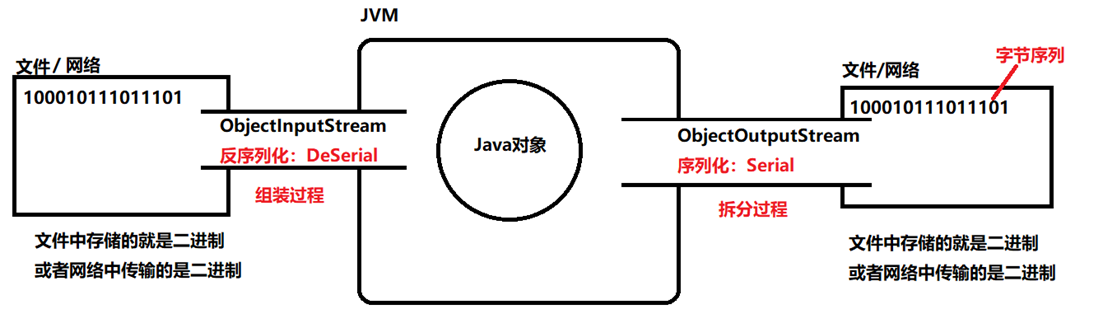
负责java对象Object的输入与输出,传输的其实还是是二进制,是对象的二进制,字节序列所以存在一个序列化与反序列化
序列化
将Java对象转换成字节序列的过程(字节序列可以在网络中传输)
1
2
3
4
5
6
7
8
9
| try (ObjectInputStream oos = new ObjectInputStream(new FileInputStream("Object"))) {
Date nowTime = new Date();
Object o = oos.readObject();
System.out.println(o);
} catch (IOException | ClassNotFoundException e) {
throw new RuntimeException(e);
}
|
①通过这两个流,可以完成对象的序列化和反序列化。
②序列化(Serial):将Java对象转换为字节序列。(为了方便在网络中传输),使用ObjectOutputStream序列化。
如果要序列化多个,会序列化一个集合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| Date date = new Date();
Date date1 = new Date();
Date date2 = new Date();
Date date3 = new Date();
Date date4 = new Date();
List<Date> list = new ArrayList<>();
list.add(date1);
list.add(date2);
list.add(date3);
list.add(date4);
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("date"));
oos.writeObject(list);
oos.flush();
oos.close();
|
③反序列化(DeSerial):将字节序列转换为Java对象。使用ObjectInputStream进行反序列化。
1
2
3
4
5
6
| ObjectInputStream ois = new ObjectInputStream(new FileInputStream("date"));
List<Date> dates = (List<Date>) ois.readObject();
for(Date d:dates){
System.out.println(d);
}
ois.close();
|
④参与序列化和反序列化的必须实现一个标志性接口:java.io.Serializable,自定义对象

⑤实现了Serializable接口的类,编译器会自动给该类添加序列化版本号的属性:**==serialVersionUID==**
这是一个标志接口,没有任何的方法,只是起到一个标志类型的作用
⑥在java中,是通过“类名 + 序列化版本号”来进行类的区分的。
⑦serialVersionUID实际上是一种安全机制。在反序列化的时候,JVM会去检查存储Java对象的文件中的class的序列化版本号是否和当前Java程序中的class的序列化版本号是否一致。如果一致则可以反序列化。如果不一致则报错。
同一个实现了serializatable接口的类,存在变化,它的序列号也会存在变换,这样才可以是的这个 序列化与反序列化可以保持一致。
如果只通过类名来进行类的区分,这样太过于危险
⑧如果一个类实现了Serializable接口,还是建议将序列化版本号固定死,原因是:
类有可能在开发中升级(改动),升级后会重新编译,如果没有固定死,编译器会重新分配一个新的序列化版本号,导致之前序列化的对象无法反序列化。显示定义序列化版本号的语法:
1
| private static final long serialVersionUID = XXL;
|

加了这个语句,可以让这个类的序列号保持一致,可以让这个类的对象反序列化正常
⑨为了保证显示定义的序列化版本号不会写错,建议使用 @java.io.Serial 注解进行标注。并且使用它还可以帮助我们随机生成序列化版本号。

⑩不参与序列化的属性需要使用瞬时关键字修饰:transient
有些属性不想让他参与序列化

ObjectOutputStream
1
2
3
4
5
6
7
8
9
10
11
| try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("Object"))) {
Date nowTime = new Date();
oos.writeObject(nowTime);
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
} catch (IOException e) {
throw new RuntimeException(e);
}
|
打印流(PrintStream PrintWriter)
PrintStream
①打印流(字节形式)
②主要用在打印方面,提供便捷的打印方法和格式化输出。主要打印内容到文件或控制台。
③常用方法:
1. print(Type x)
2. println(Type x)
④便捷在哪里?
1.直接输出各种数据类型
2.自动刷新和自动换行(println方法)
3.支持字符串转义
4.自动编码(自动根据环境选择合适的编码方式)
⑤格式化输出?调用printf方法。
1.%s 表示字符串
2.%d 表示整数
3.%f 表示小数(%.2f 这个格式就代表保留两位小数的数字。)
4.%c 表示字符
PrintWriter
①打印流(字符形式)注意PrintWriter使用时需要手动调用flush()方法进行刷新。
②比PrintStream多一个构造方法,PrintStream参数只能是OutputStream类型,但PrintWriter参数可以是OutputStream,也可以是Writer。
③常用方法:
1
2
3
| print(Type x)
println(Type x)
|
④同样,也可以支持格式化输出,调用printf方法。
构造方法
1
2
3
| PrintStream(OutputStream)
PrintWriter(OutputStream)
PrintWriter(Writer)
|

标准输入流&标准输出流
标准输入流
①System.in获取到的InputStream就是一个标准输入流。
1
| InputStream in = System.in;//直接可以获取一个标准
|
②**==标准输入流是用来接收用户在控制台上的输入的==。(==普通的输入流,是获得文件或网络中的数据==**)
③标准输入流不需要关闭。(它是一个系统级的全局的流,JVM负责最后的关闭。)
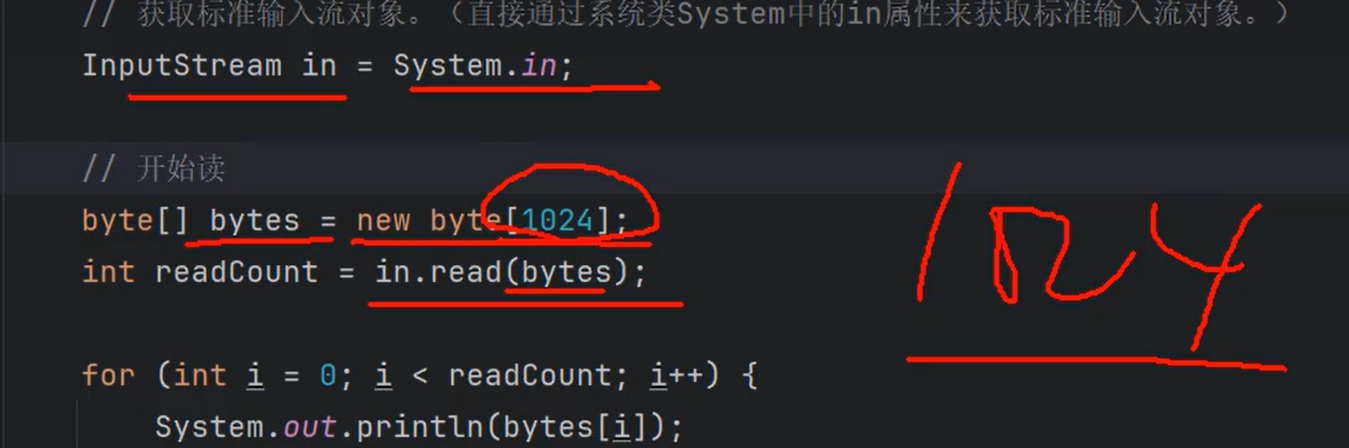
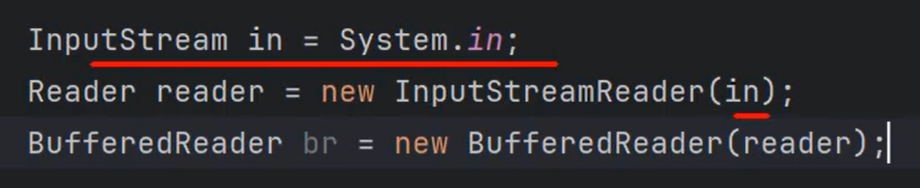
④也可以使用BufferedReader对标准输入流进行包装。这样可以方便的接收用户在控制台上的输入。(这种方式太麻烦了,因此JDK中提供了更好用的Scanner。)
1
2
3
| BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String s = br.readLine();
|
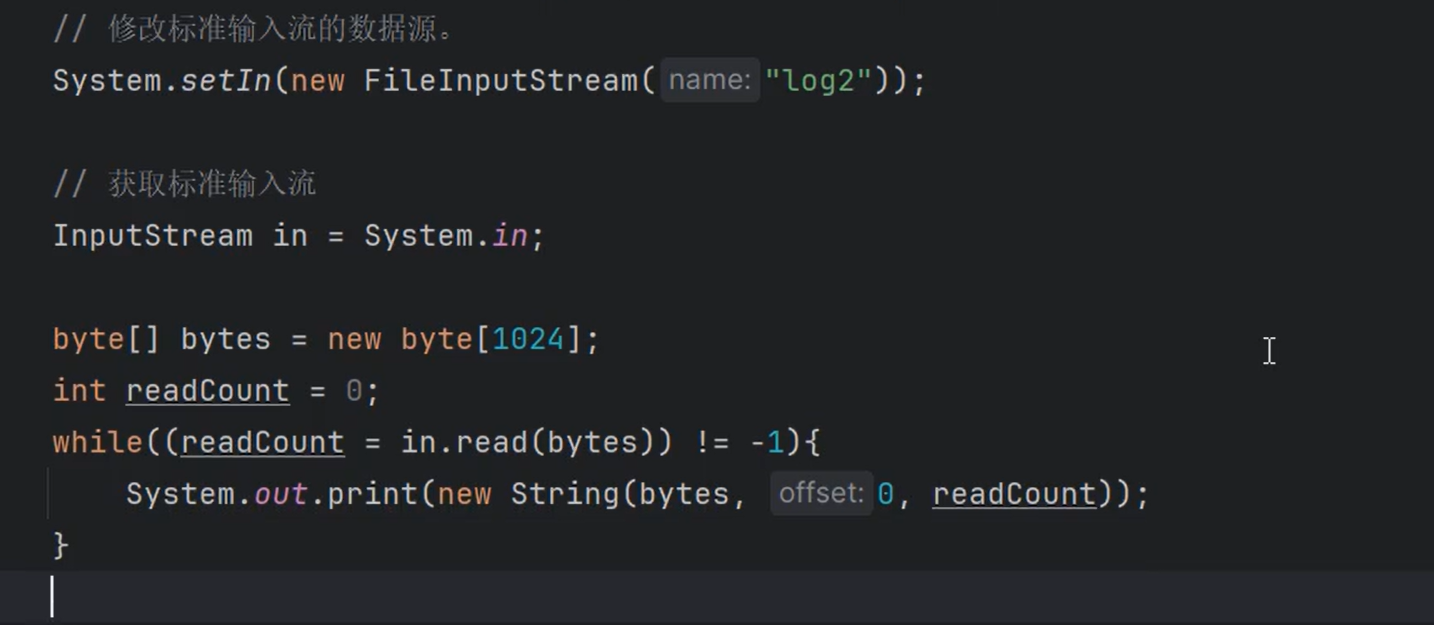
⑤当然,你也可以修改输入流的方向(System.setIn())。让其指向文件。
标准输出流
①**==System.out==获取到的==PrintStream==**就是一个标准输出流。
②标准输出流是用来向控制台上输出的。(普通的输出流,是向文件和网络等输出的。)
③标准输出流不需要关闭(它是一个系统级的全局的流,JVM负责最后的关闭。)也不需要手动刷新。
④当然,你也可以修改输出流的方向(System.setOut())。让其指向文件。
1
2
| PrintStream out = System.out;
out.println("hello")
|
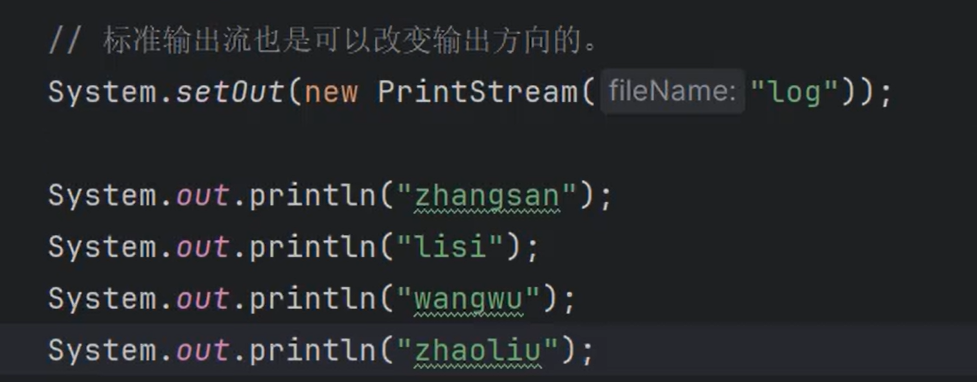
这样会输出到文件log里面,通常用这种方式来记录日志
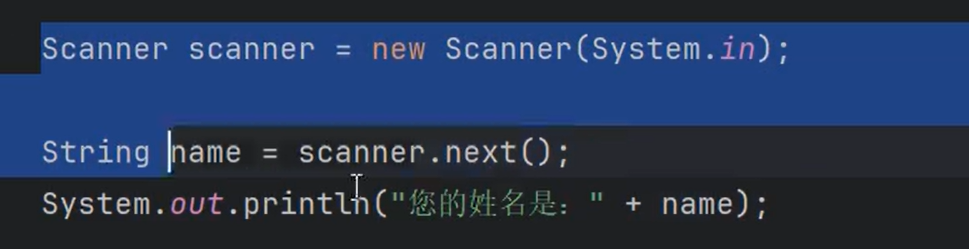
Scanner
File类(父类是object)
①File类不是IO流,和IO的四个头领没有关系。因此通过File是无法读写文件。
②**==File类是路径的抽象表示形式==,这个路径可能是目录,也可能是文件。因此==File代表了某个文件或某个目录==**。
③File类常用的构造方法:
④File类的常用方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| boolean createNewFile();
boolean delete();
boolean exists();
String getAbsolutePath();
String getName();
String getParent();
boolean isAbsolute();
boolean isDirectory();
boolean isFile();
boolean isHidden();
long lastModified();
long length();
File[] listFiles();
File[] listFiles(FilenameFilter filter);
boolean mkdir();
boolean mkdirs();
boolean renameTo(File dest);
boolean setReadOnly();
boolean setWritable(boolean writable);
|
⑤编写程序要求可以完成目录的拷贝。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| File file = new File("file");
System.out.println(file.exists()?"存在":"不存在");
if(!file.exists()){
file.mkdir();
}
File file1 = new File("D:/A/B/C");
if(!file1.exists()){
file1.mkdirs();
}
if(file1.exists()){
file1.delete();
}
File file2 = new File("hello.txt");
System.out.println(file2.getAbsolutePath());
File[] files = file1.listFiles();
for(File f:files){
System.out.println(f.getName());
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| File[] files1 = file3.listFiles(new FileFilter() {
@Override
public boolean accept(File pathname) {
if(pathname.getName().endsWith(".json"))
{
return true;
}
return false;
}
});
for(File f:files1){
System.out.println(f.getName());
}
|
File复制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
| package com.ljy.CollectionTest.IOstream;
import java.io.*;
public class FileTestcopy {
public void deleteFile(File file){
if(file.isFile()){
file.delete();
return;
}
File[] files = file.listFiles();
int length = files.length;
if(length==0){
file.delete();
return;
}
for(File fileitem : files){
deleteFile(fileitem);
}
}
public void copyFile(String fileRoot,File fileOri ,String distPath){
String relativePath = fileOri.getAbsolutePath().substring(fileRoot.length());
String distPathFile = distPath + relativePath;
File fileDist = new File(distPathFile);
FileInputStream in = null;
FileOutputStream out = null;
try {
in = new FileInputStream(fileOri);
out = new FileOutputStream(fileDist);
byte[] bytes= new byte[1024];
int readCount = 0;
while((readCount = in.read(bytes))!=-1){
out.write(bytes,0,readCount);
}
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
} catch (IOException e) {
throw new RuntimeException(e);
}finally {
if (in != null){
try {
in.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
if(out != null){
try {
out.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}
public void copyFiles(String fileRoot,File file ,String distPath) throws IOException {
if(file.isFile()){
copyFile(fileRoot,file,distPath);
return;
}
File[] files = file.listFiles();
int length = files.length;
for(File fileitem : files){
if(fileitem.isDirectory()){
String relativePath = fileitem.getAbsolutePath().substring(fileRoot.length());
String distPathFile = distPath + relativePath;
File fileDist = new File(distPathFile);
fileDist.mkdir();
}
copyFiles(fileRoot,fileitem,distPath);
}
}
public static void main(String[] args) throws IOException {
File file1 = new File("D:\\job\\dddd");
File file = new File("D:\\job\\cccc");
file.mkdir();
String distPath = "D:\\job\\cccc";
System.out.println(file1.exists()?"存在":"不存在");
FileTestcopy fileTest = new FileTestcopy();
fileTest.copyFiles(file1.getAbsolutePath(),file1,distPath);
}
}
|
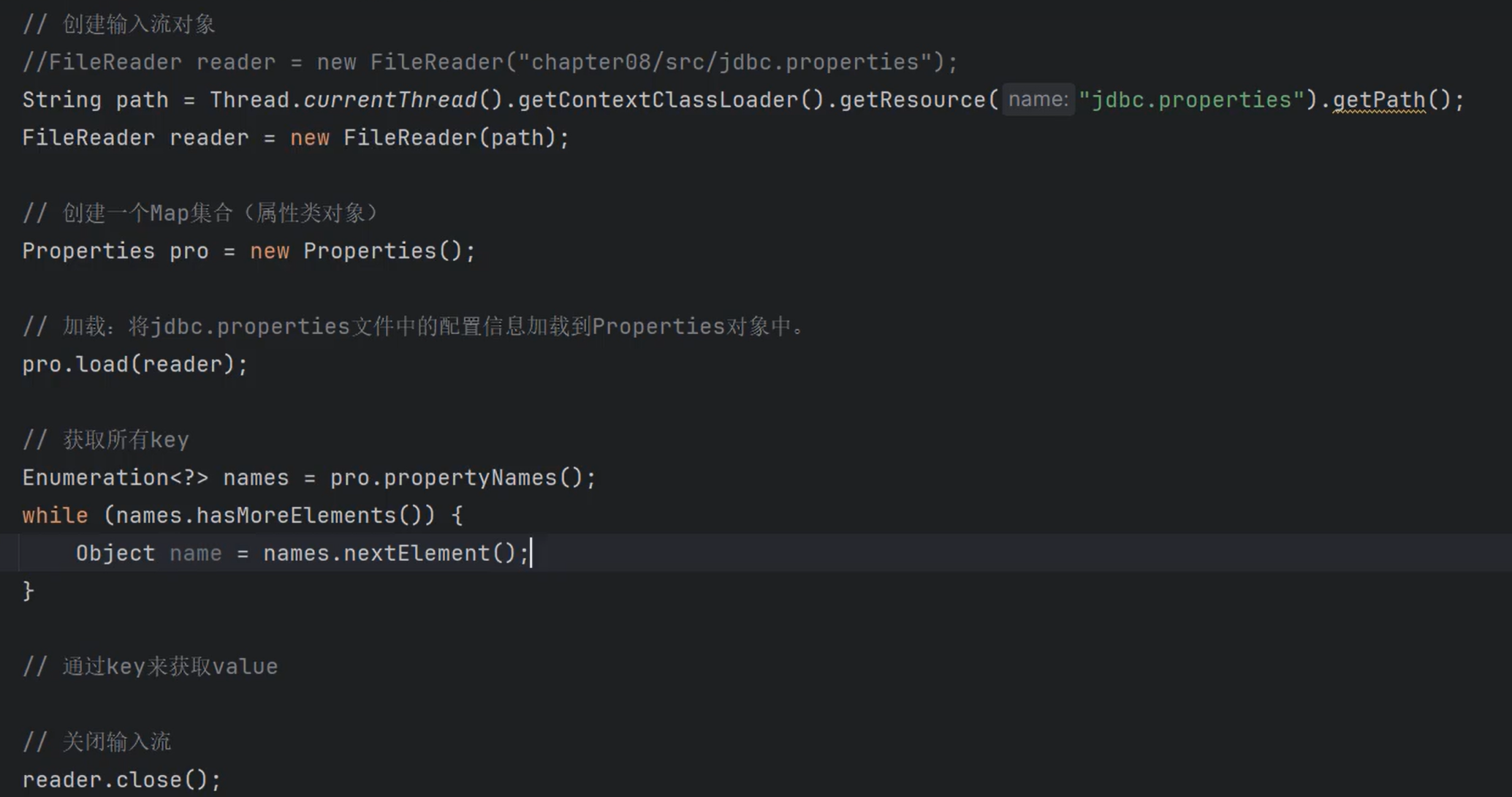
读取属性配置文件
Properties + IO
①xxx.properties文件称为属性配置文件。
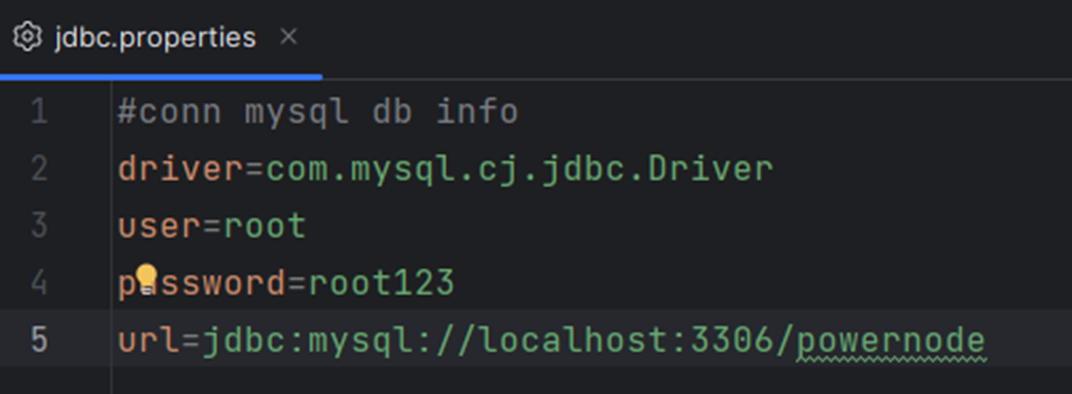
②属性配置文件可以配置一些简单的信息,例如连接数据库的信息通常配置到属性文件中。这样可以做到在不修改java代码的前提下,切换数据库。
③属性配置文件的格式:
1
2
3
4
5
| key1=value1
key2=value2
key3=value3
|
注意:使用 # 进行注释。key不能重复,key重复则value覆盖。key和value之间用等号分割。等号两边不要有空格。
④Java中如何读取属性配置文件?
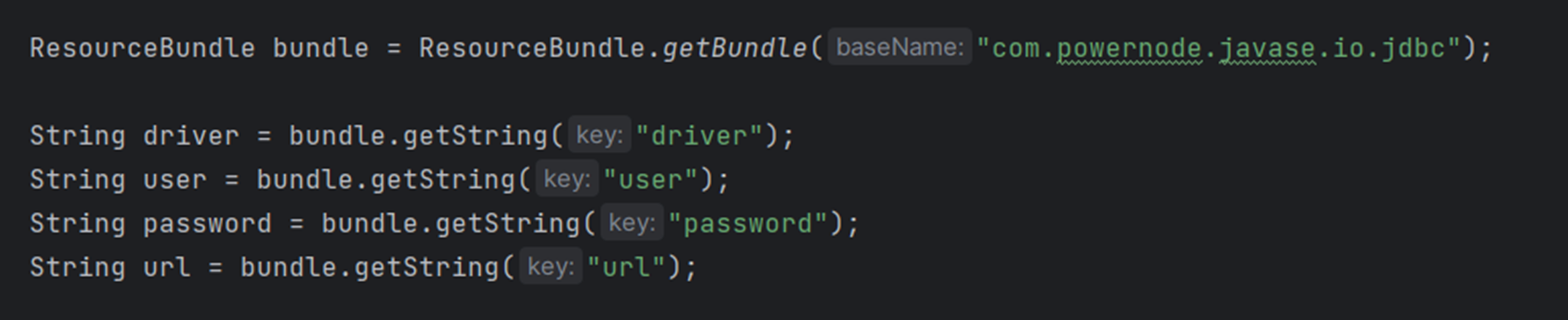
⑤当然,也可以使用Java中的工具类快速获取配置信息:ResourceBundle
这种方式要求文件必须是xxx.properties
属性配置文件必须放在类路径当中\
装饰器设计模式(Decorator Pattern)
①思考:如何扩展一个类的功能?继承确实也可以扩展对象的功能,但是接口下的实现类很多,每一个子类都需要提供一个子类。就需要编写大量的子类来重写父类的方法。会导致子类数量至少翻倍,会导致类爆炸问题。
②装饰器设计模式是GoF23种设计模式之一,属于结构型设计模式。(结构型设计模式通常处理对象和类之间的关系,使程序员能够更好地组织代码并更好地利用现有代码。)
③IO流中使用了大量的装饰器设计模式。
④装饰器设计模式作用:装饰器模式可以做到在不修改原有代码的基础之上,完成功能扩展,符合OCP原则。并且避免了使用继承带来的类爆炸问题。
⑤装饰器设计模式中涉及到的角色包括:
①抽象的装饰者
②具体的装饰者1、具体的装饰者2
③被装饰者
④装饰者和被装饰者的公共接口/公共抽象类
装饰者和被装饰者,应该实现同一个接口/同一些接口,继承同一个抽象类
原因:因为实现了同一个接口之后,对于客户端程序来说,使用装饰者的时候就像是使用被装饰者一样
在松耦合的前提下完成功能的扩展
装饰者含有被装饰者的引用
压缩和解压缩流
①使用GZIPOutputStream可以将文件制作为压缩文件,压缩文件的格式为 .gz 格式。
②核心代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| 1.FileInputStream fis = new FileInputStream("d:/test.txt"); // 被压缩的文件:test.txt
2.GZIPOutputStream gzos = new GZIPOutputStream(new FileOutputStream("d:/test.txt.gz")) // 压缩后的文件
3.接下来就是边读边写:
int length;
while ((length = fis.read(buffer)) > 0) {
gzos.write(buffer, 0, length);
}
4.gzos.finish(); // 在压缩完所有数据之后调用finish()方法,以确保所有未压缩的数据都被刷新到输出流中,并生成必要的 Gzip 结束标记,标志着压缩数据的结束
|
③注意(补充):实际上所有的输出流中,只有带有缓冲区的流才需要手动刷新,节点流是不需要手动刷新的,节点流在关闭的时候会自动刷新。
字节数组流
①ByteArrayInputStream和ByteArrayOutputStream都是内存操作流,不需要打开和关闭文件等操作。这些流是非常常用的,可以将它们看作开发中的常用工具,能够方便地读写字节数组、图像数据等内存中的数据。
②ByteArrayInputStream和ByteArrayOutputStream都是节点流。
③ByteArrayOutputStream,将数据写入到内存中的字节数组当中。
④ByteArrayInputStream,读取内存中某个字节数组中的数据。
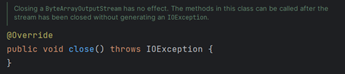
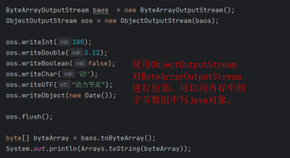
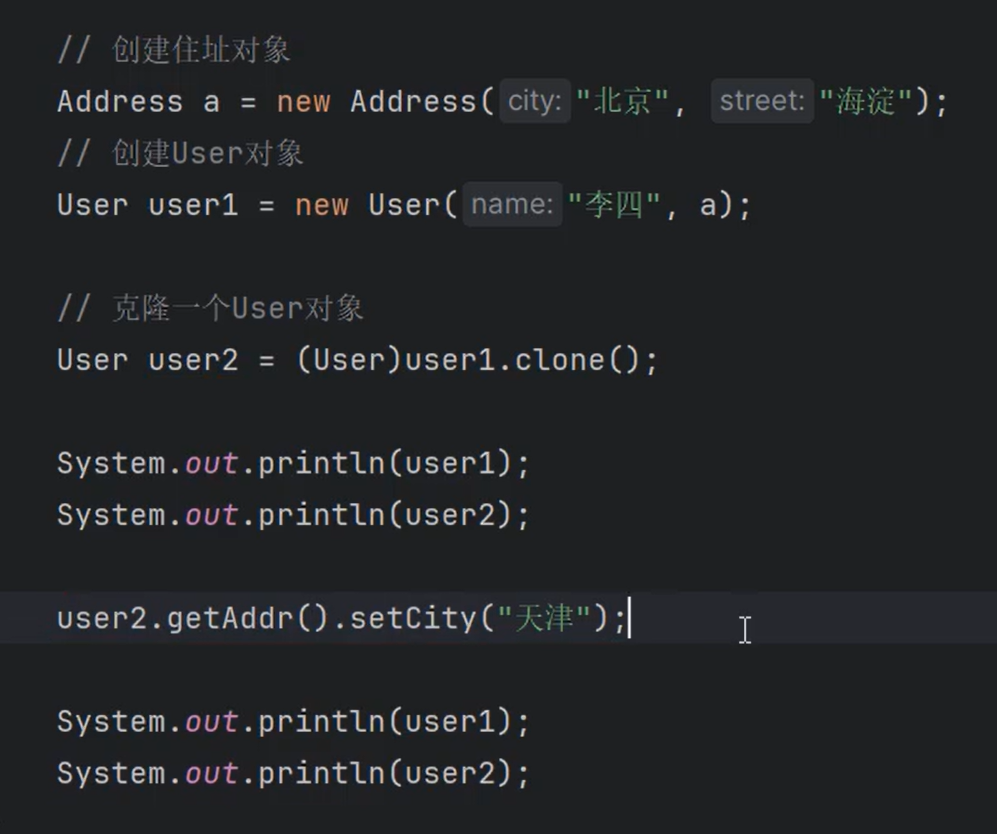
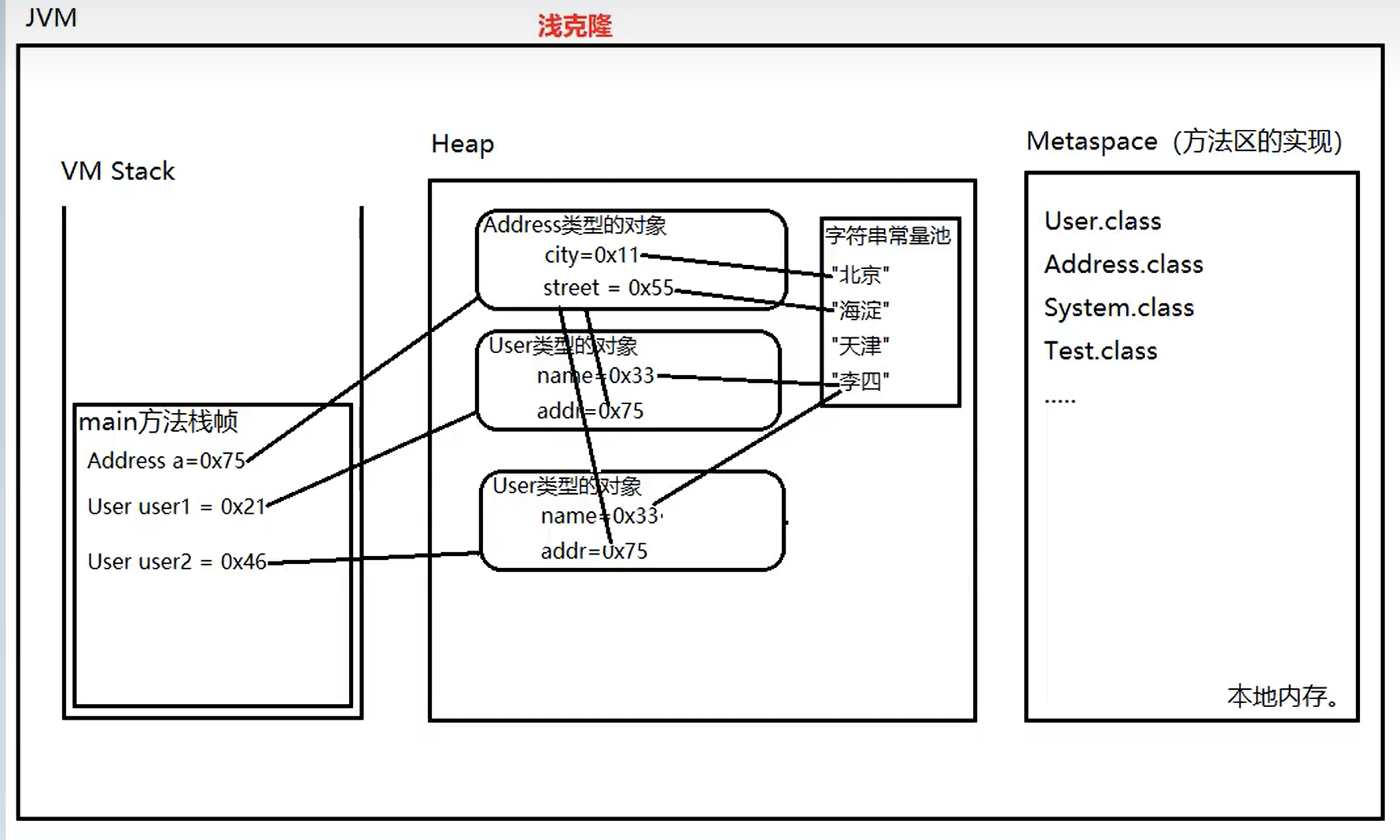
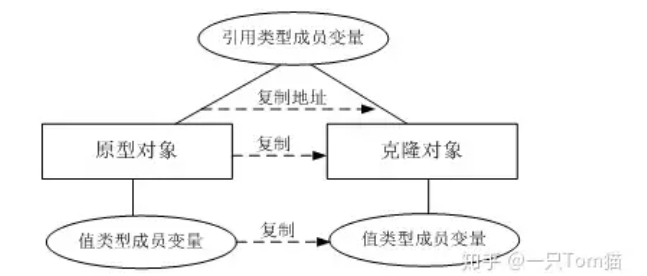
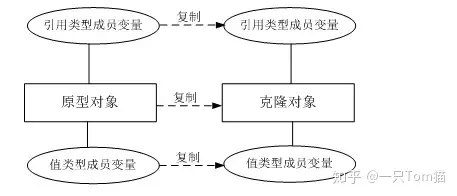
对象克隆
对象的深克隆
①除了我们之前所讲的深克隆方式(之前的深克隆是重写clone()方法)。使用字节数组流也可以完成对象的深克隆。
②原理是:将要克隆的Java对象写到内存中的字节数组中,再从内存中的字节数组中读取对象,读取到的对象就是一个深克隆。
③目前为止,对象拷贝方式:
①调用Object的clone方法,默认是浅克隆,需要深克隆的话,就需要重写clone方法。
②可以通过序列化和反序列化完成对象的克隆。
③也可以通过ByteArrayInputStream和ByteArrayOutputStream完成深克隆。



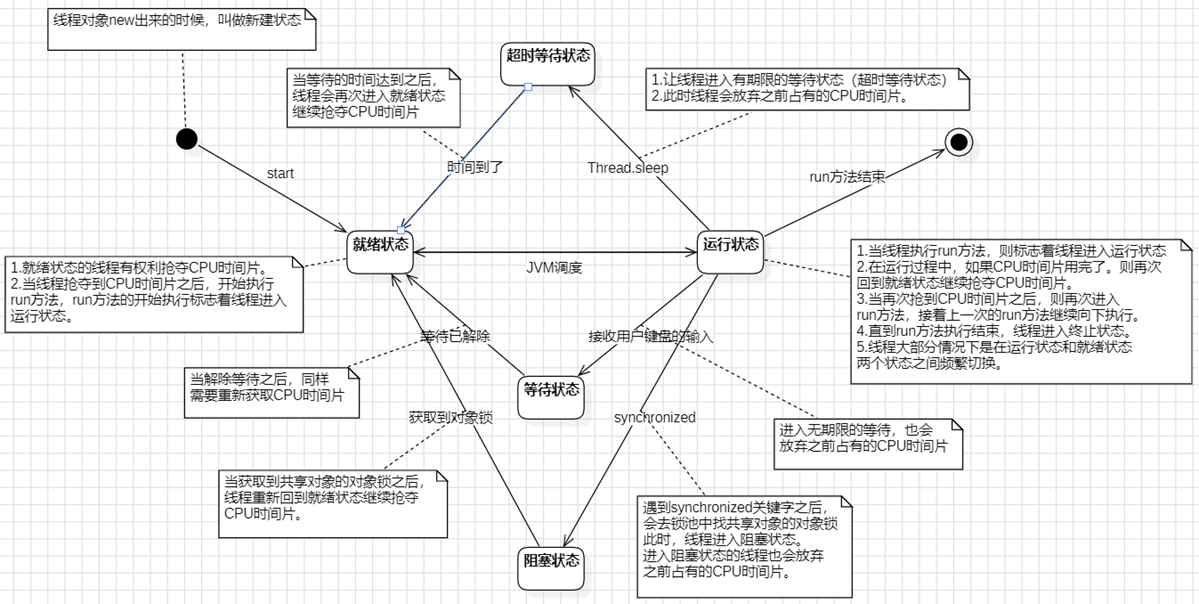
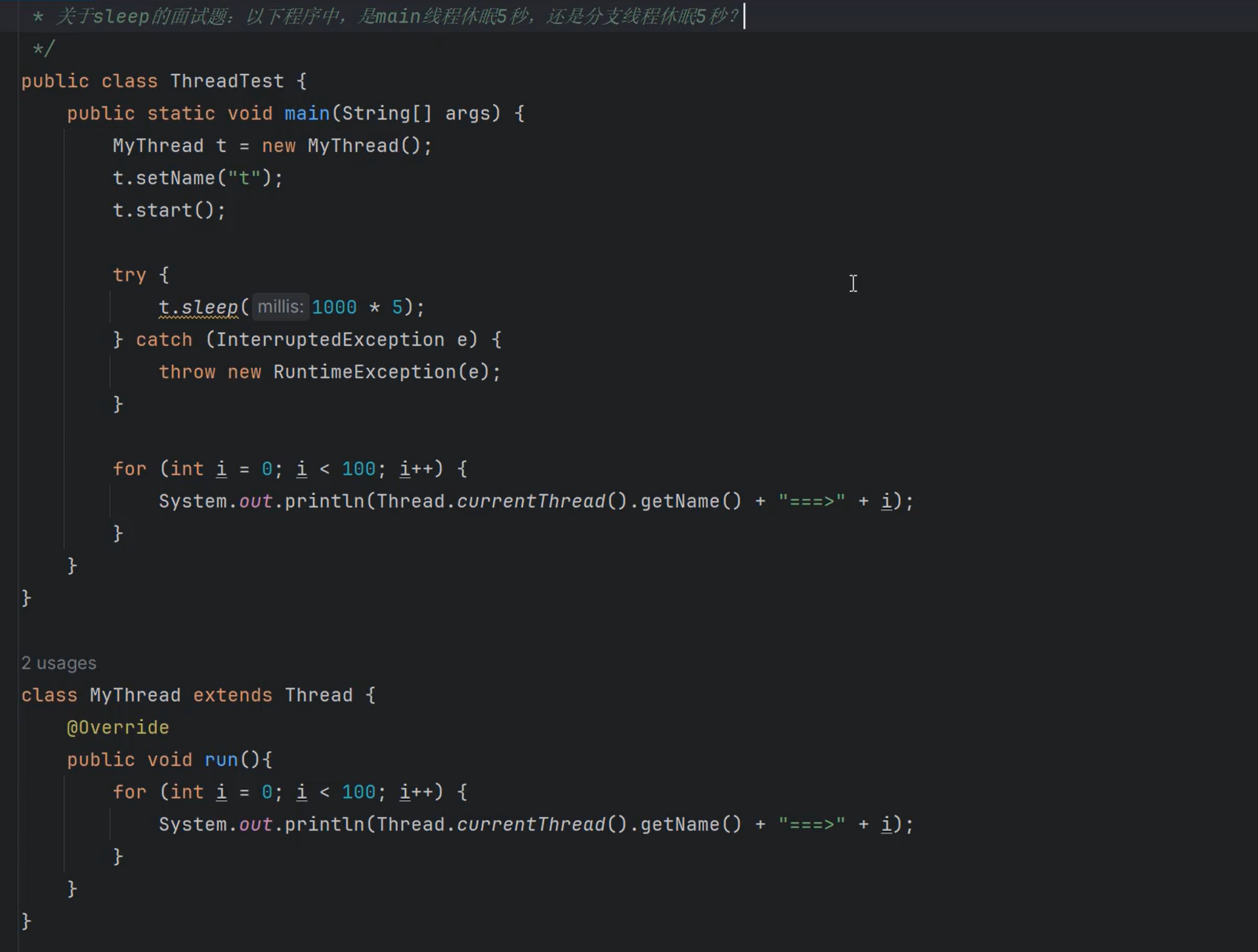
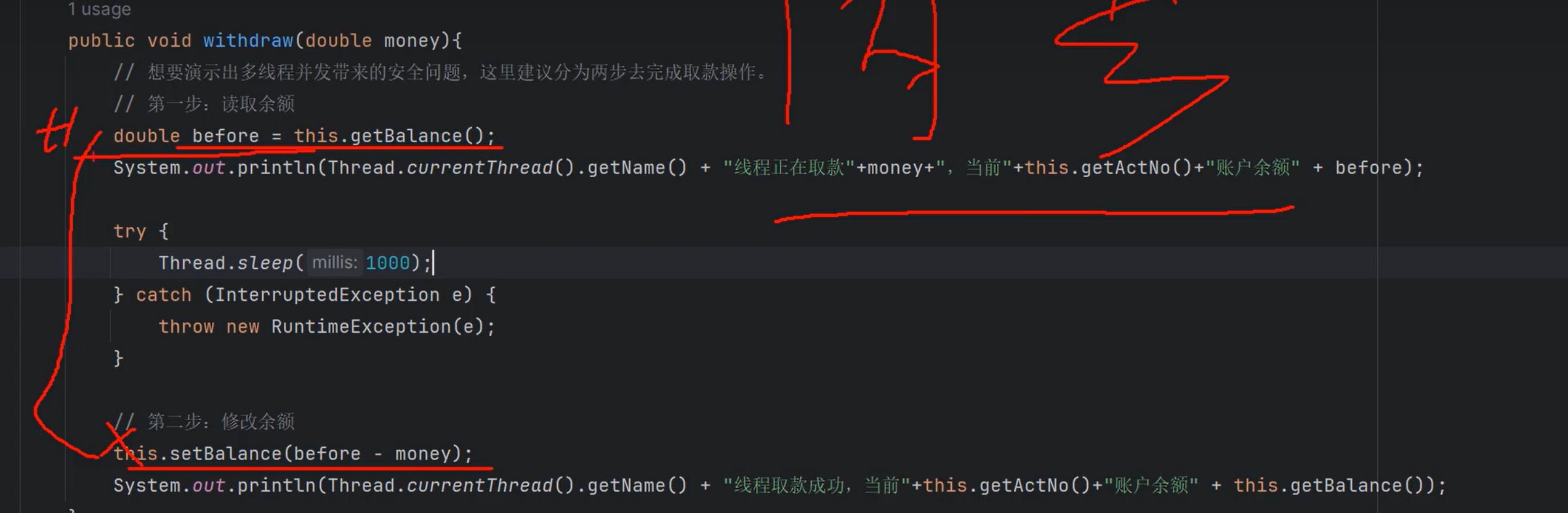
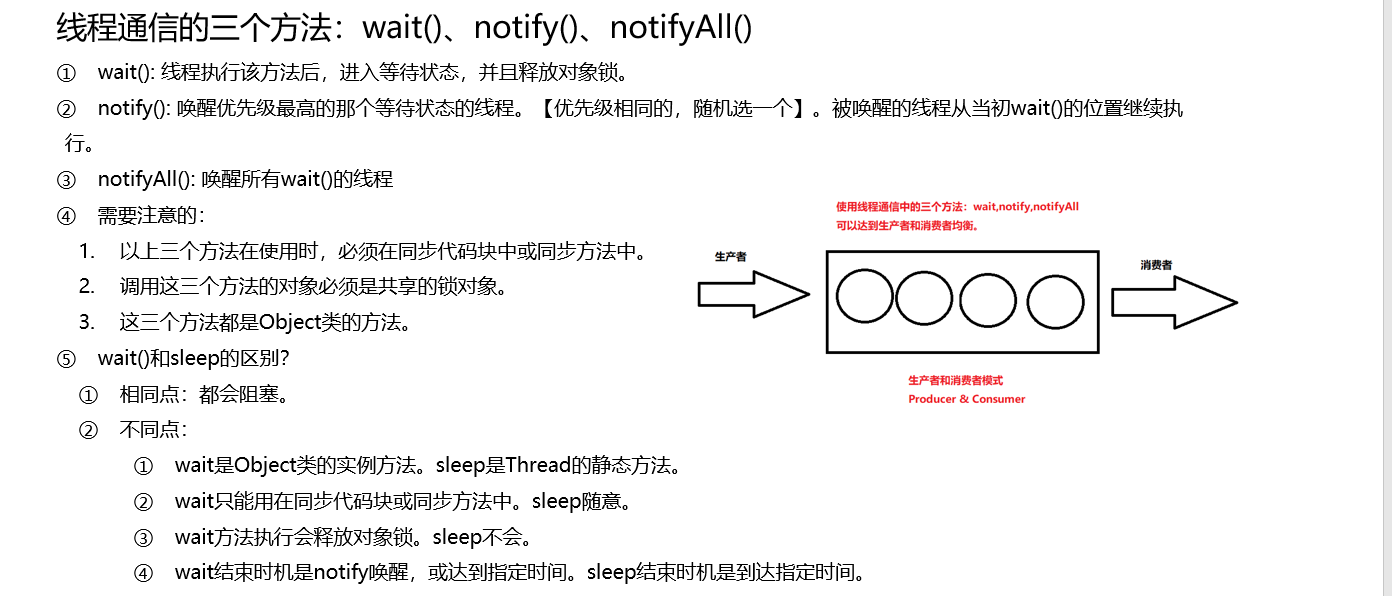


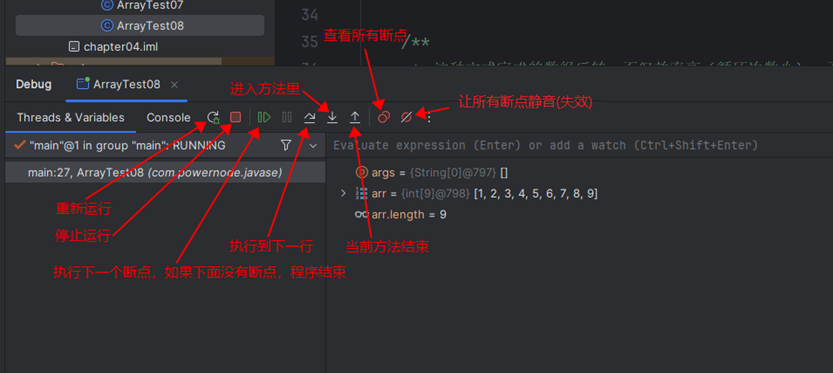
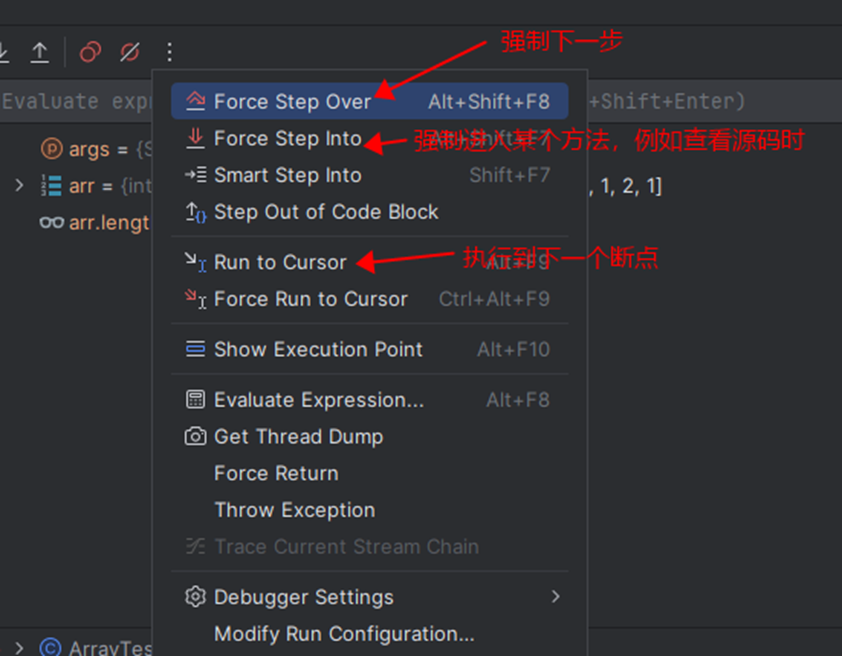
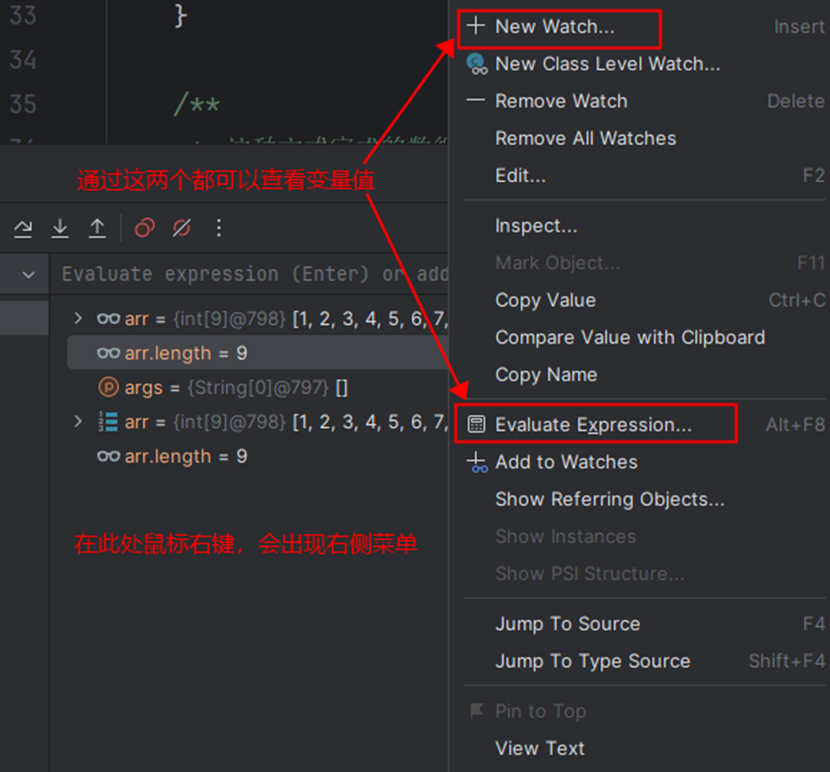
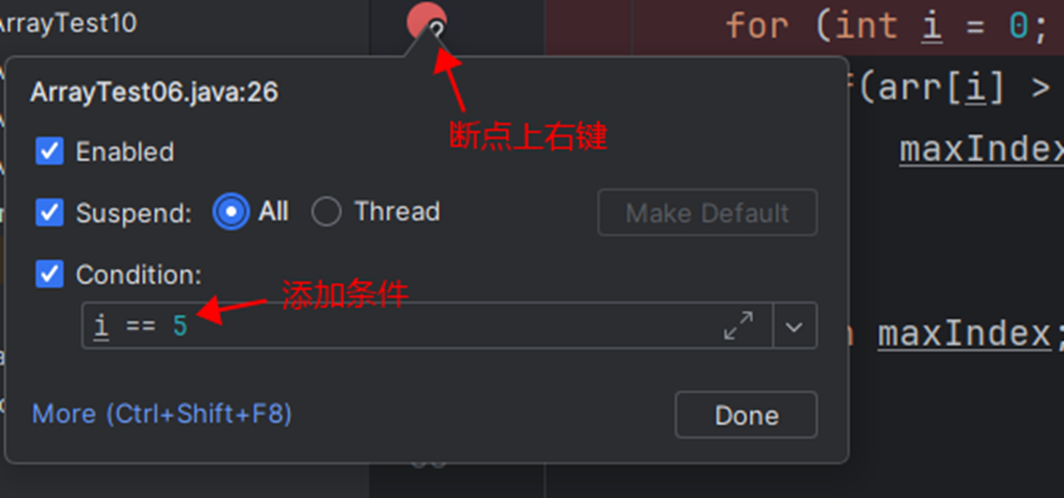

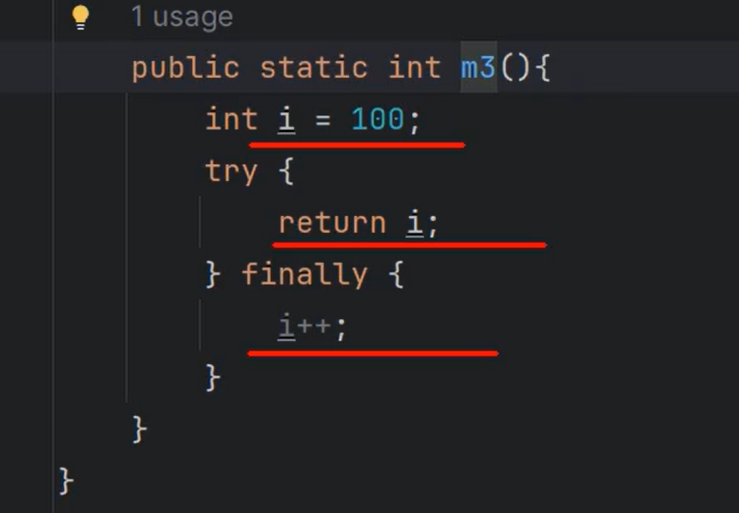

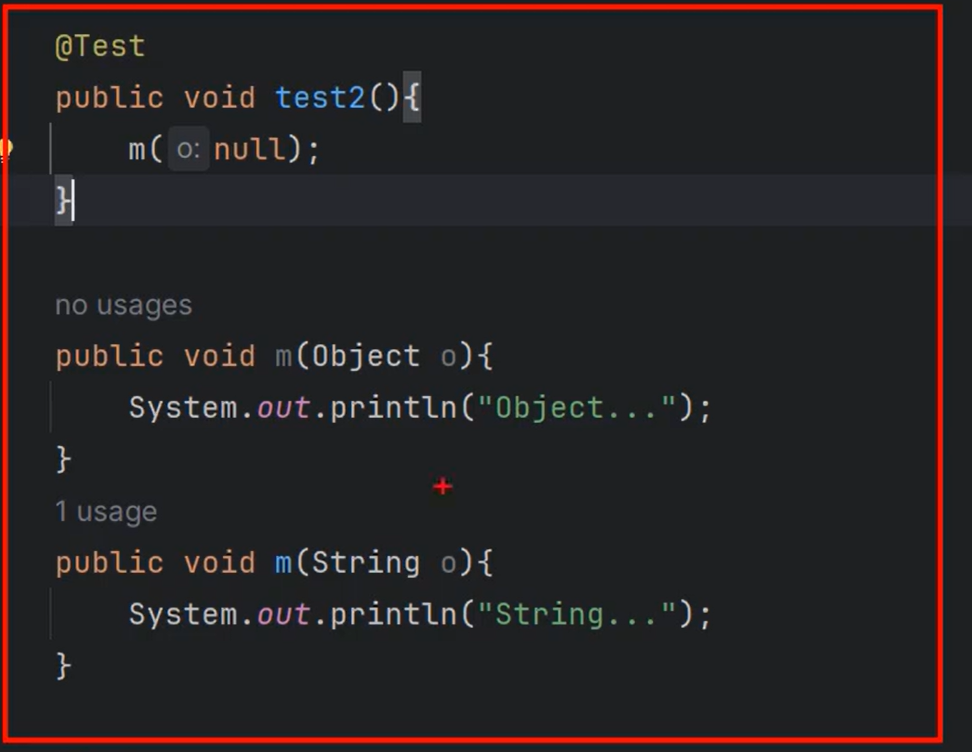

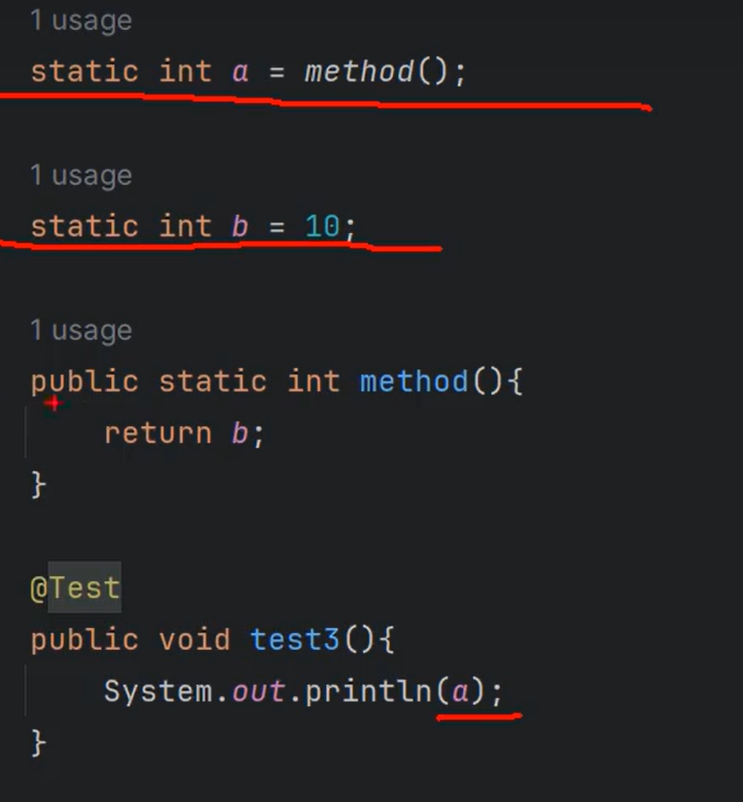
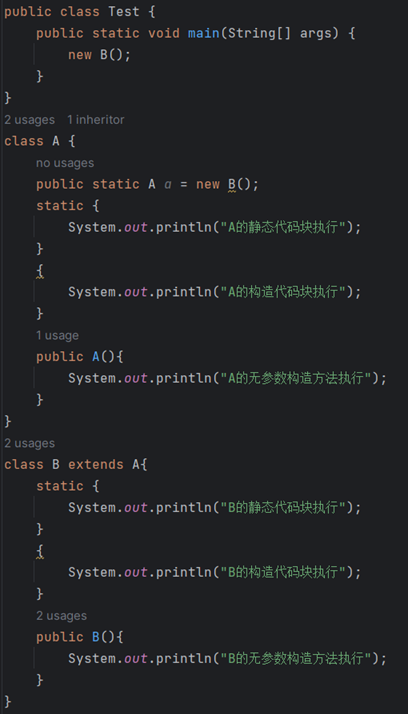





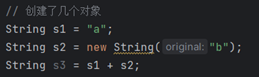

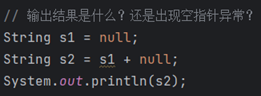
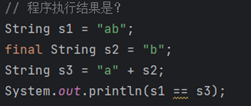



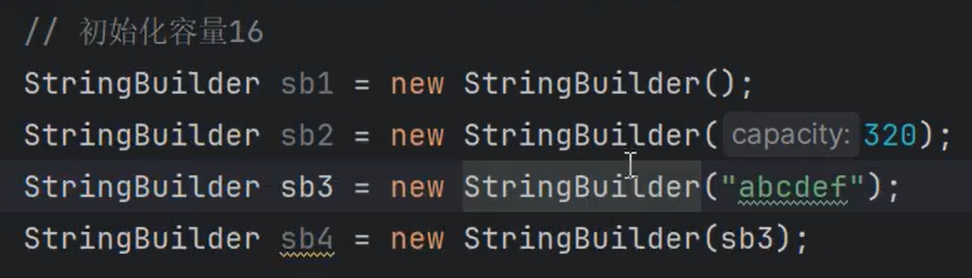



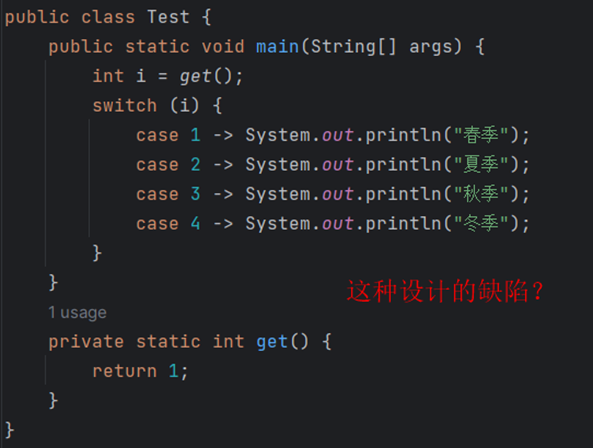
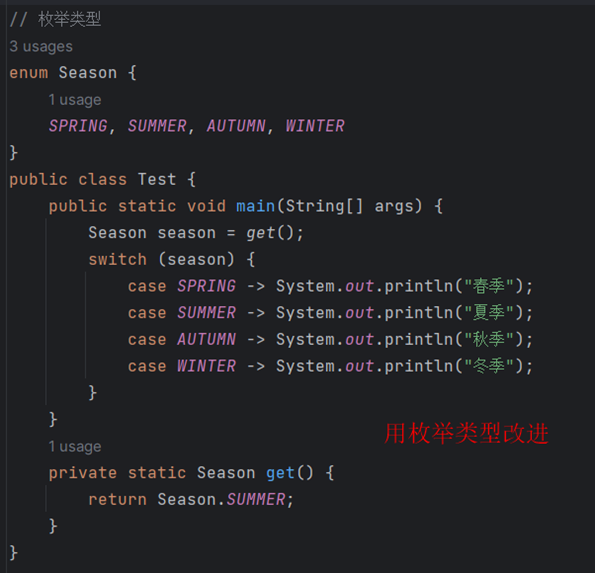



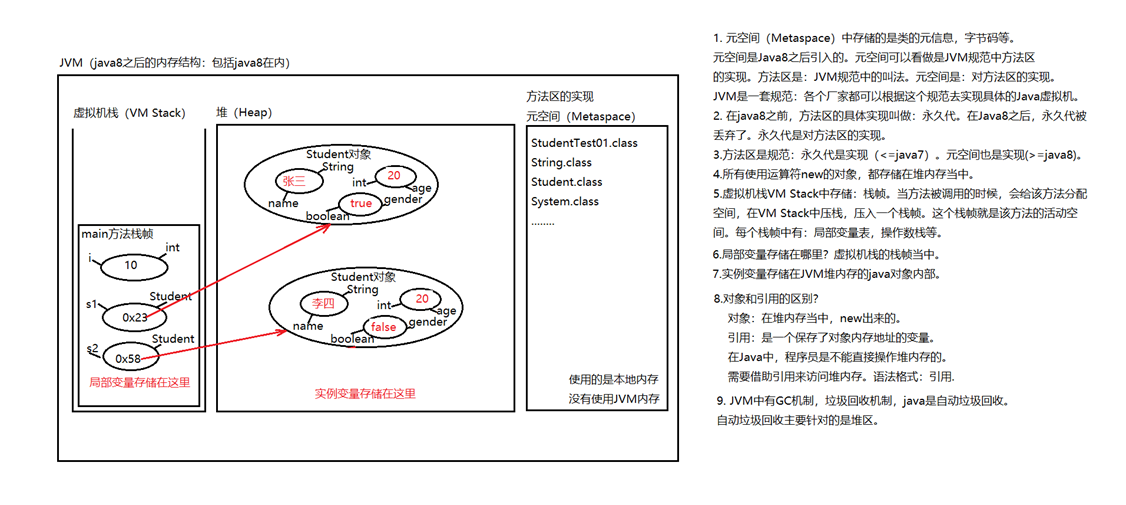




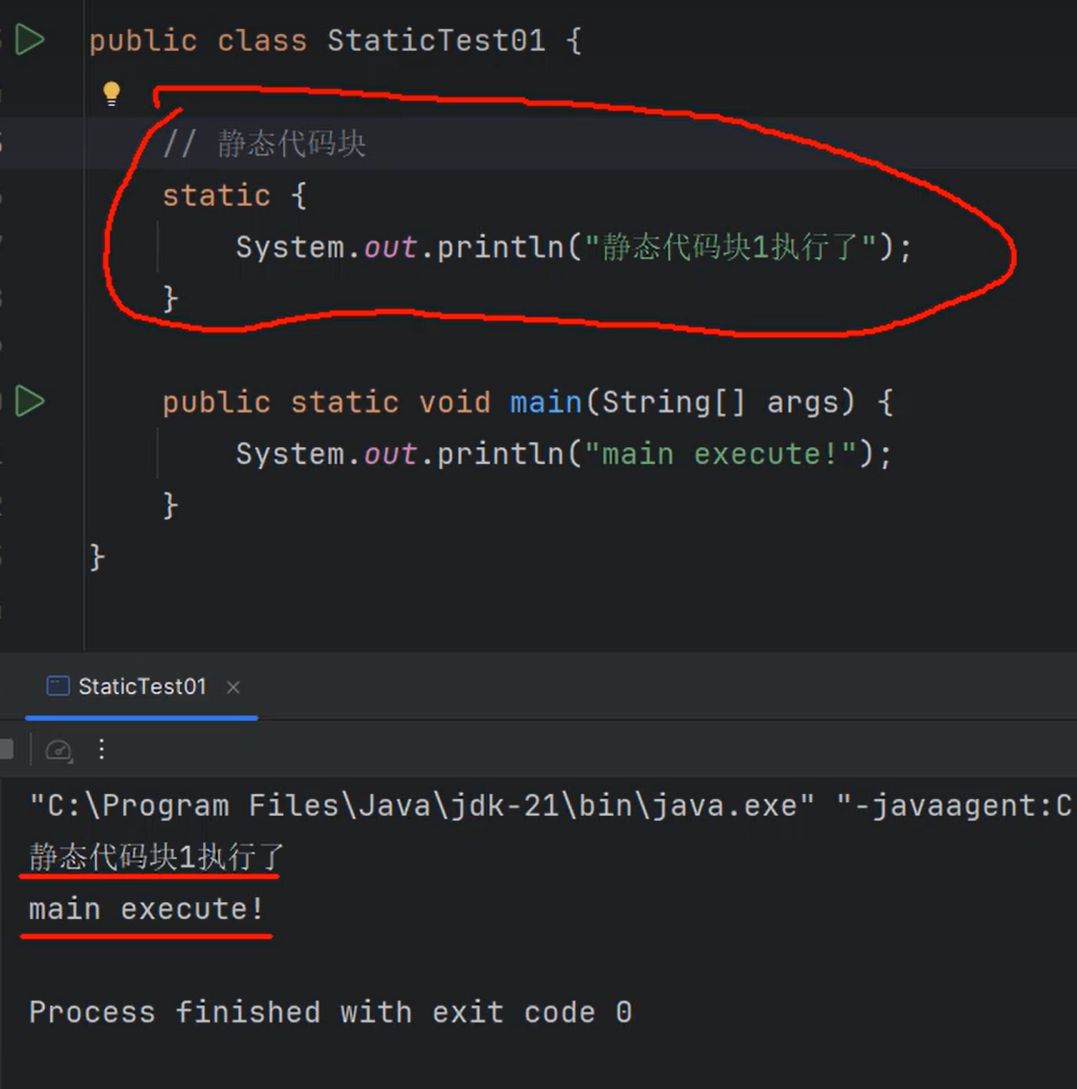
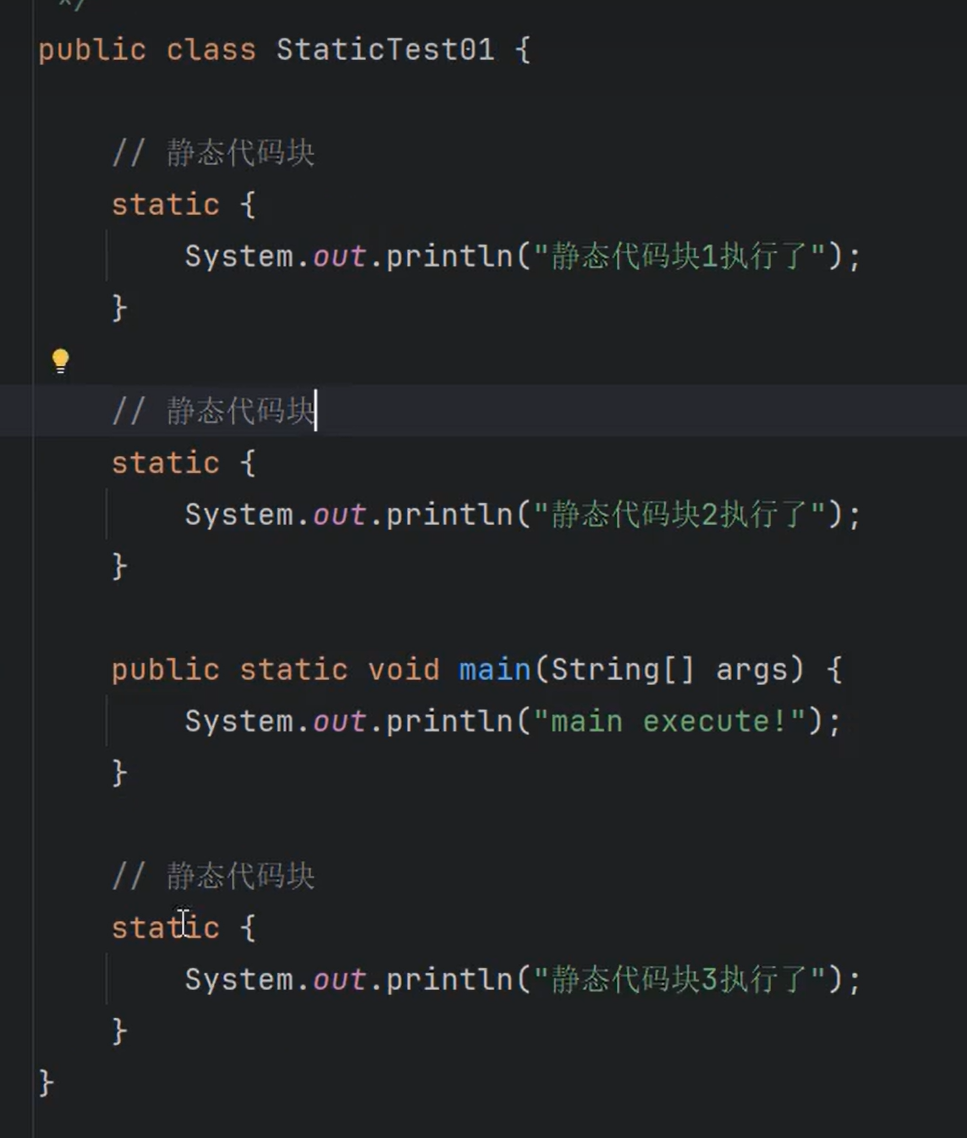
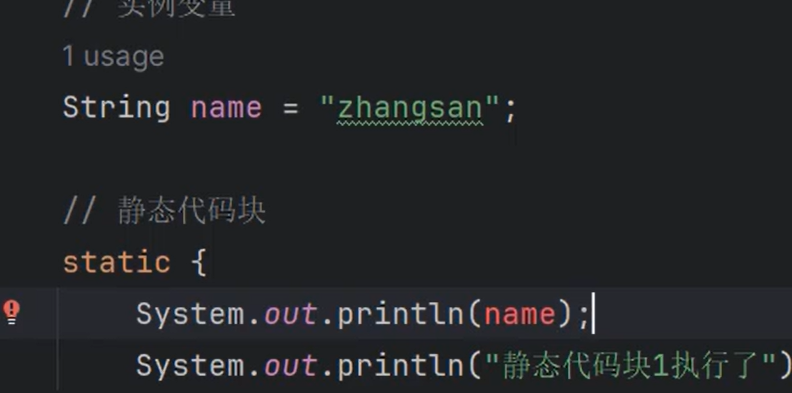




 ⑩JDK9之后允许接口中定义私有private的实例方法(为默认方法服务的)和私有的静态方法(为静态方法服务的)。
⑩JDK9之后允许接口中定义私有private的实例方法(为默认方法服务的)和私有的静态方法(为静态方法服务的)。